1. 선택 정렬(Selection Sort)
주어진 배열에서 최솟값을 찾아 배열의 맨 앞에 위치시키는 방식으로 동작한다. 이러한 과정을 반복하면서 배열이 정렬 된다.
1-1. 과정
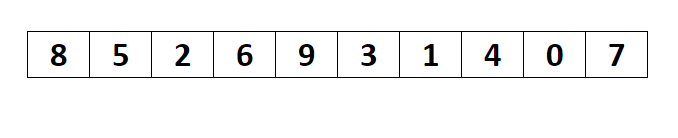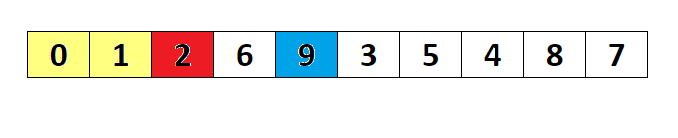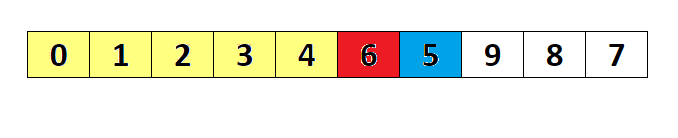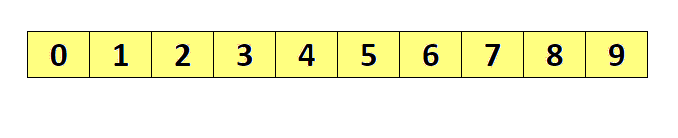
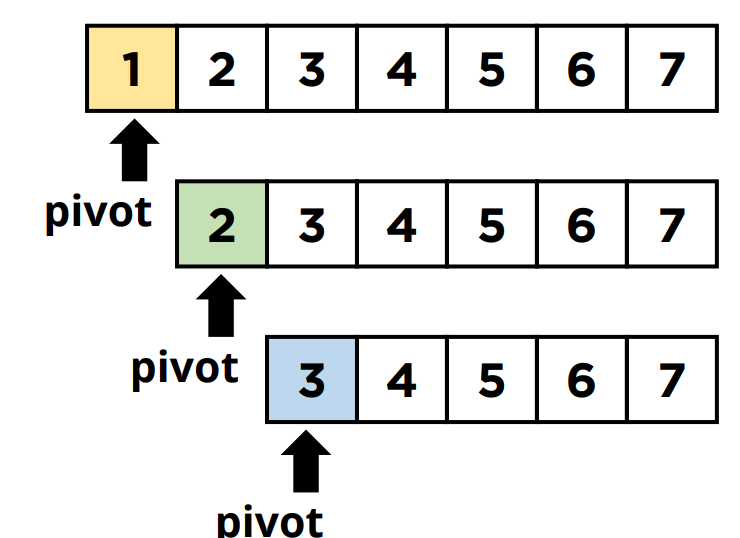
- 주어진 배열에서 최솟값을 찾는다. 배열의 첫 번째 원소를 최솟값으로 가정하고, 이보다 작은 값이 있으면 최솟값을 해당 원소로 업데이트한다.
- 최솟값을 찾았다면, 해당 최솟값을 배열의 첫 번째 원소와 위치를 바꾼다.
- 이제 첫 번째 원소는 정렬이 완료된 상태이므로, 다음 위치에 대해 최솟값을 찾고 해당 위치의 원소와 위치를 바꾼다. 이를 배열의 끝까지 반복한다.
1-2. 자바 구현
SelectionSort
package com.example.datastructure.Sort;
public class SelectionSort implements ISort {
@Override
public void sort(int[] arr) {
for(int i = 0; i < arr.length - 1 ; i++){
int minIndex = i;
for(int j = i + 1; j < arr.length; j++){
if(arr[minIndex] > arr[j]){
minIndex = j;
}
}
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
}1-3. 시간 복잡도
데이터의 개수가 n개라고 했을 때
첫 번째 회전에서의 비교에서 첫번째 값 ~ n번째 값까지 비교하므로 n-1번
두 번째 회전에서의 비교횟수 두번째 값 ~ n번째 값까지 비교하므로 n-2번
...
(n-1) + (n-2) + .... + 2 + 1 → n(n-1)/2
즉 주어진 n개의 배열을 정렬하는데 필요한 시간복잡도는 O(n²)입니다.
최선, 평균, 최악의 경우 모두 동일한 시간복잡도를 가집니다.
