
- 마이크로미터 소개
- 메트릭 확인하기
- 다양한 메트릭
- 프로메테우스
- 그라파나
1. 마이크로미터 소개
서비스를 운영할 때는 애플리케이션의 CPU, 메모리, 커넥션 사용, 고객 요청수 같은 수 많은 지표들을 확인하는 것이 필요하다. 그래야 어디에 어떤 문제가 발생했는지 사전에 대응도 할 수 있고, 실제 문제가 발생해도 원인을 빠르게 파악해서 대처할 수 있다.
이러한 모니터링 툴도 여러가지가 있다. 그런데 중간에 사용하는 모니터링 툴을 변경하면 기존 측정 코드들도 다시 변경해야 되는 문제가 있다. 이런 문제를 해결하는 것이 바로 마이크로미터(Micrometer)라는 라이브러리이다.
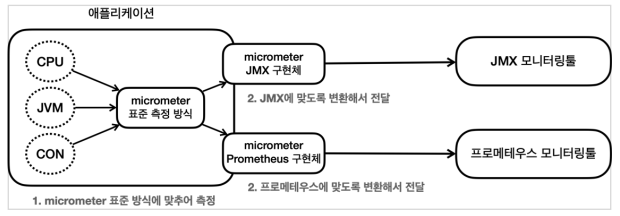
- 마이크로미터는 애플리케이션 메트릭 파사드라고 불리는데, 애플리케이션의 메트릭(측정 지표)을 마이크로미터가 정한 표준 방법으로 모아서 제공해준다.
- 개발자는 마이크로미터가 정한 표준 방법으로 메트릭(측정 지표)를 전달하면 된다. 그리고 사용하는 모니터링 툴에 맞는 구현체를 선택하면 된다. 이후에 모니터링 툴이 변경되어도 해당 구현체만 변경하면 된다. 애플리케이션 코드는 모니터링 툴이 변경되어도 그대로 유지할 수 있다.
마이크로미터 공식 메뉴얼
https://micrometer.io/docs
2. 메트릭 확인하기
- CPU, JVM, 커넥션 사용 등등 수 많은 지표들을 어떻게 수집할까?
- 마이크로미터는 다양한 지표 수집 기능을 이미 만들어서 제공한다.
한번 확인해보자.
localhost:8080/actuator/metrics 실행
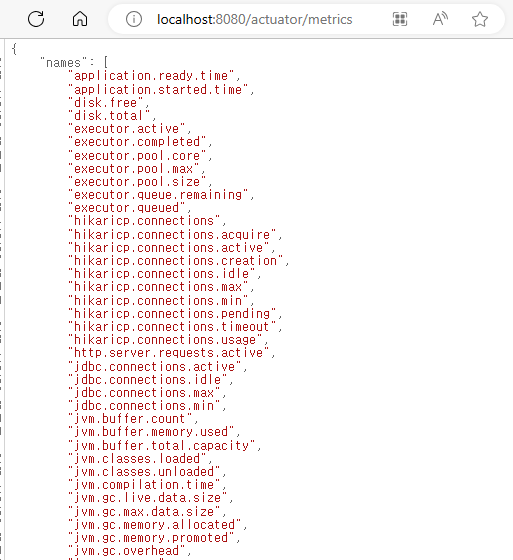
- 많은 정보들이 제공된다.
http://localhost:8080/actuator/metrics/{name}형식으로 자세히 확인 할 수 있다.
Tag 필터
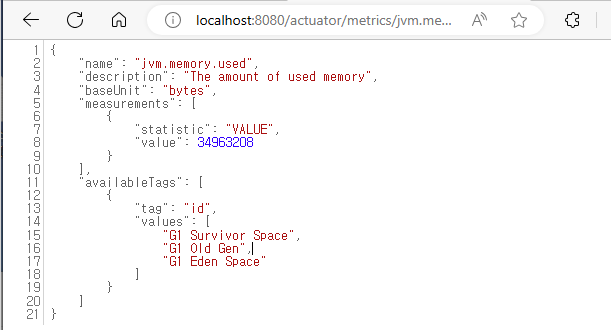
availableTags를 보면 다음과 같은 항목을 확인할 수 있다.tag:area,values[heap, nonheap]tag:id,values[G1 Survivor Space, ...]- 해당 Tag를
tag=KEY:VALUE와 같은 형식으로 필터링해서 확인 할 수 있다.
