(작성중)
온라인 SQL 연습 사이트
로컬에 직접 구축해서 써도 좋지만 귀찮으니까 온라인을 활용하자!
# INSERT SCRIPT
CREATE TABLE sql_test_a
(
NAME VARCHAR2(200 BYTE),
JOB VARCHAR2(200 BYTE),
PAY INT,
DNO VARCHAR2(200 BYTE)
);
CREATE TABLE sql_test_b
(
ID VARCHAR2(4000 BYTE)
);
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('KIM', 'MANAGER', 1000, '10');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('PARK', 'CLERK', 7000, '10');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('PARK', 'CLERK', 7000, '10');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('LEE', 'MANAGER', 3750, '20');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('JAMES', 'ANALYST', 2500, '20');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('JOHNSON', 'ANALYST', 3975, '30');
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('ALLY', 'SALESMAN', 1200, '30');
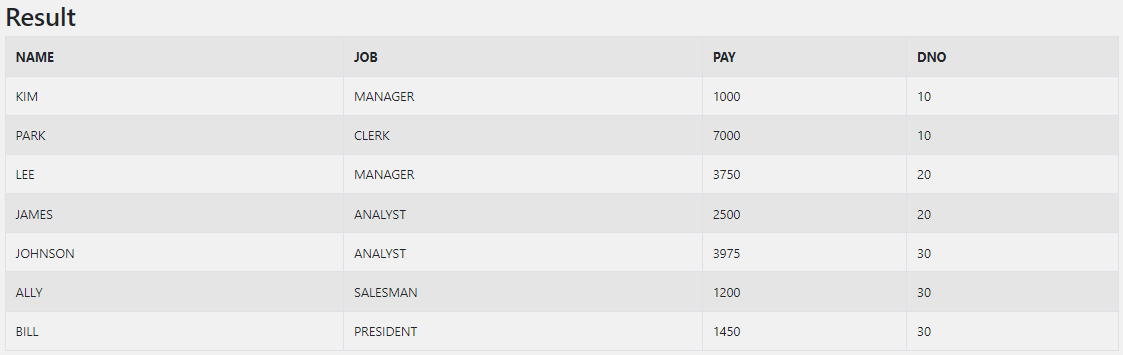
INSERT INTO sql_test_a (NAME, JOB, PAY, DNO) VALUES ('BILL', 'PRESIDENT', 1450, '30'); 본 글에서는 위와 같이 샘플 테이블을 만들고 실습을 진행하겠다.
Group Function(그룹 함수)
그룹별 소계 및 중계 등 중간 합계 분석 데이터를 산출하는 함수이다.
GROUP BY
- 항상 칼럼명을 써줘야 한다.
SELECT와GROUP BY절의 칼럼이 같아야 한다.
옳지 않은 예시
SELECT *
FROM sql_test_a
GROUP BY DNO;
칼럼이 같지 않을 경우 ORA-00979: not a GROUP BY expression 에러가 발생한다(ORACLE 기준).
옳은 예시
SELECT DNO, AVG(PAY)
FROM sql_test_a
GROUP BY DNO;3.
NULL이 존재하는 ROW는 제외하고 산출한다.
4. 수행 순서는
JOIN->WHERE->
GROUP BY이다.
HAVING
GROUP BY 속성명 HAVING (조건)
형태로 GROUP BY에 대한 조건식을 추가 서술해줄 수 있다.
OLAP
https://dbrang.tistory.com/416
OLAP GROUPING
ROLL UP
https://loustler.io/data_eng/basic-analytical-operations-of-olap-part-1/
OLAP 기본 연산
(1) roll up
(2) drill down
(3) slicing and dicing
(4) pivoting
https://loustler.io/data_eng/basic-analytical-operations-of-olap-part-2/
CUBE
OLAP 에서의 다차원 배열을 의미
GROUPING
null을 방지하고 1, 0 반환
decode와 함께 써서 원하는 값으로 출력 가능
GROUPING SETS
Aggragate Function(집계 함수)
몇 개의 ROW가 입력으로 들어오던지 하나의 결과값을 반환하며 NULL 값은 제외된다.
SUM, AVG, MAX, MIN, COUNT, STDDEV, VARIAN 등이 있다.