2. 버블 정렬(Bubble Sort)
인접한 두 개의 원소를 비교하면서 큰 값을 오른쪽으로 이동시키거나 작은 값을 왼쪽으로 이동시켜 배열을 정렬한다.
2-1. 과정
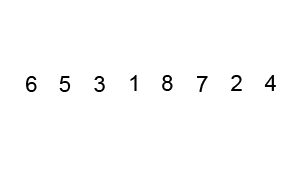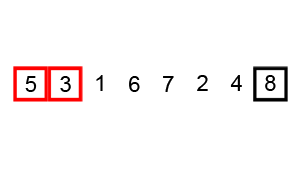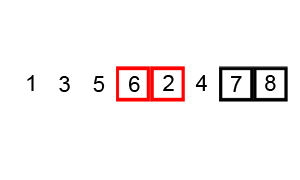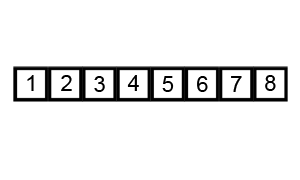
- 배열의 첫 번째 원소부터 마지막 원소까지 순차적으로 인접한 원소와 비교한다.
- 만약 인접한 두 원소의 순서가 잘못되어 있다면, 큰 값을 오른쪽으로 이동시키거나 작은 값을 왼쪽으로 이동시켜 위치를 바꾼다.
- 배열의 마지막 원소까지 위의 과정을 반복한다.
- 한 번의 반복이 끝나면 배열의 가장 큰 원소가 맨 오른쪽에 위치하게 된다.
- 이제 가장 큰 원소가 마지막에 정렬되었으므로, 다시 첫 번째 원소부터 마지막 원소 전까지 반복하여 정렬을 진행한다.
2-2. 자바 구현
BubbleSort
package com.example.datastructure.Sort;
public class BubbleSort implements ISort{
@Override
public void sort(int[] arr) {
// 안정 정렬
// 인플레이스 정렬
for(int i = 0; i < arr.length - 1; i++){
for(int j = 0; j < arr.length - 1 - i; j++){
if(arr[j] > arr[j+1]){
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
}
2-3. 시간 복잡도
데이터의 개수가 n개라고 했을 때
첫 번째 회전에서
첫번째 값과 두번째 값, 두번째 값과 세번째 값... n-1번째값과 n번째 값을 비교하여 총 n-1번 비교
두 번째 회전에서
첫번째 값과 두번째 값, 두번째 값과 세번째 값... n-2번째값과 n-1번째 값을 비교하여 총 n-2번 비교
...
(n-1) + (n-2) + .... + 2 + 1 → n(n-1)/2
즉 주어진 n개의 배열을 정렬하는데 필요한 시간복잡도는 O(n²)입니다.
최선, 평균, 최악의 경우 모두 동일한 시간복잡도를 가집니다.
3. 삽입 정렬(Insert Sort)
주어진 배열을 정렬된 부분과 정렬되지 않은 부분으로 나누고, 정렬되지 않은 부분의 원소를 정렬된 부분의 올바른 위치에 삽입하여 배열을 정렬한다.
3-1. 과정
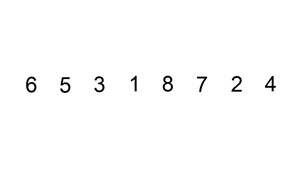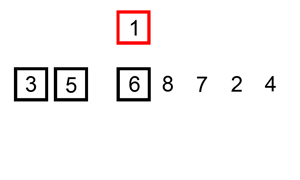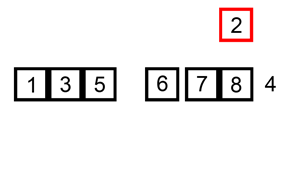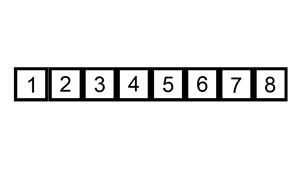
- 배열의 첫 번째 원소는 이미 정렬된 부분으로 간주한다. 따라서 두 번째 원소부터 시작하여 정렬되지 않은 부분의 첫 번째 원소를 선택한다.
- 선택된 원소를 정렬된 부분의 올바른 위치에 삽입한다. 이를 위해 정렬된 부분의 끝에서부터 선택된 원소와 비교하면서 삽입할 위치를 찾는다.
- 삽입할 위치를 찾았다면, 해당 위치에서부터 선택된 원소의 위치까지 모든 원소를 한 칸씩 오른쪽으로 이동시킨다.
- 선택된 원소를 찾은 위치에 삽입한다.
