Keyword
- DMA
- DP
- realloc
Reference
TODO
- DMA
- 개념 공부
- 정리하기
- 이더넷
- 개념 공부
- 정리하기
- 알고리즘
- 1문제 풀기
- 정리하기
- realloc 개선하기
- CSAPP 11장
- 발표 준비
How to live today
오전 : 알고리즘, DMA
오후 : DMA 정리, 알고리즘 문제 정리, realloc 개선, 이더넷
저녁 : 이더넷 정리, CSAPP 11장, 발표준비
What I did?
발표 준비 - worst fit
Worst-Fit Allocation in Operating Systems - GeeksforGeeks
worst fit & realloc 개선하기
worst fit
CSAPP 책에는 나오지 않았지만, 혼자 공부하는 컴퓨터구조&운영체제에 나온 worst fit을 구현해봤다.
🤔 worst fit이란?
할당할 수 있는 가용 블록 중 가장 크기가 큰 블록에 할당하는 방식
이름은 worst fit이지만, 분할과 합쳐지면 생각보다 좋은 성능을 낸다.
- 가장 큰 곳에 할당하기 때문에 분할 후에 생긴 가용 블록의 크기가 큼 → 외부 단편화 가능성 감소
/**
* @brief asize만큼 할당할 수 있는 free 블록을 찾는 함수. worst fit 알고리즘 사용
*
* @param asize 할당하려는 크기
* @return void* asize 크기를 할당할 수 있는 free 블록의 포인터. 적합한 블록을 찾지 못하면 NULL 반환
*/
static void *worst_fit(size_t asize)
{
void *bp;
void *worst = NULL;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && GET_SIZE(HDRP(bp)) >= asize)
{
if (worst == NULL)
{
worst = bp;
continue;
}
if (GET_SIZE(worst) < GET_SIZE(bp))
{
worst = bp;
}
}
}
return worst;
}realloc 개선
위 블로그를 참고해서 개선된 realloc을 적용하면 맥북에서도 80점이 넘는 점수를 얻을 수 있다고 한다.
하지만 내가 적용해본 결과 explicit에서는 error가 발생하고, implicit에서는 60~62점 정도가 나온다… 🥺 (왜지… 왤까…)
기존 내 코드가 비효율적인가?????
그래도 오르긴 올랐으니까 분석해보자
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr;
void *newptr;
size_t originsize = GET_SIZE(HDRP(oldptr)); // 기존에 할당된 크기
size_t newsize = size + DSIZE; // 새롭게 할당 요청 받은 크기
/* 새로 요청받은 크기가 기존 크기보다 작은 경우 */
if (newsize <= originsize)
{
return oldptr;
}
else
{
size_t addsize = originsize + GET_SIZE(HDRP(NEXT_BLKP(oldptr))); // 기존 블록의 크기 + 다음 블록의 크기
/* 다음 블록이 가용 블록이고 현재 블록과 연결했을 때 요청받은 크기를 수용할 수 있는 경우 */
if (!GET_ALLOC(HDRP(NEXT_BLKP(oldptr))) && (newsize <= addsize))
{
/* coalesce */
PUT(HDRP(oldptr), PACK(addsize, 1));
PUT(FTRP(oldptr), PACK(addsize, 1));
return oldptr;
}
else
{
/* 새로운 블록 할당하고 반환 */
newptr = mm_malloc(newsize);
if (newptr == NULL)
return NULL;
memmove(newptr, oldptr, newsize);
mm_free(oldptr);
return newptr;
}
}
}- 기존 코드는 요청이 들어오면 무조건 새롭게 블록을 할당해서 반환했다.