Window Function(분석함수)
데이터베이스를 사용한 온라인 분석 처리인 OLAP(Online Analytical Processing 함수에서 사용된다.
JOIN 함수 사용과 OVERHEAD를 줄이면서 간결하게 분석 작업을 수행하는 것이 목표이다. 주요 SYNTAX는 아래와 같다.
SELECT ANALYTIC_FUNCTION(args)
OVER (
[PARTITION BY 컬럼 LIST]
[ORDER BY 컬럼LIST]
[WINDOWING절(ROWS | RANGE BETWEEN)]
)
FROM 테이블명; ANALYTIC FUNCTION : 분석함수명(입력인자)
OVER : 분석함수임을 나타내는 키워드
PARTITION BY : 계산 대상 그룹 지정 >>GROUP BY와 비슷한 역할. 이 구문이 없으면 전체 데이터에 대해 계산이 적용됨.
ORDER BY : 대상 그룹에 대한 정렬 수행
WINDOWING 절 : 분석함수의 계산 대상 범위 지정
(ORDER BY절에 종속적.
기본 생략 구문 : 정렬된 결과의 처음~현재행까지)1.
GROUP BY절을 사용할 수 없다.
그룹핑이 필요하다면PARTITION BY를 사용한다.
2. 윈도우 함수는 여러개를 중첩해서 사용할 수 없다
3. 윈도우 함수는 반드시
OVER와 함께 사용한다.
WINDOWING
ORDER BY
정렬 순서를 명시하는 함수이다. 같은 값끼리 묶어주고 싶다면 DISTINCT 를 붙여준다.
GROUP BY와 유사한 기능이지만 syntax가 다르다.
- 칼럼 이름 대신 별칭 사용이 가능하다.
SELECT * from sql_test_a
ORDER BY job;
GROUP BY와 다르게SELECT와 칼럼이 일치하지 않아도 된다.
PARTITION BY
칼럼별로 같은 값을 가진 ROW끼리 모아서 연산하고 싶을 때 사용한다.
DNO 별로 모아서 PAY 평균을 내고, DNO 별로 보이는 예제와 결과이다.
SELECT DISTINCT DNO, TRUNC(AVG(PAY) OVER (PARTITION BY DNO))
FROM PERSONNEL; 
(참고) TRUNC 함수
ORCLE DB에서 소수점 없이 출력하는 함수이다.
이때 ORDER BY와의 차이점을 알아보자. 똑같은 쿼리문을 작성하고 결과를 비교해본다.
SELECT DISTINCT DNO, TRUNC(AVG(PAY) OVER (ORDER BY DNO))
FROM sql_test_a;
얼핏보면 AVG(PAY)가 정상적으로 실행된 것처럼 보이지만 PARTITION BY를 했을 때와 숫자가 다르다.
ORDER BY를 하게 되면 DNO 순으로 정렬한 후, 첫 번째 ROW부터 마지막으로 더한 ROW까지의 수로 나누기를 한다. 다만 이때 연산이 수행되는 주기가 DNO가 구분되는 시기일 뿐이다.
PARTITION BY는 DNO 별로 구분해서 AVG를 연산한다. 예를 들어 DNO가 10인 ROW들만 더 해서 해당 ROW의 개수만큼 나눠준다.
| PAY | SUM(PAY) | AVG(PAY) | DNO |
|---|---|---|---|
| 1000 | 1000 | 4000 | 10 |
| 7000 | 8000 | 4000 | 10 |
| 3750 | 3750 | 3125 | 20 |
| 2500 | 6250 | 3125 | 20 |
| 3975 | 3975 | 2208 | 30 |
| 1200 | 5175 | 2208 | 30 |
| 1450 | 6625 | 2208 | 30 |
그러나 ORDER BY는 ROW를 DNO 순으로 정렬하는 역할만 한다. DNO가 다른 것이 PAY 연산에 아무 영향을 미치지 않기 때문에 ROW 1부터 차곡차곡 더해온 값을 다른 DNO 를 만날 때마다 나누기 연산해준다.
| PAY | SUM(PAY) | AVG(PAY) | DNO |
|---|---|---|---|
| 1000 | 1000 | 4000 | 10 |
| 7000 | 8000 | 4000 | 10 |
| 3750 | 11750 | 3562 | 20 |
| 2500 | 14250 | 3562 | 20 |
| 3975 | 18225 | 2982 | 30 |
| 1200 | 19425 | 2982 | 30 |
| 1450 | 20875 | 2982 | 30 |
OVER
그룹 정렬 시 유용한 분석 함수이다.