- 정렬되지 않은 부분의 다음 원소를 선택하여 위의 과정을 반복한다.
3-2. 자바 구현
InsertionSort
package com.example.datastructure.Sort;
public class InsertionSort implements ISort{
@Override
public void sort(int[] arr) {
for(int i = 1; i< arr.length; i++){
int key = arr[i]; // 삽입 위치를 찾아줄 데이터
int j = i - 1;
while(j >= 0 && arr[j] > key){
arr[j+1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
}
3-3. 시간 복잡도
데이터의 개수가 n개라고 했을 때
-
최선의 경우 : O(n)
비교 횟수 : (n-1)번
앞의 값들이 모두 정렬되어 있으므로 바로 앞의 원소와 동일하게 1번의 비교만 이루어집니다. -
최악의 경우(자료가 역순인 경우) : O(n²)
비교 횟수
첫번째 타겟과(두 번째에서 시작) 그 앞인 첫 번째 값을 비교하여 1번
두번째 타겟과 첫 번째, 두 번째 값과 비교하여 2번
...
마지막 타겟과 그 앞의 값들을 비교하여 n-1번
따라서 1 + 2 + .... + (n-2) + (n-1) → n(n-1)/2 입니다.
4. 병합 정렬(Merge Sort)
분할 정복(Divide and Conquer) 방법을 사용하여 배열을 정렬한다. 배열을 절반으로 분할한 뒤 각각의 부분 배열을 재귀적으로 정렬한 후, 정렬된 부분 배열을 병합하여 최종적으로 정렬된 배열을 얻는 방식이다.
- 분할 정복(divide and conquer) 방법
문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.
재귀 함수에 대해서 잠깐 알아보고 가겠다.
재귀 함수를 호출하면 다음과 같은 과정이 반복된다.
- 함수가 호출되면 현재 실행 상태(변수 값 등)가 스택 메모리에 저장된다.
- 함수는 주어진 작업을 수행한다. 이때, 다른 함수(자기 자신)를 호출할 수 있다.
- 새로 호출된 함수는 스택의 맨 위에 쌓이게 된다. 호출된 함수는 현재 실행 중인 함수에 의해 제어권을 넘겨받는다.
- 호출된 함수는 다시 1단계부터 반복하여 실행되며, 새로운 호출이 발생하면 스택에 쌓인다.
- 기저 조건이 충족되면 (재귀 호출이 멈추는 조건, base case) 재귀 호출을 더 이상 수행하지 않고 스택의 맨 위의 함수가 반환된다.
- 스택의 맨 위에서부터 차례대로 반환되며, 각 호출된 함수는 이전 호출에서 반환된 지점으로 돌아가게 된다.
package com.example.datastructure.Sort;
public class RecursiveSum {
public static int recursiveSum(int n){
if(n <= 0) { // 기저 조건
return 0;
}else{
return n + recursiveSum(n - 1); // 자기 자신을 호출하면서 n-1에 대한 합을 구함
}
}
public static void main(String[] args) {
int result = recursiveSum(5);
System.out.println(result); // 출력 결과 15
}
}
함수 호출과정
- recursive_sum(5) 호출
n이 5이므로 else 블록으로 이동하여 5 + recursive_sum(4) 계산 - recursive_sum(4) 호출
n이 4이므로 else 블록으로 이동하여 4 + recursive_sum(3) 계산 - recursive_sum(3) 호출
n이 3이므로 else 블록으로 이동하여 3 + recursive_sum(2) 계산 - recursive_sum(2) 호출
n이 2이므로 else 블록으로 이동하여 2 + recursive_sum(1) 계산 - recursive_sum(1) 호출
n이 1이므로 else 블록으로 이동하여 1 + recursive_sum(0) 계산 - recursive_sum(0) 호출
n이 0이므로 if 블록으로 이동하여 0 반환
역순으로 함수 호출이 해제되며 결과가 계산됩니다:
- recursive_sum(0): 0 반환
- recursive_sum(1): 1 + 0 = 1 반환
- recursive_sum(2): 2 + 1 = 3 반환
- recursive_sum(3): 3 + 3 = 6 반환
- recursive_sum(4): 4 + 6 = 10 반환
- recursive_sum(5): 5 + 10 = 15 반환
4-1. 과정
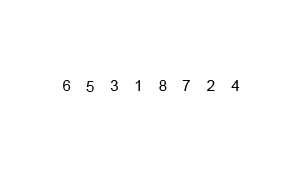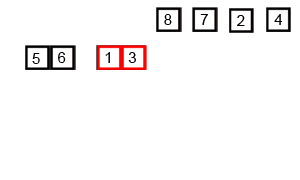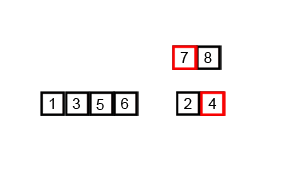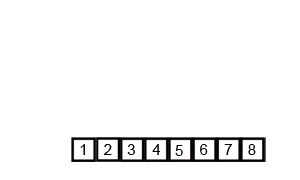
- 리스트의 길이가 1 이하이면 이미 정렬된 것으로 본다. 그렇지 않은 경우에는
- 분할(divide): 정렬되지 않은 리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.