- 개선된 코드
- 기존 블록의 다음 블록이 가용 블록이고 둘을 연결했을 때 사이즈가 충분하다면 단순히 헤더, 푸터만 갱신
- 기존 사이즈보다 재할당 받은 사이즈가 더 작다면 기존 블록 반환
- 사실 이렇게 해도 되는지 모르겠음
- 더 작은 사이즈를 요청했는데 그대로 리턴하면…. 되나?
implicit + next fit + improved realloc
Team Name:Team 4
Member 1 :Kang Bada:gangbada890@gmail.com
Using default tracefiles in ./traces/
Perf index = 45 (util) + 14 (thru) = 60/100implicit + worst fit + improved realloc
Team Name:Team 4
Member 1 :Kang Bada:gangbada890@gmail.com
Using default tracefiles in ./traces/
Perf index = 48 (util) + 14 (thru) = 62/100What I Learned?
이더넷
DMA (Direct Memory Access)
입출력 제어 방식
컴퓨터와 입출력장치 사이에서 데이터가 오가는 방식을 입출력 제어방식이라고 한다.
입출력 제어방식의 종류
| 제어방식 | CPU 관여 여부 |
|---|---|
| 프로그램에 의한 I/O (PIO) | ⭕️ |
| Interrupt에 의한 I/O | ⭕️ |
| DMA에 의한 I/O | ❌ |
| Channel에 의한 I/O | ❌ |
Programmed I/O (PIO)
- CPU가 입출력(데이터의 이동)을 담당한다.