Ex)
- localhost:8080/actuator/metrics/jvm.memory.used?tag=area:heap
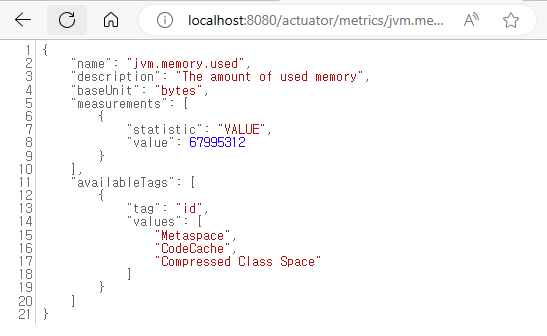
- localhost:8080/actuator/metrics/jvm.memory.used?tag=area:nonheap
3. 다양한 메트릭
마이크로미터와 액츄에이터가 기본으로 제공하는 다양한 메트릭(더 많은 메트릭이 있다.)
- JVM 메트릭
- 시스템 메트릭
- 애플리케이션 시작 메트릭
- 스프링 MVC 메트릭
- 톰캣 메트릭
- 데이터 소스 메트릭
- 로그 메트릭
JVM 메트릭
- JVM 관련 메트릭을 제공한다.
jvm.으로 시작 - 메모리 및 버퍼 풀 세부 정보
- 가비지 수집 관련 통계
- 스레드 활용
- 로드 및 언로드된 클래스 수
- JVM 버전 정보
- JIT 컴파일 시간
시스템 메트릭
- 시스템 메트릭을 제공한다.
system.,process.,disk.으로 시작 - CPU 지표
- 파일 디스크립터 메트릭
- 가동 시간 메트릭
- 사용 가능한 디스크 공간
애플리케이션 시작 메트릭
- 애플리케이션 시작 시간 메트릭을 제공
application.started.time: 애플리케이션을 시작하는데 걸리는 시간 (ApplicationStartedEvent로 측정)application.ready.time: 애플리케이션이 요청을 처리할 준비가 되는데 걸리는 시간 (ApplicationReadyEvent로 측정)
스프링 MVC 메트릭
- 스프링 MVC 컨트롤러가 처리하는 모든 요청을 다룸
http.server.requests TAG를 사용해서 다음 정보를 분류해서 확인가능uri: 요청 URImethod: GET , POST 같은 HTTP 메서드status: 200 , 400 , 500 같은 HTTP Status 코드exception: 예외outcome: 상태코드를 그룹으로 모아서 확인1xx:INFORMATIONAL,2xx:SUCCESS,3xx:REDIRECTION,4xx:CLIENT_ERROR,5xx:SERVER_ERROR
데이터소스 메트릭
DataSource, 커넥션 풀에 관한 메트릭을 확인jdbc.connections.- 최대 커넥션, 최소 커넥션, 활성 커넥션, 대기 커넥션 수 등을 확인가능
로그 메트릭
- logback 로그에 대한 메트릭을 확인가능
trace,debug,info,warn,error각각의 로그 레벨에 따른 로그 수를 확인가능
톰캣 메트릭
- 톰캣 메트릭은
tomcat.으로 시작 - 톰캣 메트릭을 모두 사용하려면 다음 옵션을 켜야한다.
server:
tomcat:
mbeanregistry:
enabled: true- 톰캣의 최대 쓰레드, 사용 쓰레드 수를 포함한 다양한 메트릭을 확인가능
지원하는 다양한 메트릭
https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.metrics.supported
4. 프로메테우스
4-1. 소개
프로메테우스
애플리케이션에서 발생한 메트릭을 그 순간만 확인하는 것이 아니라 과거 이력까지 함께 확인하려면 메트릭을 보관하는 DB가 필요하다. 이렇게 하려면 어디선가 메트릭을 지속해서 수집하고 DB에 저장해야 한다. 프로메테우스가 바로 이런 역할을 담당한다.
그라파나
프로메테우스가 DB라고 하면, 이 DB에 있는 데이터를 불러서 사용자가 보기 편하게 보여주는 대시보드가 필요하다. 그라파나는 매우 유연하고, 데이터를 그래프로 보여주는 툴이다. 수 많은 그래프를 제공하고, 프로메테우스를 포함한 다양한 데이터소스를 지원한다.
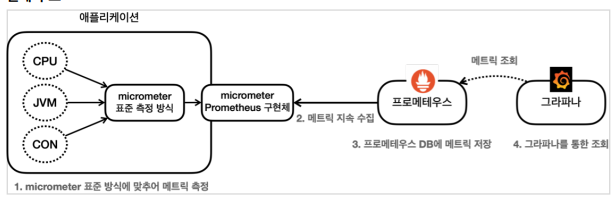
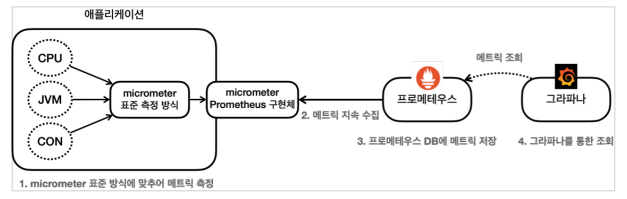
- 스프링 부트 액츄에이터와 마이크로미터를 사용하면 수 많은 메트릭을 자동으로 생성한다. 마이크로미터 프로메테우스 구현체는 프로메테우스가 읽을 수 있는 포멧으로 메트릭을 생성한다.
