Feature engineering이란
Feature Engineering은 모델 정확도를 높이기 위해서 주어진 데이터를 예측 모델의 문제를 잘 표현할 수 있는 features로 변형시키는 과정으로'머신러닝 알고리즘을 작동하기 위해 데이터의 도메인 지식을 활용해 feature를 만드는 과정'이다.
Feature engineering 종류
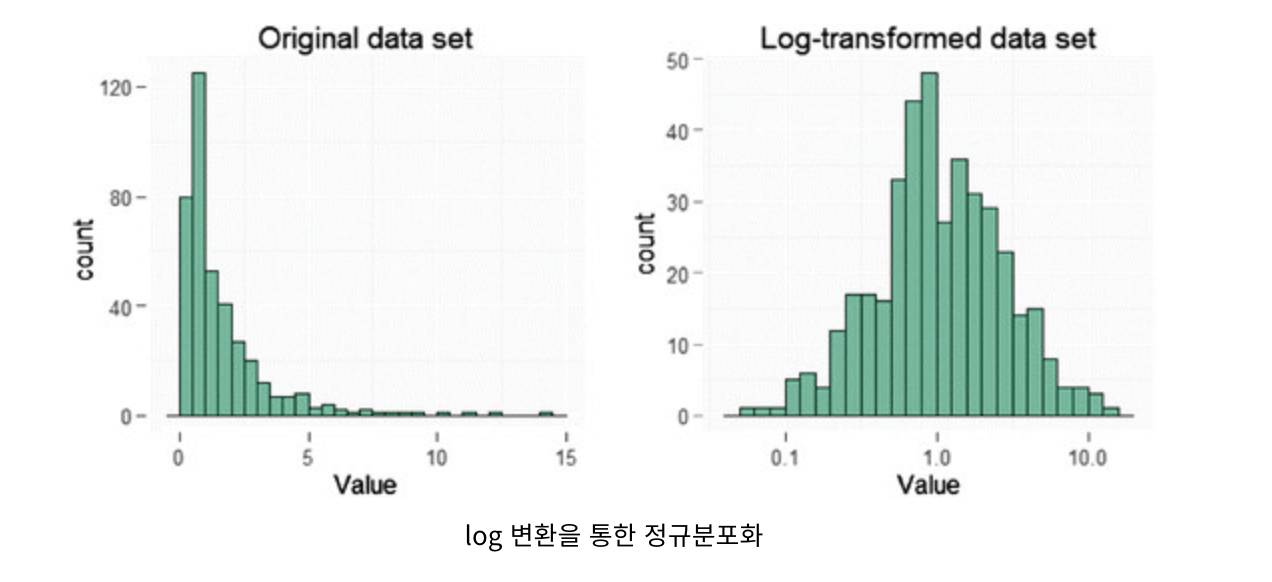
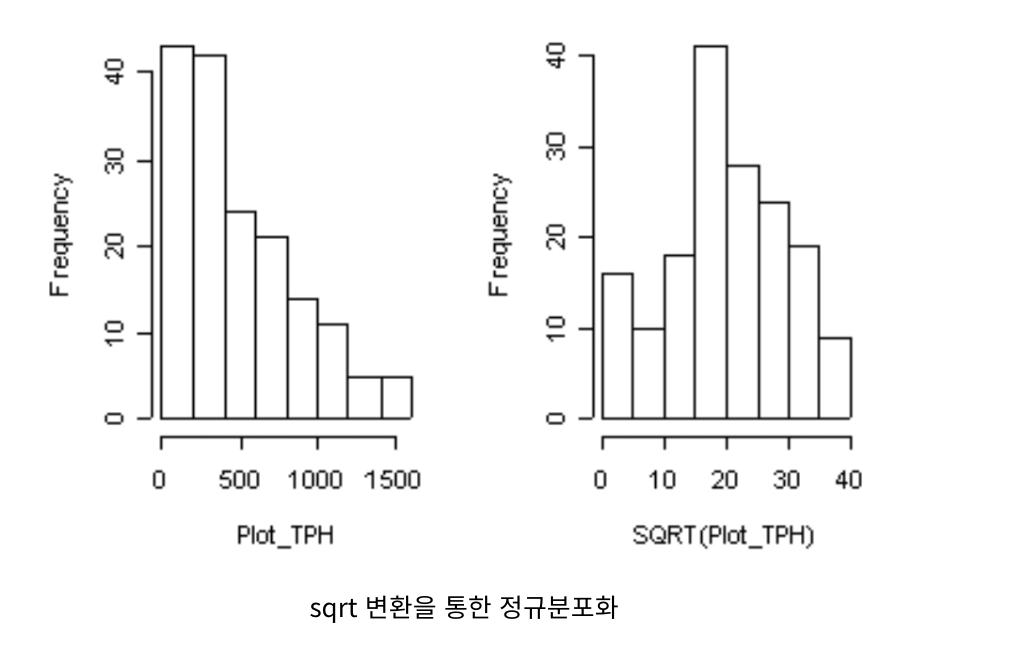
1. 정규분포화
대부분의 통계기법은 데이터의 분포가 정규분포인 가정에서 만들어진게 대부분이다.