- 입출력을 할 준비가 되었는지에 대한 상태(Flag)를 계속 확인해야 한다. → 폴링
- CPU는 입출력에 대한 준비가 완료될 때까지 기다리는 시간 + 입출력을 직접 진행하는 시간 동안 다른 연산을 수행하지 못 함
동작 순서
- 입출력장치가 I/O 요청을 한다
- CPU가 수행하던 작업을 멈춘다
- CPU는 입출력의 준비가 될 때까지 기다린다. (폴링)
- 입출력 준비 완료를 알리면 CPU는 입출력을 진행한다.
- 입출력을 완료하면 원래 하던 작업을 수행한다.
단점
I/O 장치는 매우 느리고, 대기하면서 특별한 일을 하는 것도 아니다!
이처럼 PIO 방식은 매우 비효율적이다.
DMA
🤔 Direct Memory Access란?
직역하자면 직접 메모리 접근이라는 뜻으로,
특정 하드웨어 장치가 CPU와 독립적으로 메인 메모리에 접근할 수 있게 해주는 컴퓨터 시스템의 기능이다.
PIO와 반대되는 개념으로 데이터가 CPU를 거치지 않는다.
대신, 입출력장치가 직접 메모리에 접근하여 data block을 읽고 쓸 수 있다.
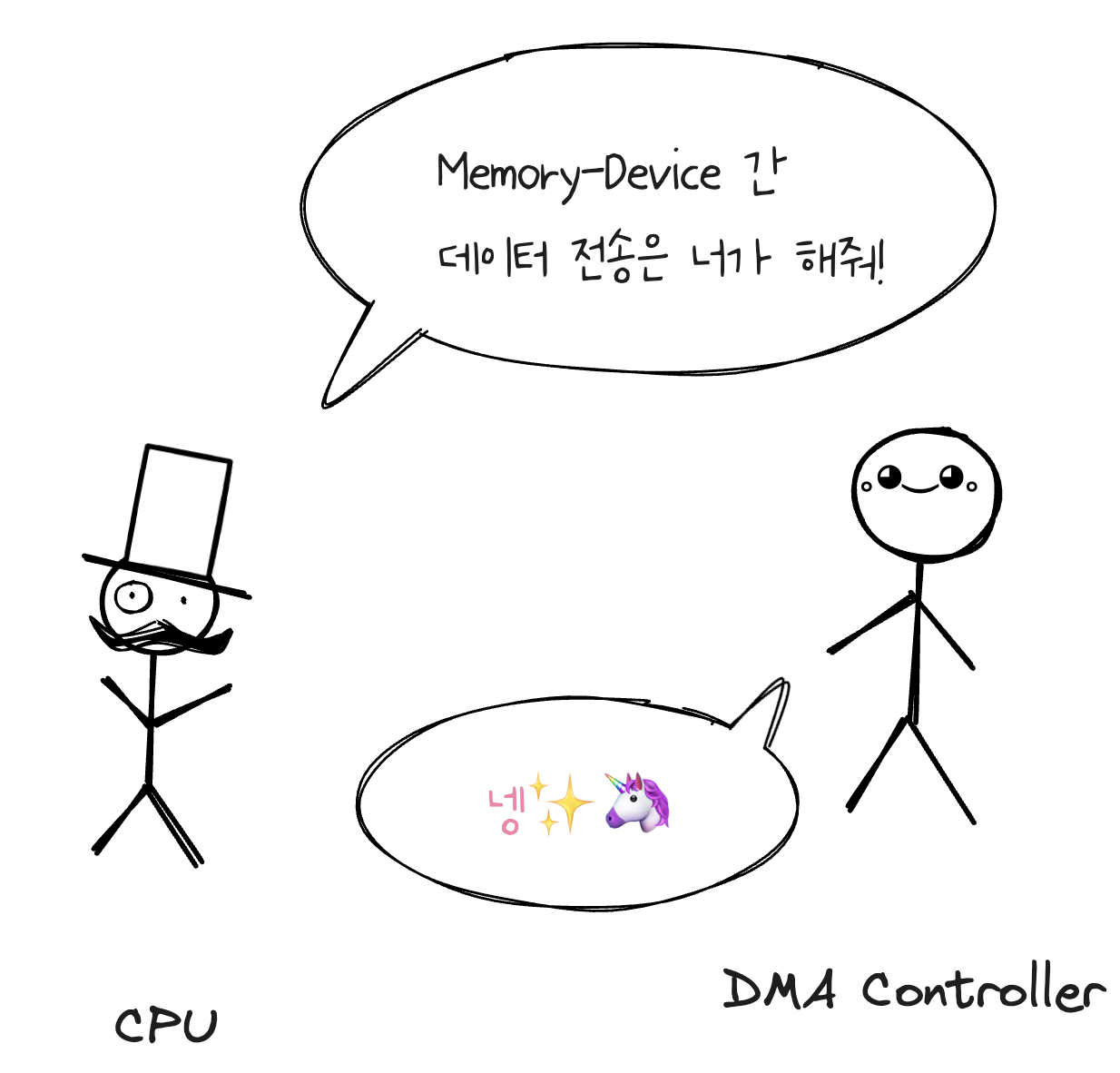
- CPU는 DMA Controller에서 입출력에 필요한 정보만을 넘긴다.
- DMA controller가 입출력을 수행하며, 그동안 CPU는 다른 연산을 수행한다.
- Cycle steal
- 만약, 컨트롤러가 데이터를 전송하는 과정에서 CPU와 동시에 메모리에 접근할 때 컨트롤러가 우선권을 빼앗아 자료를 전송
- 일반적으로 CPU보단 입출력장치가 필요로하는 memory cycle의 양이 적기 때문에 입출력의 효율이 높아짐
동작 순서
- CPU가 입출력에 대한 정보를 DMA Controller에게 전달한다.
