
Prometheus가 뭔지 알아보고 Prometheus를 설치해보도록 합시다.
Prometheus란
Prometheus는 회사 등에서 쿠버네티스의 모니터링 시스템으로 사용하는 도구입니다.
Prometheus는 SoundCloud사에서 만든 오픈소스 모니터링 툴로 go언어로 만들어졌으며, 지금은 독립된 오픈소스 프로젝트로 개발되고 있습니다.
쿠버네티스 환경에서 모니터링 하기 원하는 리소스로부터 metric을 수집하고 해당 매트릭으로 모니터링하는 기능을 제공합니다.
또한 수집 중 이상 징후가 발생 시 slack 및 도구를 통해 webhook을 걸어 알림을 주는 기능 또한 제공해주고 있습니다.
Prometheus 특징
1. 시계열 데이터 모델
Prometheus는 key-value쌍으로 이루어진 메트릭을 수집하여 유저에게 시계열 데이터를 제공합니다.
(시계열 : 시간 단위 형식의 데이터)
Prometheus에선 이러한 시계열 데이터를 고유하게 식별하기 위해 metric name과 label로 불리는 key-value를 사용합니다.
api_http_requests_total{method="POST", handler="/messages"}- key: api_http_requests_total은 metric name
- value: method="POST"나 handler="/messages"는 label
2. PromQL
수집된 매트릭을 prometheus는 PromQL이라는 자체 쿼리 언어를 통해 유연하게 가공합니다.
PromQL은 prometheus가 제공하는 자체 쿼리언어로 문법이 쉽고 간결합니다.
3. 단일 노드
prometheus는 분산 스토리지를 사용하지 않고 단일 노드를 사용하여 수집한 매트릭을 저장합니다.
기본 15일을 저장하는데 수정할 수 있습니다.
4. Pull 방식
prometheus는 특이하게 다른 모니터링 툴과는 다르게 pull 방식을 이용합니다.
pull 방식이란 매트릭을 직접적으로 수집하는 exporter에 prometheus가 직접 접속하여 수집한 메트릭을 가지고 오는 방식입니다.
반대로 push 방식이란 메트릭을 수집하는 client가 서버에 메트릭을 전송하는 방식입니다.
prometheus의 장단점
장점
pull 방식을 사용하게되면 모든 메트릭의 정보를 중앙 서버로 보내지 않아도 되기 때문에 부하가 높은 상황에선 fail point를 비교적 예방할 수 있습니다.
단점
plain prometheus를 사용하는 경우 단일 노드 구조를 가지고 있기 때문에 수집해야할 metric 정보와 rule이 많아질수록 configuration이 복잡해지고 scale out이 어렵습니다.
공식문서에서는 이런경우 prometheus를 hierarchy 구조를 만들어 사용하라고 가이드하고 있지만 쉬운 구성방법이 아닙니다..
따라서, kubernetes환경에서 여러 대의 prometheus를 사용해야 하는 상황이라면 prometheus operator와 thanos와 같은 기술들을 고려할 수 있습니다.
Architecture
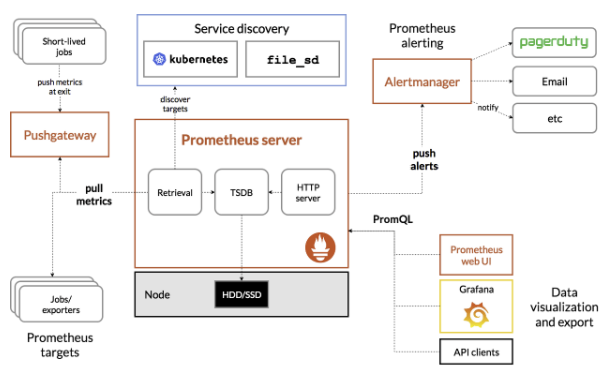
prometheus 구조에서 집중해서 봐야할 부분은 5가지입니다.
1. Exporter
실질적으로 모니터링 대상으로부터 메트릭을 수집하는 컴포넌트로 데이터를 수집하여 prometheus가 exporter로 metric을 요청했을 때 메트릭을 전송하는 역할을 합니다.
Node-exporter를 예로 들자면, kubernetes 환경에서 운영중인 여러개의 node에 node-exporter가 하나씩 뜨게됩니다. 그리고 해당 node에서 발생하는 metric을 수집하게 됩니다.
Prometheus server는 각 node마다 떠 있는 node-exporter에게 metric을 요청하게 되고 node-exporter는 수집한 metric을 응답해주게 됩니다.
2. prometheus Server
prometheus server는 exporter가 열어둔 http endpoint에 접속하여 exporter가 수집한 metric을 수집하고 prometheus server에 저장하게 됩니다.
이때 저장되는 metric은 분산처리가 되지 않기 때문에 단일 노드에 저장되며, prometheus는 기본적으로 15일이 지난 metric은 삭제하므로 이를 고려하여 적절한 storage용량을 할당해야합니다.
3. Jobs
prometheus server가 HTTP endpoint에 접근하여 모니터링 대상의 metric을 수집해오도록 scrape config에 metric scrape job을 등록할 수 있습니다.
이 때 등록된 job은 targer url에 연결된 instance들에게서 주기적으로 metric을 수집해옵니다.
때론 짧게 실행되고 종료되는 job인 경우엔 prometheus server에서 pull하기 전에 job이 종료될 수 있습니다. 이러한 경우엔 push gateway를 사용하여 metric을 push할 수도 있습니다.
4. Alertmanager
prometheus에선 알림이 발생하는 rule을 정의해서 해당 조건에 부합할 경우 알림을 발생기킬 수 있습니다.
5. Grafana
prometheus ul만으로도 많은 시각화를 제공하지만, grafana와 같은 오픈소스 시각화 툴을 이용하면 더 다양한 시각화 기능을 사용할 수 있습니다.
grafana에선 PromQL을 이용해서 prometheus에서 시각화할 metric을 선택적으로 request하고 이를 시각화합니다.
{kind=link}