- 정복(conquer): 각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.
- 결합(combine): 두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다. 이때 정렬 결과가 임시배열에 저장된다.
- 복사(copy): 임시 배열에 저장된 결과를 원래 배열에 복사한다.
4-2. 자바 구현
MergeSort
package com.example.datastructure.Sort;
import java.util.Arrays;
public class MergeSort implements ISort{
@Override
public void sort(int[] arr) {
// in-place sort
mergeSort(arr, 0, arr.length - 1);
}
private void mergeSort(int[] arr, int low, int high) {
if (low >= high) {
return; // base case
}
int mid = low + ((high - low) / 2);
System.out.println("mergeSort(arr, " + low + ", " + high + ")");
mergeSort(arr, low, mid);
mergeSort(arr, mid + 1, high);
merge(arr, low, mid, high);
}
private void merge(int[] arr, int low, int mid, int high){
int[] temp = new int[high - low + 1];
int idx = 0;
int left = low;
int right = mid + 1;
while(left <= mid && right <= high){
if(arr[left] <= arr[right]){
temp[idx] = arr[left];
left++;
}else {
temp[idx] = arr[right];
right++;
}
idx++;
}
while(left <= mid){
temp[idx] = arr[left];
idx++;
left++;
}
while(right <= high){
temp[idx] = arr[right];
idx++;
right++;
}
for(int i = low; i <= high; i++){
arr[i] = temp[i - low];
}
}
}Main
package com.example.datastructure.Sort;
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
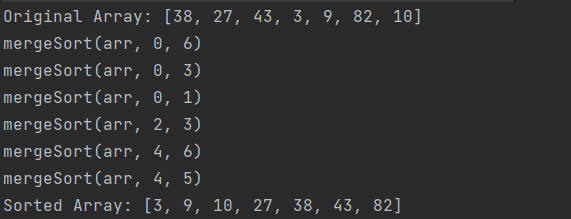
int[] arr = {38, 27, 43, 3, 9, 82, 10};
MergeSort mergeSort = new MergeSort();
System.out.println("Original Array: " + Arrays.toString(arr));
mergeSort.sort(arr);
System.out.println("Sorted Array: " + Arrays.toString(arr));
}
}결과
조금 더 자세히 알아보자.
- 초기 배열: [38, 27, 43, 3, 9, 82, 10]
- 배열을 반으로 나눔: [38, 27, 43], [3, 9, 82, 10]
- 왼쪽 부분 배열 정렬: [27, 38, 43], [3, 9, 10, 82]
- 병합: [3, 9, 10, 27, 38, 43, 82]
재귀 함수 호출 과정

병합 과정에서는 어떻게 되는 걸까?
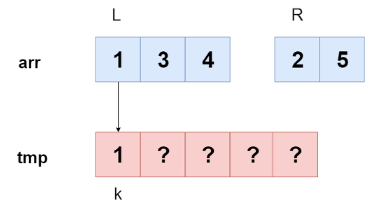
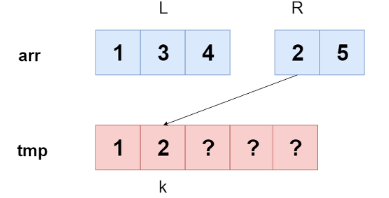
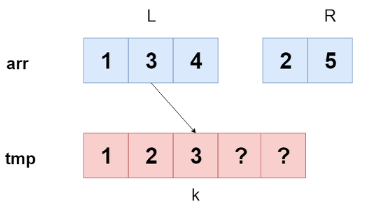
이런 방식으로 왼쪽 부분 배열과 오른쪽 부분 배열의 원솔르 비교해서 더 작은 값이 복사되고 L, K를 하나씩 증가한다.
만약 숫자가 남아 있다면 이미 정렬된 상태이기 때문에 남은 값을 그대로 복사해서 넣어 준다.