- DMA controller는 CPU에게 버스 사용을 요청한다. (Bus Request)
- CPU는 DMA controller에게 버스 사용을 허가한다. (Bus Grant)
- DMA controller가 입출력 작업 진행
- 입출력이 완료되면 DMA Controller가 CPU에게 인터럽트 신호를 보냄
CPU → DMA Controller 정보
- I/O 장치의 주소
- 데이터가 있는 메인 메모리 시작 주소
- DMA를 시작시키는 명령
- 입출력 하고자 하는 자료의 양
- 입력 또는 출력을 결정하는 명령
10844번 쉬운 계단 수

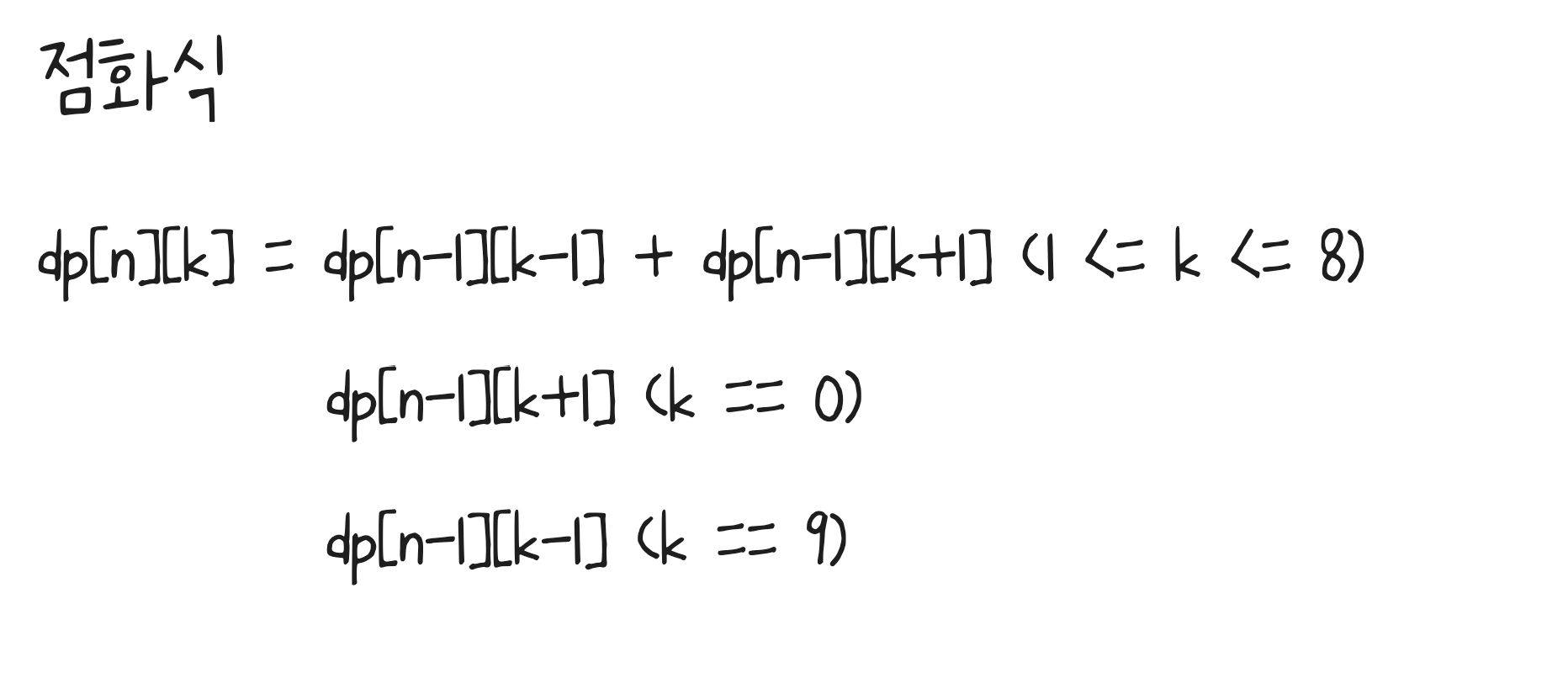
