Reliability 신뢰성
신뢰성은 '주어진 환경에서 특정 목적을 위해, 지정된 시간 동안 고장 없이 운영될 수 있는 확률'이며 시스템의 서비스가 지정한 대로 올바르게 전달될 확률을 말한다.
신뢰성은 t시간 동안 시스템이 작동하고 있었을 때, 시스템이 여전히 작동 중일 확률을 시간 t+1에서 표현하는 함수로 나타낸다.
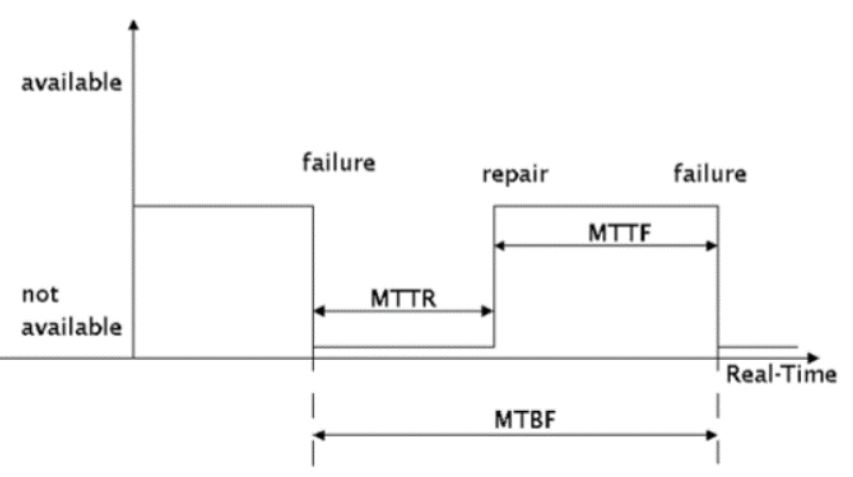
일반적으로 MTBT(Mean Time Between Failures) , 평균 고장 간격으로 설명한다.
ex) MTBF of 1 day, month, year...
MTBF(Mean Time Between Failures)
수리 가능한 장치의 예상 수명을 예측하는 척도로, 고장 발생 시점부터 다음 고장 발생 시점까지의 평균 시간을 뜻하며 길수록 유리하다.
MTBF: Mean Time Between Failure 평균 고장 간격
MTTF + MTTR = 고장률 = 고장건수/총가동시간
MTBF = 1/고장률
Availability 가용성
가용성은 '주어진 시점에서 요청된 서비스가 제공되고 운영될 수 있는 확률', 사용자가 서비스를 요청했을 때, 서비스를 제공할 수 있는 확률을 말한다.
가용성은 얼마나 자주 시스템을 사용할 수 있는지, 그 빈도를 나타내는 척도로 백분위로 나타낸다.
가용성(%) = MTTF/(MTTF+MTTR) = MTTF/MTBF
MTTF: Mean Time To Failure 평균 고장 시간 (총가동시간/고장건수)
MTTR: Mean Time To Repair 평균 수리 시간 (총고장시간/고장건수)
신뢰성과 가용성의 관계
신뢰성이 가용성을 보장하거나, 가용성이 신뢰성을 보장하지 않는다.
라우터는 대표적으로 신뢰성은 낮고 가용성은 높은 디바이스이다.
라우터는 fault torelance feature를 가지고 있지 않기 때문에 packet이 유실될 수 있다. fault를 핸들링하는 기능은 라우터가 아닌 엔드포인트가 가지고 있으며 라우터는 packet 유실에 신경 쓰지 않는다. 즉 라우터는 신뢰성이 낮다. 반면 24시간 운영되므로 가용성이 높다.
클라우드는 신뢰성과 가용성이 둘다 높아야 하지만, 신뢰성이 높다고 가용성이 높은 것은 아니다.
서버의 MTBF가 30년(10,000일)라고 해서 서버 전체가 30년 동안 한번도 고장이 나지 않는 것이 아니다. 10,000개의 서버로 구성된 클러스터에서는 하루 평균 한 개의 서버 장애가 발생하므로 사실 일반적인 서버는 MTBF를 30년 미만이며, 실제 클러스터 MTBF는 몇 시간의 범위에 있을 것이다. 그러나 클러스터의 fault tolerance 기능 덕분에 서버가 계속 운영될 수 있는 것이다. 따라서 클러스터의 가용성은 100%에 근접하여 다운타임을 최소화하는 것을 목표로 한다. (100%은 이상적인 수치이다.)
Serviceability 서비스 가능성
서비스 가능성은 시스템을 얼마나 쉽게 서비스하거나 수리할 수 있는지 설명한다.
고장난 시스템을 수리하는 시간이 늘어나면 가용성이 떨어지므로 복구시간과 가용성은 반비례 관계이다.
참고자료