OVER ( [PARTITION_BY_CLAUSE] ORDER_BY_CLAUSE )
EXPR : 대상 컬럼명
OFFSET : 값을 가져올 행의 위치 기본값은 1, 생략 가능
DEFAULT : 값이 없을경우 기본값(=NULL), 생략가능
PARTITION_BY_CLAUSE : 그룹 컬럼명, 생략가능
ORDER_BY_CLAUSE : 정렬 컬럼명, 필수ORDER BY도 정렬을 담당하는 것 같은데 굳이 OVER가 또 있어야 하는 필요가 뭘까?
1. 그룹함수 + OVER()
GROUP BY없이 일반함수만으로도 그룹별 처리를 가능하게 한다.
2. 그룹함수 + OVER(PARITION BY)
그룹함수의 GROUPING 범위를 지정한다.
3. WHERE 절에 사용할 수 없다
SELECT DISTINCT JOB, AVG(PAY)
FROM sql_test_a
ORDER BY JOB;여기서 나이 평균 결과는 1개지만, JOB는 unique한 개수만큼 나올 것이므로 ORA-00937: not a single-group group function가 발생한다(ORACLE 기준).
unique한 job 별로 나이 평균을 구하고, job과 매핑해서 출력해주려면 다음과 같이 OVER를 통해 정렬해줘야한다.
SELECT DISTINCT JOB, TRUNC(AVG(PAY) OVER (ORDER BY JOB))
FROM sql_test_a;
RANK()
RANK()는 등수를 뽑고 싶을 때 사용 가능한 윈도우 전용 순위 함수이다.
SELECT NAME, PAY, RANK() OVER(ORDER BY PAY DESC) AS RANK
FROM sql_test_a;
1. RANK 뒤 () 소괄호 안에는 아무것도 적지 않는다.
2. 순위를 정하려는 컬럼은
ORDER BY에 기입한다.
pay를 내림차 순으로 정렬한 후 --> OVER(ORDER BY PAY DESC)
랭킹을 매겨 --> RANK()
RANK라는 새 컬럼에 넣어준다 --> as rank
3. 공동 순위가 있다면 동일한 순위의 수만큼 건너뛰고 다음 순위가 매겨진다.
공동 1등이 2명이라면, 2등이 없고 3등부터 시작

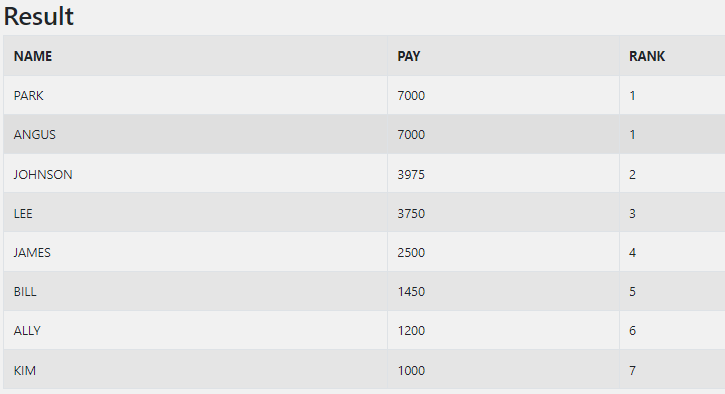
DENSE_RANK()
DENSE_RANK()와 RANK()의 차이점은 공동 순위를 1개로 치느냐, 각각을 모두 세어주느냐이다. RANK()는 앞서 살펴보았듯, 각각을 모두 세어주고 그만큼 다음 순위를 미뤘다. DENSE_RANK()는 공동 순위가 몇 명이던지 상관 없이 그 다음 순위는 +1이 된다.
SELECT NAME, PAY, DENSE_RANK() OVER(ORDER BY PAY DESC) AS RANK
FROM sql_test_a;
ROW_NUMBER()
정렬된 결과에 대해 순서를 부여한다. 값이 동일한 것은 상관없이 SERIAL하게 매겨지며 반환되는 전체 ROW의 개수와 최대 ROW_NUMBER는 같다.
