요즘 회사에서도, 개인적으로도 큰 관심을 가지고 인과추론을 공부하고 업무에도 적용해보고 있습니다. 또, 사내에서 스터디를 통해 같이 학습을 하고 있는데요. 이중차분/단절회귀 등 인과추론 방법을 조금 더 이해하기 위해서는 간단한 통계 개념을 알고 있으면 도움이 될 것 같아, 저도 스스로 정리할 겸 글을 작성해보았습니다.
0. 시작에 앞서, 마인드 셋!
이 글에서는 인과추론을 잘 이해하기 위해 필요한 통계 지식을 최대한 쉽게 설명 해보려고 합니다. 이 자료의 목적은 통계학의 개념들을 모두 다 이해하고 수학적으로 풀이한다기 보다는 인과추론을 이해하기 위한 최소한의 통계 지식들을 살펴보는 것입니다.
먼저, 인과추론 분야에서 주로 사용하는 통계 관련 단어들을 정리 해보았습니다.
변수 / 성과변수 / 더미변수, 처치 (처리), 통제집단, 평균, 분산, 표준 편차, 모분산 / 표본분산, 조건부 평균, p값, 가설 / 가설 검정, 기각 / 채택, 상관관계, 인과관계, 편의 / 선택 편의,모수, 표본, 모집단 / 표본 집단, 대수의 법칙, 중심 극한 정리, 기댓값 , 조건부 확률, 균형 상태 점검, 정규 분포, 표준 오차, 통계적으로 유의하다, 통계량 / 표본 통계량, 추정량 / 불편 추정량, 오차 / 표준 오차 / 표준 오차의 추정치, t 통계량, 귀무 가설 / 대립 가설, 신뢰구간….
(사실 더 많지만..손 아파요..)
인과추론을 공부하려고 했는데, 이걸 다 이해해야 하는 것인가요? 물론 그러면 좋겠지만 저희는 시간의 제약이 존재합니다. 앞으로의 인과추론을 이해하는데 조금이나마 도움이 되실 수 있도록, 여론 조사라는 사례를 통해 일반적으로 통계에서 문제를 정의하는 흐름에 대해 설명 드리도록 하겠습니다.
1. 여론조사 사례로 배우는 통계
1-1. 여론 조사의 목적?
저번 대선이 기억 나시나요? 대통령 선거나 총선을 할 때 꼭 하는 것이 있습니다. 바로 여론조사입니다.
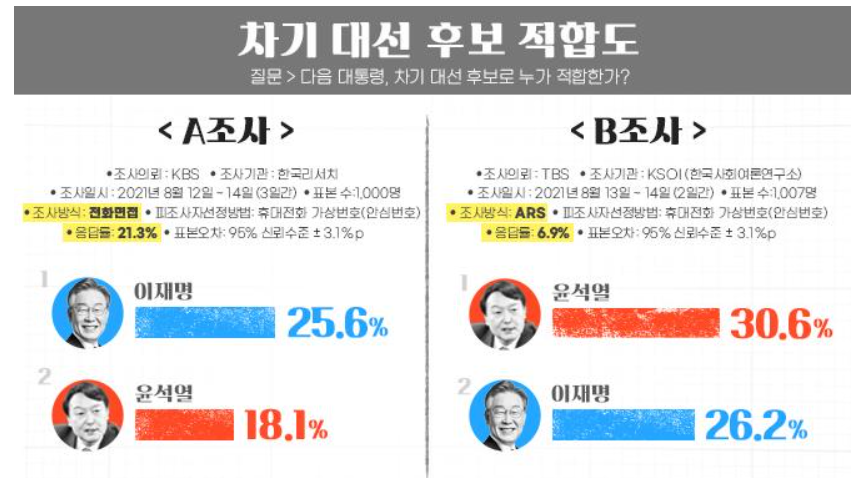
여론 조사를 왜 할까요?
(1) 그냥 선거권을 가진 모든 사람에게 물어보면 되는 것이 아닌가요?
(2) 혹은, 그냥 선거일까지 기다리면 되는 것 아닐까요?
두 질문 모두 맞는 말입니다. 그러나, 현실에는 많은 시공간적 제약이 존재합니다.