따라서, 특정 데이터의 분포가 정규분포가 아니라면 정규분포화 시켜주어야하는 작업이 필수적이다.
정규분포를 만드는 방법은 log 변환하거나 sqrt 변환하여 가능하다.
2. 이상치 제거
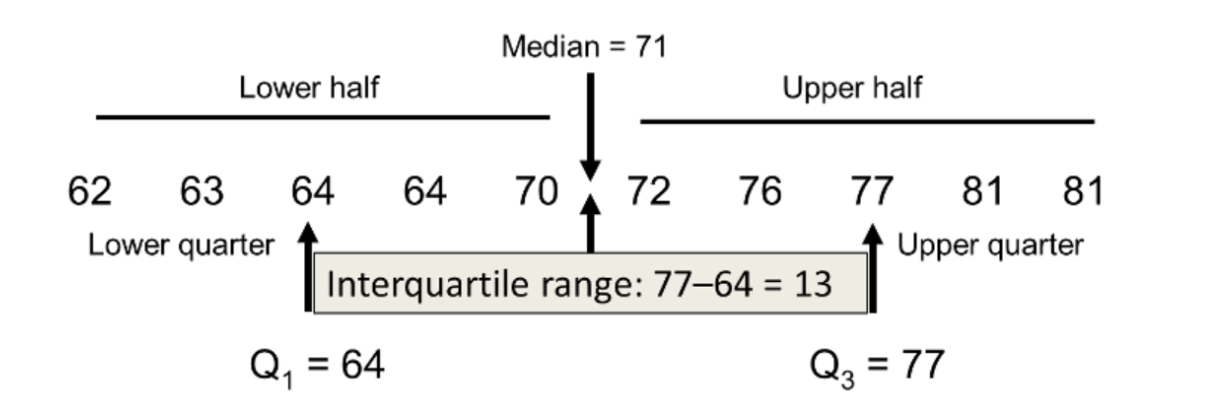
이상치는 극단적인 값을 말하는데 함부러 삭제하는 건 안되지만 무의미하고 분석에 악영향을 준다면 삭제하고 분석을 하는 것이 맞다.
보통 범위를 설정하기 위해 IQR을 사용하는데 제 3사분위수에서 제 1사분위수의 값을 제거한다.
3. Scailing
대부분의 데이터가 범위들이 다르고 단위가 다릅니다. 단위가 다르면 직접적 비교가 불가능합니다. 가령 사람의 키와 몸무게는 직접 비교할 수 없죠..? 즉 이런경우를 해결하기 위해 scailing을 진행합니다.
그것이 바로 normaliaztion과 Standardization입니다.
정규화와 표준화가 해주는 것은 특성 스케일링과 데이터 스케일링이라고 부릅니다.
정규화 vs 표준화
- Normalization
데이터를 0과 1사이의 값으로 변환하여 이상치의 영향력이 커지므로 정규화 후 이상치를 다루는 것이 좋다.
- Standardization
값들이 정규분포를 따른다고 가정하고 값들을 0의 평균 1의 표준편차를 갖도록 변화해주는 것입니다.
표준화를 해주면 정규화처럼 특성값의 범위가 0~1 사이로 균일하게 바뀌지는 않습니다.