SELECT NAME, PAY, ROW_NUMBER() OVER(ORDER BY PAY DESC) AS ROW_NUMBER
FROM sql_test_a; 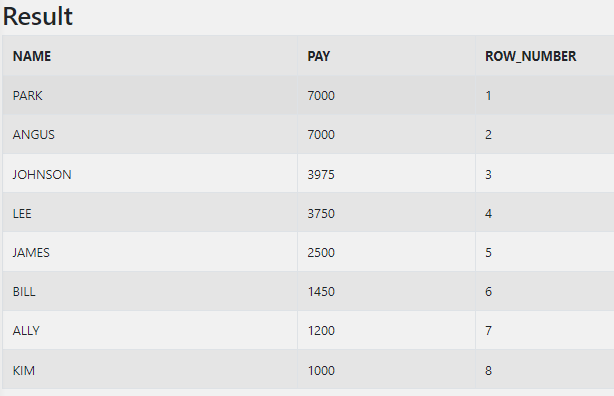
PERCENT_RANK()
http://statwith.com/percent_rank-oracle-function-list/
CUME_DIST()
ROW_NUMBER()
NTILE()
https://devjhs.tistory.com/176
RATIO_TO_REPORT
해당 구간에서 차지하는 비율을 보여준다.
SELECT NAME, PAY, RATIO_TO_REPORT(PAY) OVER() AS RATIO
FROM sql_test_a; 
LAG/LEAD
LAG | LEAD ( EXPR [ , OFFSET[P,DEFAULT] ) LAG는 현재 ROW 기준으로 이전 값을 참조한다.
LEAD는 현재 ROW 기준으로 이후의 값을 참조한다.
SELECT NAME, PAY,
LAG(NAME) OVER (ORDER BY PAY) AS LAG,
LEAD(NAME) OVER (ORDER BY PAY) AS LEAD
FROM sql_test_a; 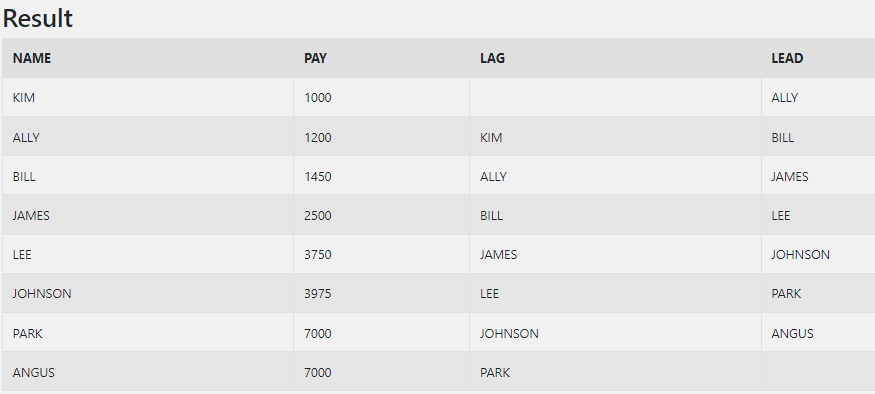
ORACLE 함수
ORACLE DB에만 있는 편리한 함수가 있어서 소개하고자 한다.
DECODE
if else 문과 유사하게 동작하는 함수이다.
SELECT PNAME,BONUS,DNO,PAY,
DECODE (DNO,10,PAY*1.1,20,PAY*1.2,PAY*1.3) "인상분"
FROM PERSONNEL; python 코드로 나타내면 아래와 같다.
if(DNO==10):
인상분=PAY*1.1
elif(DNO==20):
인상분=PAY*1.2
else:
인상분=PAT*1.3아래와 같이 삼항연산자처럼 쓸수도 있다.
SELECT DNO,AVG(PAY) 부서평균,
DECODE(SIGN(AVG(PAY)-
(SELECT AVG(PAY) FROM PERSONNEL)),1,'GOOD','POOR') 상태
FROM PERSONNEL
GROUP BY DNO;(참고) SIGN 함수
0보다 크면 1 반환
0보다 작으면 -1 반환
0이면 0 반환
참고 자료
https://velog.io/@mindddi/SQL-%EB%B6%84%EC%84%9D%ED%95%A8%EC%88%98
https://rimkongs.tistory.com/107