첫 번째 질문인 “모두에게 물어보면 안될까요?”는 현실적으로 불가능합니다. 선거권자 모두의 명단을 확보하여 한 명 한 명 물어보는 것은 엄청난 비용이 소모되는 행위일 뿐 아니라, 선거권자의 투표 도장은 조사 도중에도 그 방향이 바뀔 수 있기 때문입니다.
두 번째 질문인, “선거일까지 기다리면 되는 것 아닐까요?는 인간이라면 불가능합니다. 인간은 끊임없이 궁금해 하기 때문입니다. 또한, 대선이라는 큰 이벤트는 얽혀 있는 이해 관계자도 많고 돈도 왔다갔다 하기에 예측이 요구 되는 영역입니다.

여론 조사는 모든 것을 조사할 수 없고, 궁금증을 해결해줄 수 있는 수단으로서 작동합니다.
여론 조사에 사용된 것처럼 통계학은 이런 “시간과 공간의 제약 속에서 효율적인 방법으로 불확실성에 대한 논리를 부여하는 학문이라고 볼 수 있습니다.”
1.2 여론 조사 사례로 배우는 통계 용어
1) 모집단과 표본 집단
이제 여론 조사 과정을 조금 더 들여다보며 몇 가지의 개념과 용어를 설명 드리겠습니다.
여론 조사의 목적이 되는, 확인하고 싶은 전체 집단이 있습니다. 여론 조사에서는 투표권을 가진 전체 인원일텐데요 여기서 전체 집단을 우리는 모집단이라고 부릅니다.
그리고, 모집단을 추정하기 위해 선택된 집단 (여론 조사 인원)을 표본 집단이라고 합니다.
2) 모수와 통계량
우리는, 이런 모집단에서 어떤 정보를 알고 싶어 합니다. 이런, 모집단의 특정 정보를 모수 (parameter)라고 부릅니다. 예를 들면, 00팀 100명의 평균 키 / 키의 분산 / 165cm보다 키가 큰 사람의 비율 등과 같이 모수의 특정 정보를 모수라고 부릅니다.
대표적인 모수에는 모평균, 모분산, 모표준편차, 모비율 등이 있습니다. 우리는 모집단 전체 데이터는 얻을 수 없으니, 모집단의 특성을 나타내는 모수를 파악하여 모집단의 특성을 파악하고자 하는 것입니다.
그렇다면, 표본 집단의 특정 정보는 무엇이라고 부를까요? 통계량 (Statistic) 혹은 추정량(Estimator)이라고 부릅니다. 예를 들면, 00팀 100명 중 선택된 5명의 평균 키 / 키의 분산 등이 되겠죠.
대표적인 통계량에는 표본평균, 표본분산, 표본표준편차, 표본비율 등이 있습니다.
3) 추정 ? 점추정? 구간 추정?
우리는, 앞서 배운 모집단의 특정 정보인 모수를 추정하고 싶어합니다. 궁금하니까요.
이런 모수를 추정하는데에는 2가지 방법이 있습니다. 1) 점추정 2) 구간추정입니다.
3-1) 점추정과 구간 추정
점추정은 단어에서 알 수 있듯 모수를 표본으로 얻은 정보를 이용해 하나의 값으로 추정하는 방법입니다.
구간추정은 모수를 표본으로 얻은 정보를 이용해 모수가 포함할 것이라고 예상되는 구간을 제시하는 방법입니다.
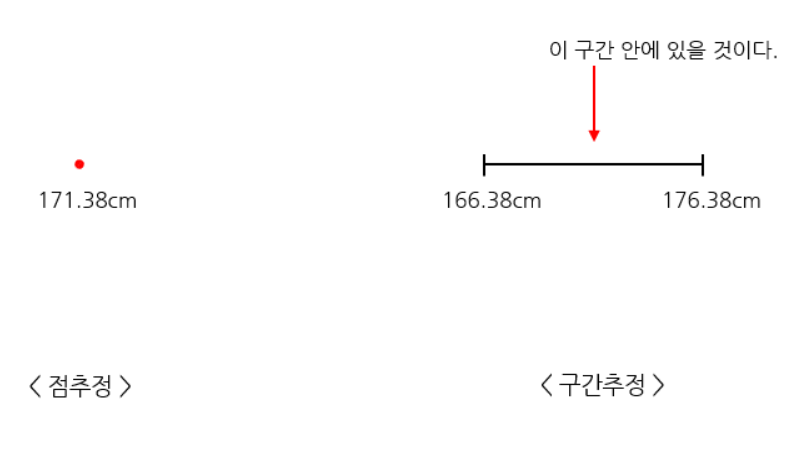
위 그림을 보면, 이해가 더 빠를 것 같은데요. 위와 같이 추정을 하나의 값으로 하냐, 구간을 제시하고 그 안에 있을 것이라 제시하냐의 차이라고 이해해주시면 될 것 같습니다.