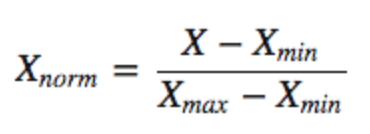

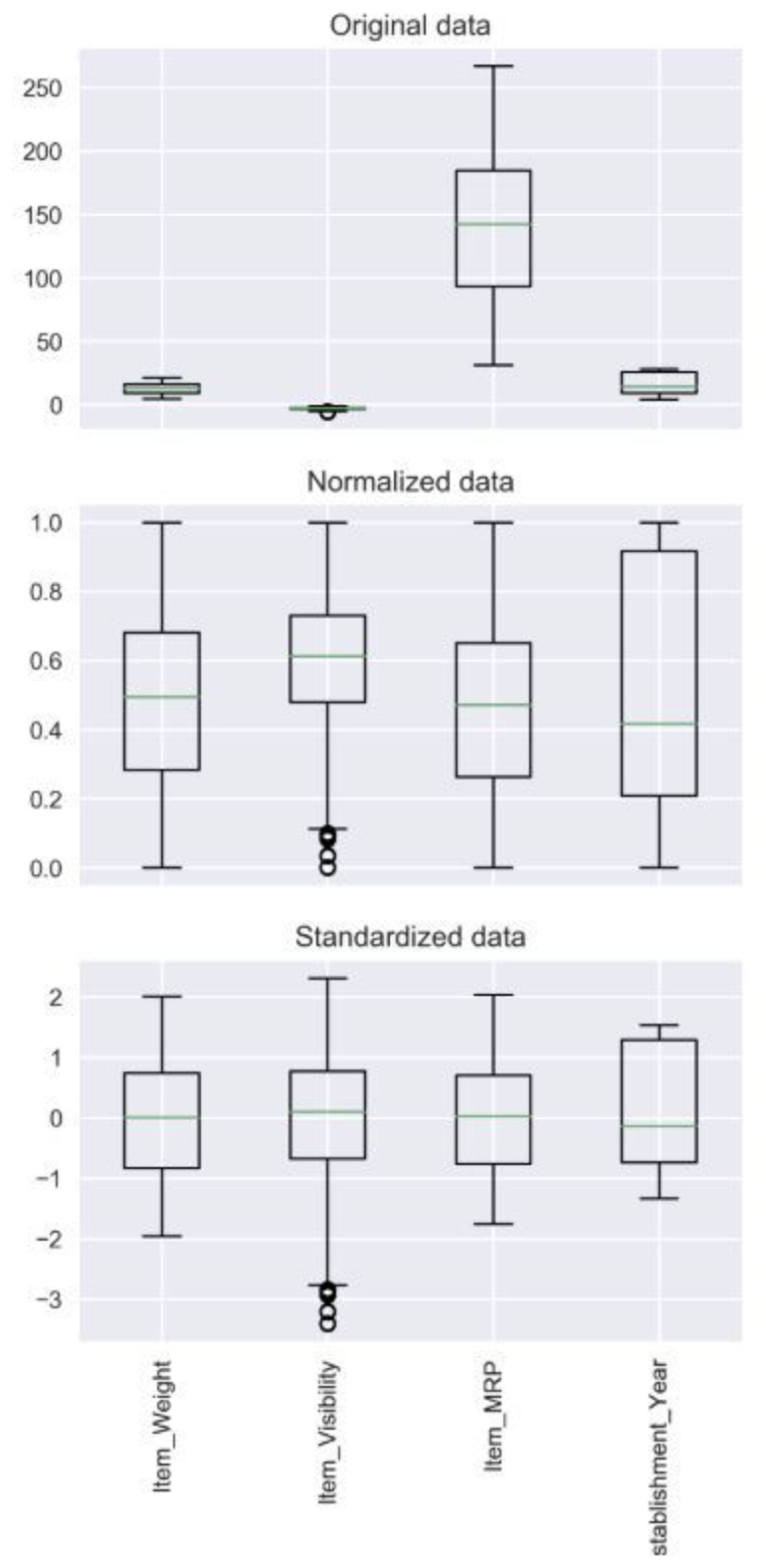
정규화 표준화 무엇이 더 나은가?
단적으로 무엇이 더 낫다는 것은 없고 상황에 따라 다릅니다.
따라서 둘 다 진행해보고 어느 것이 더 나은지 비교 후 적용해야합니다.
4. Imbalanced Data
Imbalanced Data한 데이터로 모델을 학습할 경우 모델이 제대로 학습될 수가 없습니다...