4-3. 시간 복잡도
정렬 과정에서 n개의 요소를 계속해서 반으로 나누는데, 이러한 분할은 log n번 이루어집니다. 그리고 각 단계에서 병합 작업을 수행하는 데에는 최대 O(n)의 시간이 소요된다.
따라서 병합 정렬의 시간 복잡도는 O(n log n)으로 나타낼 수 있습니다.
5. 퀵 정렬(Quick Sort)
퀵 정렬은 평균적으로 매우 빠른 속도를 자랑하는 정렬 방법이다. 퀵 정렬(Quick Sort)은 분할 정복(Divide and Conquer) 방식의 정렬 알고리즘으로 기준점을 기준으로 배열을 두 개의 부분으로 분할하고, 각각을 재귀적으로 정렬하여 최종적으로 정렬된 배열을 얻는다.
5-1. 과정
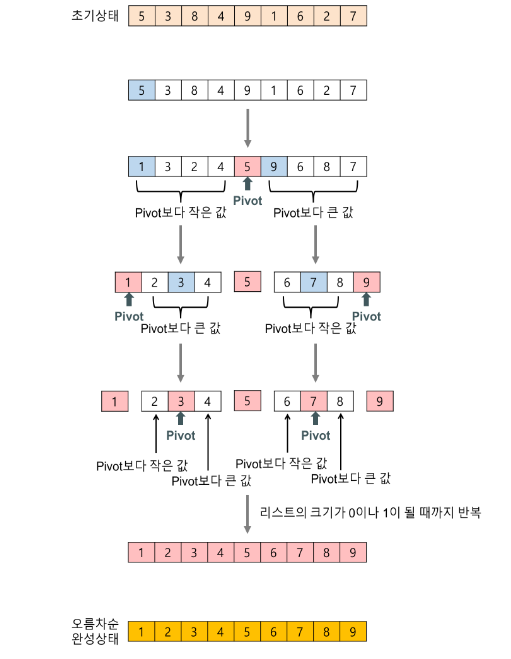
하나의 리스트를 피벗(pivot)을 기준으로 두 개의 비균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음, 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법이다.
퀵 정렬은 다음의 단계들로 이루어진다.
- 분할(Divide): 입력 배열을 피벗을 기준으로 비균등하게 2개의 부분 배열(피벗을 중심으로 왼쪽: 피벗보다 작은 요소들, 오른쪽: 피벗보다 큰 요소들)로 분할한다.
- 정복(Conquer): 부분 배열을 정렬한다. 부분 배열의 크기가 충분히 작지 않으면 순환 호출 을 이용하여 다시 분할 정복 방법을 적용한다.
- 결합(Combine): 정렬된 부분 배열들을 하나의 배열에 합병한다.
순환 호출이 한번 진행될 때마다 최소한 하나의 원소(피벗)는 최종적으로 위치가 정해지므로, 이 알고리즘은 반드시 끝난다는 것을 보장할 수 있다.
5-2. 자바 구현
QuickSort
package com.example.datastructure.Sort;
public class QuickSort implements ISort{
@Override
public void sort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
private void quickSort(int[] arr, int low, int high){
if(low >= high){
return;
}
int pivot = low + ((high - low) / 2);
int pivotValue = arr[pivot];
int left = low;
int right = high;
while(left <= right){
while(arr[left] < pivotValue){
left++;
}
while(arr[right] > pivotValue){
right--;
}
if(left <= right){
int tmp = arr[right];
arr[right] = arr[left];
arr[left] = tmp;
left++;
right--;
}
}
quickSort(arr, low, right);
quickSort(arr, low, high);
}
}5-3. 시간 복잡도
분할 과정은 배열을 평균적으로 반으로 나누기 때문에 log n번 수행됩니다. 그리고 각 분할 단계에서 기준점을 기준으로 왼쪽과 오른쪽 부분 배열에 요소를 배치하는 작업은 평균적으로 O(n)의 시간이 소요됩니다.
따라서 평균 시간 복잡도는 O(n log n)이 되는 것입니다. 이러한 시간 복잡도 때문에 퀵 정렬은 대부분의 경우에 매우 빠른 속도로 정렬을 수행합니다.
하지만 최악의 경우에는 시간 복잡도가 O(n^2)이 될 수 있습니다. 최악의 경우는 기준점(pivot)이 항상 최솟값 또는 최댓값으로 선택되는 경우로, 이미 정렬되어 있는 배열이나 거의 정렬된 배열에 대해 발생할 수 있습니다.
최악의 경우