3-2) 추정치와 추정량
점추정에서 듣게 되는 단어와 그 개념을 간략하게 설명 드리겠습니다. 먼저, 다소 헷갈릴 수 있는 추정치와 추정량입니다.
추정량은 추정에 사용되는 통계량으로서, 추정치를 구하는 식이 된다고 이해하면 되고, 추정치는 표본의 실제 값을 추정량에 대입하여 구한 값입니다.
추정량 = 미지의 모수(θ)의 추정에 사용되는 통계량 (→ 통계량의 일부)
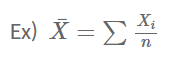
추정치 = 확률 표본의 특정한 관측값에 대한 추정량의 관측값 (→ 즉, 추정량에 실제 관측값을 대입하여 나온 값을 의미합니다.)
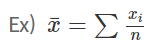
3-3) 좋은 (점) 추정량의 조건
이런, 추정량에는 좋은 추정량이 되기 위한 몇 가지 조건이 존재합니다.
1) 불편성 (unbiasedness) 2) 효율성 (efficiency) 3) 일치성 (consistency)
먼저, 불편성입니다. 불편하다…뭐가 불편한 것일까요? 여기서 말하는 불편은 앞으로도 자주 듣게 될 용어이니 기억 해두시면 좋을 것 같습니다.
불편이란, “편의 (bias)가 없는 상태”를 의미합니다. 그렇다면, 편의가 없는 상태는 무엇을 뜻할까요?
추정량의 기댓값(평균)이 모수와 같다면, 해당 추정량을 불편성을 충족한다고 하고 그 추정량을 불편 추정량이라고 부릅니다.
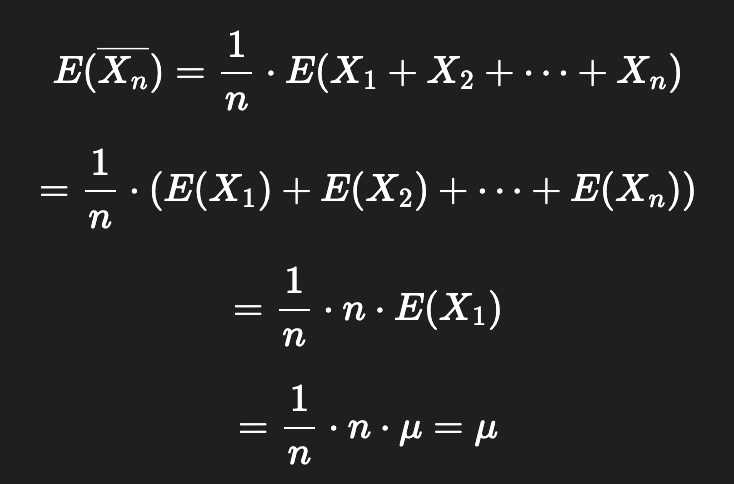
다음으로, 효율성입니다. 효율성이란, 여러 개의 불편 추정량이 존재한다면, 추정량의 분산이 가장 작은 것을 선택한다는 의미입니다. 분산이 작아야 더 정확하게 모수를 추정할 가능성이 높기 때문입니다.
마지막으로, 일치성입니다. 일치성이란, 표본 크기가 증가함에 따라서 추정량이 불편성을 충족하는 방향으로 움직이는 현상을 의미합니다.
4) 신뢰 구간과 신뢰 수준
앞에서는, 좋은 점추정량 조건에 대해서 배웠다면, 이번에는 좋은 구간 추정이란 무엇인지 설명 드리겠습니다.