대게 많이 있는 클래스의 데이터에 대해서 과하게 학습하게 되므로 대게 오버피팅이 발생하게 됩니다.
따라서, Imbalanced Data 인경우 다른 대안을 마련해야하는데요.
하나씩 확인해 봅시다.
-
적절한 평가지표 사용하기
우선 이렇게 Imbalanced Data한 데이터의 평가지표로 정확도를 사용하면 많은 클래스의 정확도에서만 높은 정확도를 보이므로 부적절합니다.
따라서 대체 가능한 다른 평가지표를 사용하는 것이 좋습니다.Precision/Specificity, Recall/Sensitivity, F1 score, MCC, AUC
해당 평가지표들에 대하서는 여기에 잘 정리해두었습니다. 도움되세용 ㅎㅎ -
Under-Sampling
balanced dataset으로 resampling하여 balance하게 만드는 것입니다.
그중 under-sampling은 abundant class의 사이즈를 줄여서 balanced dataset으로 만드는것이며 이 방법은 데이터의 양이 충분할때 사용할 수 있습니다.
rare class의 모든 샘플을 keeping하고, abudant class의 샘플들의 숫자를 랜덤으로 선택해서 숫자를 같게 만드는 방법이다.
TomekLinks
이 논문이 나오기 전에는 제거하려는 다수 클래스에서 k-nearest neighbors에 있는 샘플만 무작위로 선택하여 제거했었다. 하지만 Tomek 이란 사람이 소수 클래스 데이터와 가장 낮은 유클리디안 거리를 갖는 다수 클래스를 삭제하여 두 클래스 사이의 공간을 늘렸고 분류 프로세스를 용이하게 했다. 가장 낮은 유클리디안 거리를 가져 인접한 인자의 한 쌍이지만 서로 다른 클래스들을 Tomek links 라고 부른다.
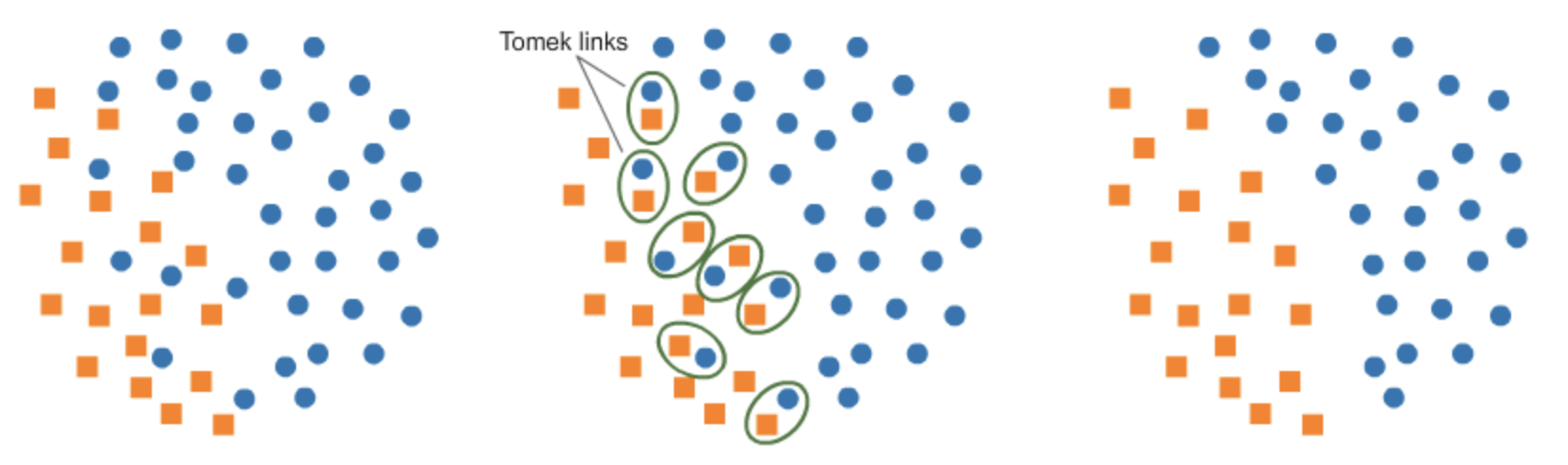
아래에서 볼 수 있듯이 balnced로 변형한 데이터셋의 점수가 더 높은 것을 볼 수 있습니다.