import sys
input = sys.stdin.readline
n = int(input())
# dp 테이블 선언 (행: 0 ~ N / 열: 0 ~ 9)
# 행: 계단 수의 길이 / 열: 1의 자리 숫자
dp = [[0] * (10) for _ in range(n+1)]
# 길이가 1인 경우 1로 초기화
# 0은 1로 초기화하면 안 된다. (0으로 시작하는 숫자는 계단 수가 아님)
for i in range(1, 10):
dp[1][i] = 1
# dp 테이블 채우기
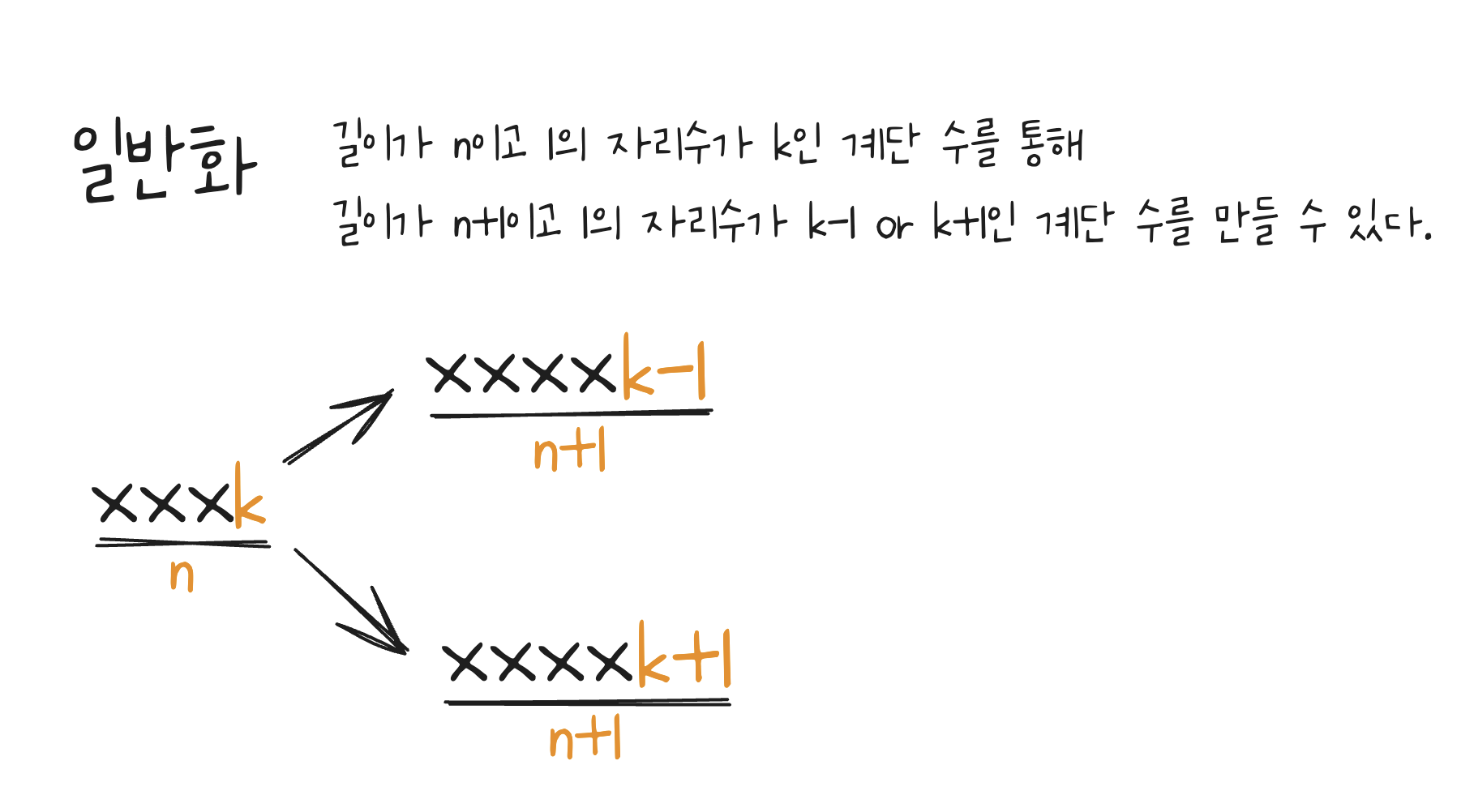