대부분의 여론조사는 구간 추정 방식으로 진행 됩니다. 여론 조사에서는 그 틀릴 수 있는 가능성을 표본 오차와 신뢰 수준으로 제시해두고 있는데요.
아래와 같은 예시를 많이 보실 수 있을텐데요. 저기서 말하고 있는 95% 신뢰 수준 표본 오차+- 2.0%p가 어떤 의미를 가질까요?

유권자 전체의 지지율과 표본으로 추정한 지지율 간에는 오차가 존재합니다. 표본 오차란 이 오차를 어디까지 허용하는지를 의미합니다.
예를 들어, A 정당 지지율은 28~32%, B 정당 지지율은 18 ~22%로 구간 추정한 것이고, 오차를 포함한 지지율의 범위를 신뢰구간이라고 부릅니다. 위와 같은 상황에서는 정당지지율의 범위가 서로 겹치지 않으나, 초 경합 상황에서는 겹치는 상황이 발생할 수도 있습니다.
그렇다면, 95% 신뢰 수준의 의미는 무엇일까요? 신뢰 수준이란 앞서 제시한 신뢰 구간을 어느정도로 신뢰할 수 있는지를 의미합니다. 여론 조사를 100번 정도 한다고 했을 때, 실제 유권자 전체 지지율이 해당 신뢰 구간 내에 몇번이나 포함 되느냐로 간략히 설명 할 수 있습니다. 위 조사에서는 95% 신뢰수준이었으므로, 95번 정도는 전체 지지율이 신뢰 구간안에 포함 될 것이고, 5번 정도는 포함되지 않을 가능성이 있다는 의미를 내포합니다.
아마 인지하셨겠지만, 표본 오차와 신뢰수준에는 트레이드 오프 관계가 있습니다. 신뢰수준을 높이면, 구간은 넓어지고 신뢰 수준을 낮추면, 구간은 좁아지게 되는 것이죠. 어떤 수준이 좋은지에는 정답이 없습니다. 다만, 일반적으로 여론 조사의 신뢰 수준은 95~99%라고 합니다.
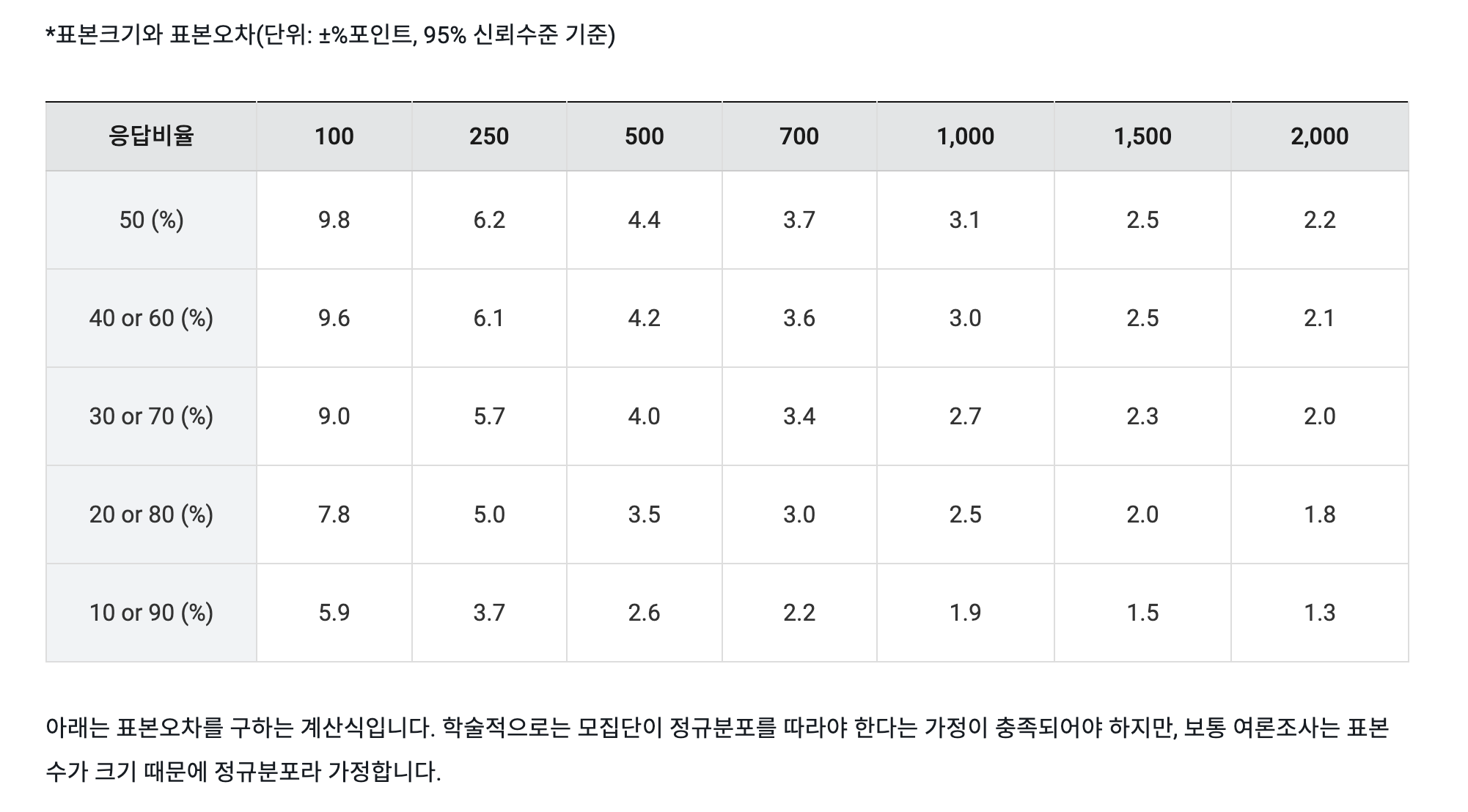
표본의 크기와 표본오차 계산식은 아래를 참고하실 수 있습니다. (한국갤럽조사연구소)
5) 중심 극한 정리
마지막으로, 중심 극한 정리에 대해 소개하도록 하겠습니다.
중심 극한 정리의 개념은 아래와 같습니다.
“모집단이 「평균이 μ이고 표준편차가 σ인 임의의 분포」을 이룬다고 할 때, 이 모집단으로부터 추출된 표본의 「표본의 크기 n이 충분히 크다」면 표본 평균들이 이루는 분포는 「평균이 μ 이고 표준편차가σ/√n인 정규분포」에 근접한다.”