- Over-Sampling
데이터의 양이 충분하지 않을때 사용하는 방법으로, rare sample의 사이즈를 증가시켜 balanced dataset으로 만드는 것이다.
새로운 rare samples을 생성하기 위해서는 repetition, bootstrapping, SMOTE(Synthetic Minority Over-Sampling Technique)를 사용하면 된다.
SMOTE
Scikit-learn에서 제공하는 SMOTE(Synthetic Minority Over-sampling Technique)는 원본 데이터에 KNN(최근접 이웃 방식)으로 비슷한 Class의 데이터들을 임의로 증식시키는 방법입니다.
# SMOTE(KNN에 기반한 오버샘플링) 적용 후 모델 학습 from imblearn.over_sampling import SMOTE import pandas as pd smote = SMOTE(random_state=42) # train 데이터에서 오버샘플링 시키기 x_train_over, y_train_over = smote.fit_resample(x_train, y_train) # 오버샘플링 적용 후 데이터 레이블 개수 살펴보기 print('오버샘플링 전 :', x_train.shape, y_train.shape) print() print('오버샘플링 후 :', x_train_over.shape, y_train_over.shape) print() print('오버샘플링 전 레이블 분포 :\n', pd.Series(y_train).value_counts()) print() print('오버샘플링 후 레이블 분포 :\n', pd.Series(y_train_over).value_counts())
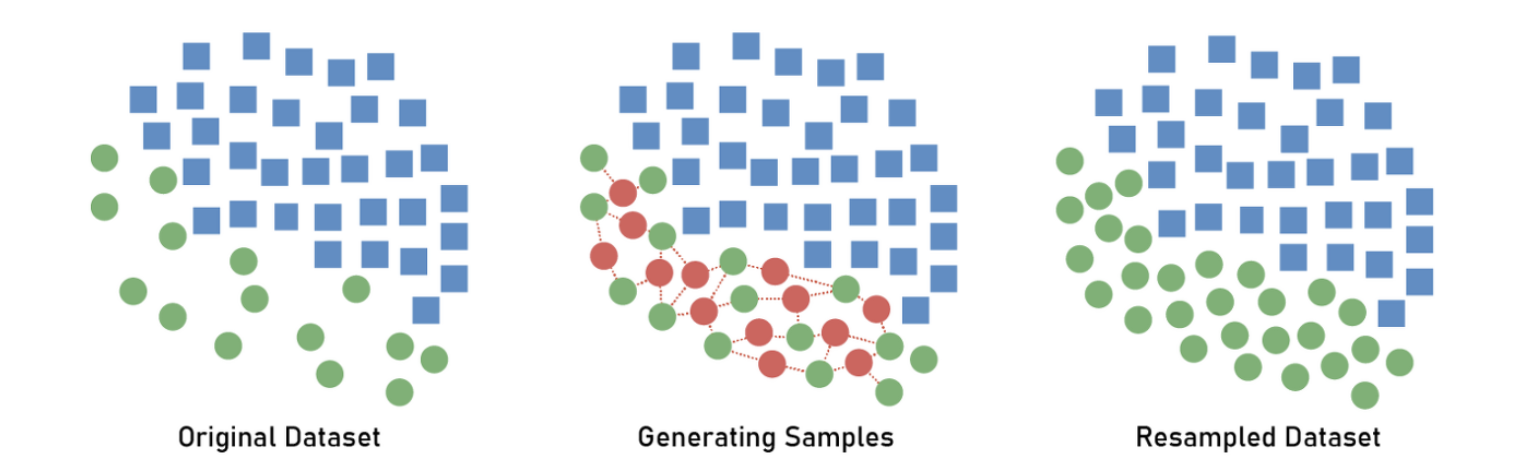

- K-fold Cross-VAlidation
over-sampling을 사용할때 적절한 방법입니다. over-sampling은 rare samples의 distribution function을 기반으로 새로운 random data를 생성하기 위해서 bootstrapping을 적용하는 방식인데 만약 cross-validation이 over-sampling이후에 적용이 되면, 기본적으로 우리가하고 것은 우리의 모델을 특정 artificial bootstrapping 결과에 맞추는 것입니다.
모든 소스는 해당 git에서 확인하실 수 있습니다.