# 점화식: dp[n][k] = dp[n-1][k-1] + dp[n-1][k+1]
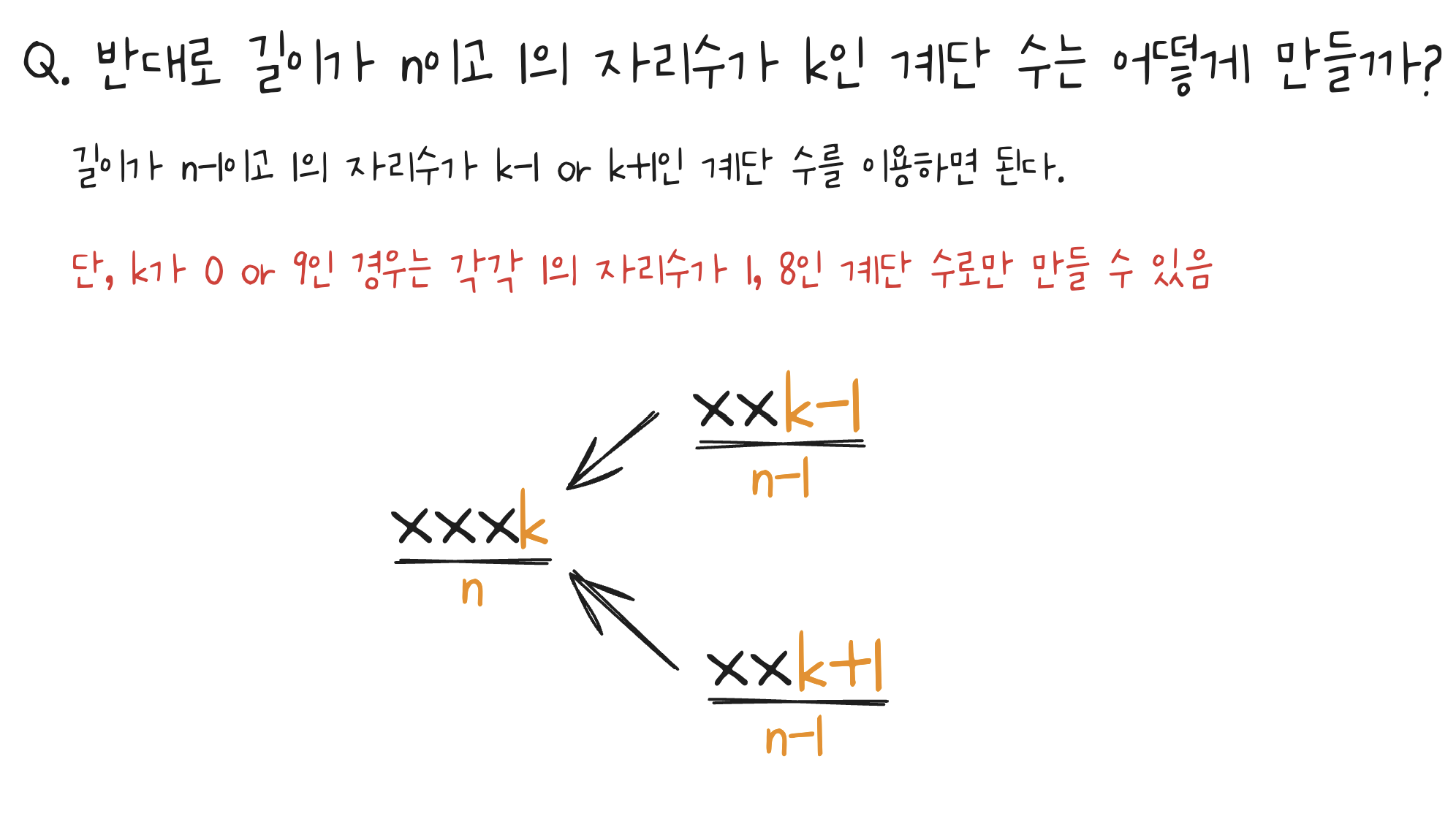
# 예외: k가 0 또는 9일 때
for i in range(2, n+1):
for k in range(10):
if k == 0:
dp[i][k] = dp[i-1][k+1]
elif k == 9:
dp[i][k] = dp[i-1][k-1]
else:
dp[i][k] = dp[i-1][k-1] + dp[i-1][k+1]
# 정답을 1,000,000,000으로 나눈 나머지 출력
print(sum(dp[-1]) % 1000000000)