말이 너무 어렵습니다..아래 영상을 보며 설명 드리도록 하겠습니다.
모집단 = 3학년 1반 전체 학생 / 모평균 = 3학년 1반 전체 학생 키의 평균 / 모표준편차 = 3학년 1반 전체 학생 키의 표준편차
표본 = 3학년 1반 학생 중 임의로 선택한 학생 / 표본의 크기 = 몇번 고를 것인지 / 표본 평균 = 3학년 1반 학생 중 선택된 학생의 키의 평균
표본 평균이 이루는 분포 = 3학년 1반 학생 중 선택된 학생 키의 평균의 분포
위와 같이, 연구자가 표본을 많이 추출하게 된다면 (일반적으로는 30회) 표본 평균의 분포가 평균이 μ 이고 표준편차가σ/√n인 정규분포에 근접한다는 의미입니다. 표본의 크기 (몇개를 뽑냐)가 아니라 표본을 몇 번 뽑느냐가 중요한 포인트입니다.
위 개념은 이해가 다소 어려운데요. 영상 하나 링크로 남겨드리니 추후 참고해보셔도 좋을 것 같습니다.
https://www.youtube.com/watch?v=RuEVjWtlIs8
이상으로, 인과추론을 위한 여론 조사로 배우는 기초 통계 세션 글을 마치겠습니다.
잘 못 설명한 부분이나, 설명이 부족한 부분이 있을텐데 많이 피드백 부탁드립니다. 🙂
참고 자료 및 출처
https://m.blog.naver.com/with_msip/222109275353
https://ssung-22.tistory.com/42
https://www.gallup.co.kr/gallupdb/faqContents.asp?seqNo=107
https://dataitgirls2.github.io/tutorial/Tutorial_180629_Statistics.html
https://velog.io/@nellholic108/통계학-개념-정리
https://recipesds.tistory.com/entry/통계-개론-에뜨-부-쁘레
https://warm-uk.tistory.com/24
https://ssung-22.tistory.com/42