- 프로메테우스는 이렇게 만들어진 메트릭을 지속해서 수집한다.
- 프로메테우스는 수집한 메트릭을 내부 DB에 저장한다.
- 사용자는 그라파나 대시보드 툴을 통해 그래프로 편리하게 메트릭을 조회한다. 이때 필요한 데이터는 프로메테우스를 통해서 조회한다
4-2. 애플리케이션 설정
윈도우를 사용하기 때문에
https://github.com/prometheus/prometheus/releases/download/v2.42.0/prometheus-2.42.0.windows-amd64.zip 를 통해 다운로드
localhost:9090
필요 설정
1. 애플리케이션 설정: 프로메테우스가 애플리케이션의 메트릭을 가져갈 수 있도록 애플리케이션에서 프로메테우스 포멧에 맞추어 메트릭 만들기
2. 프로메테우스 설정: 프로메테우스가 우리 애플리케이션의 메트릭을 주기적으로 수집하도록 설정
애플리케이션 설정
build.gradle 추가
implementation 'io.micrometer:micrometer-registry-prometheus' //추가- 마이크로미터 프로메테우스 구현 라이브러리를 추가한다.
- 스프링 부트와 액츄에이터가 자동으로 마이크로미터 프로메테우스 구현체를 등록해서 동작하도록 설정해준다.
localhost:8080/actuator/prometheus 실행
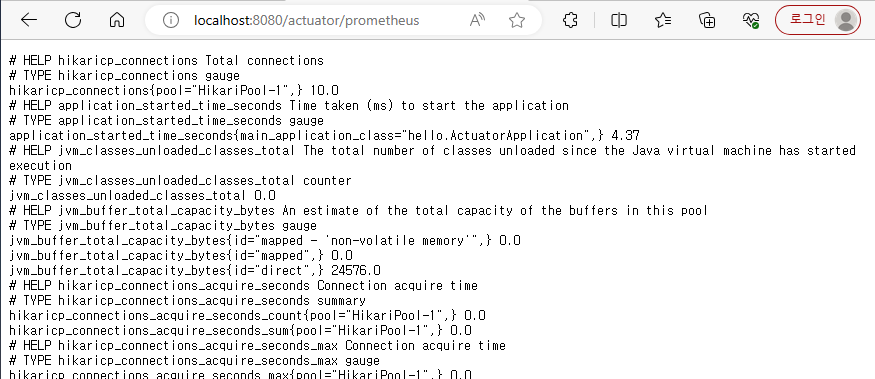
- 메트릭이 프로메테우스 포멧으로 만들어 진 것을 확인할 수 있다.
포멧 차이
jvm.info -> jvm_info: 프로메테우스는 .대신에 _포멧을 사용한다. .대신에 _포멧으로 변환된 것을 확인할 수 있다.
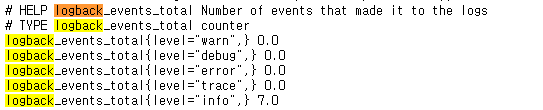
Ex) logback.events -> logback_events_total
-
logback.events
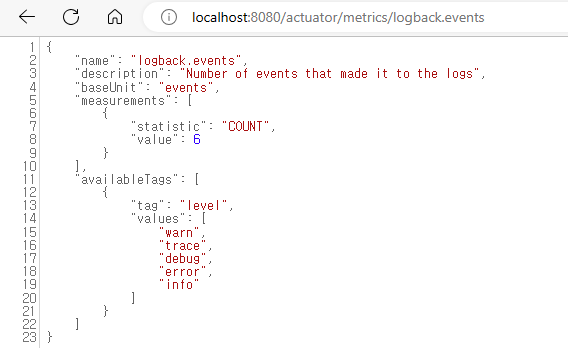
-
logback_events_total
4-3. 수집 설정
프로메테우스가 애플리케이션의 /actuator/prometheus를 호출해서 메트릭을 주기적으로 수집하도록 설정해보자
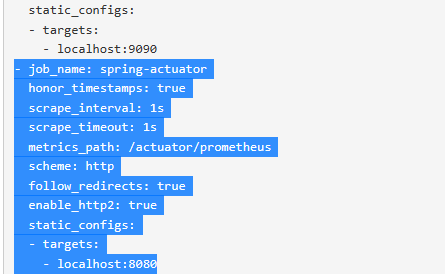
prometheus.yml 파일 추가
#추가
- job_name: "spring-actuator"
metrics_path: '/actuator/prometheus'
scrape_interval: 1s
static_configs:
- targets: ['localhost:8080']프로메테우스는 다음 경로를 1초에 한번씩 호출해서 애플리케이션의 메트릭들을 수집한다.
localhost:8080/actuator/prometheus
- 앞의 띄어쓰기 2칸에 유의
job_name: 수집하는 이름이다. 임의의 이름을 사용하면 된다.metrics_path: 수집할 경로를 지정한다.scrape_interval: 수집할 주기를 설정한다.targets: 수집할 서버의 IP, PORT를 지정한다.
localhost:9090/config 확인
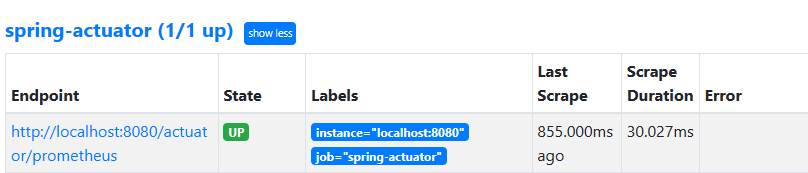
prometheus: 프로메테우스 자체에서 제공하는 메트릭 정보이다. (프로메테우스가 프로메테우스 자신의 메트릭을 확인하는 것이다.)spring-actuator: 우리가 연동한 애플리케이션의 메트릭 정보이다.State가UP으로 되어 있으면 정상이고,DOWN으로 되어 있으면 연동이 안된 것이다.
4-4. 기본 기능
http_server_requests_seconds_count 검색
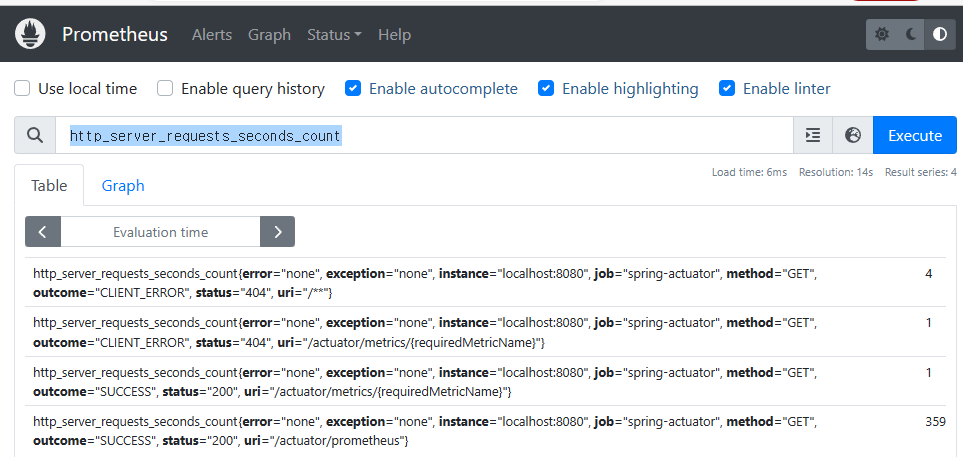
- 태그, 레이블:
error,exception,instance,job,method,outcome,status,uri는 각각의 메트릭 정보를 구분해서 사용하기 위한 태그이다. 마이크로미터에서는 이것을 태그(Tag)라 하고, 프로메테우스에서는 레이블(Label)이라 한다. 여기서는 둘을 구분하지 않고 사용하겠다. - 숫자: 끝에 마지막에 보면
359,4와 같은 숫자가 보인다. 이 숫자가 바로 해당 메트릭의 값이다.
기본 기능
Table->Evaluation time을 수정해서 과거 시간 조회 가능Graph-> 메트릭을 그래프로 조회 가능
필터
레이블을 기준으로 필터를 사용할 수 있다. 필터는 중괄호({}) 문법을 사용
레이블 일치 연산자
=제공된 문자열과 정확히 동일한 레이블 선택!=제공된 문자열과 같지 않은 레이블 선택=~제공된 문자열과 정규식 일치하는 레이블 선택!~제공된 문자열과 정규식 일치하지 않는 레이블 선택
Ex)
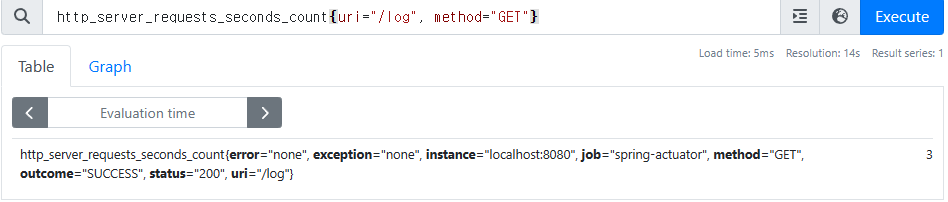
-
uri=/log,method=GET조건으로 필터
http_server_requests_seconds_count{uri="/log", method="GET"}
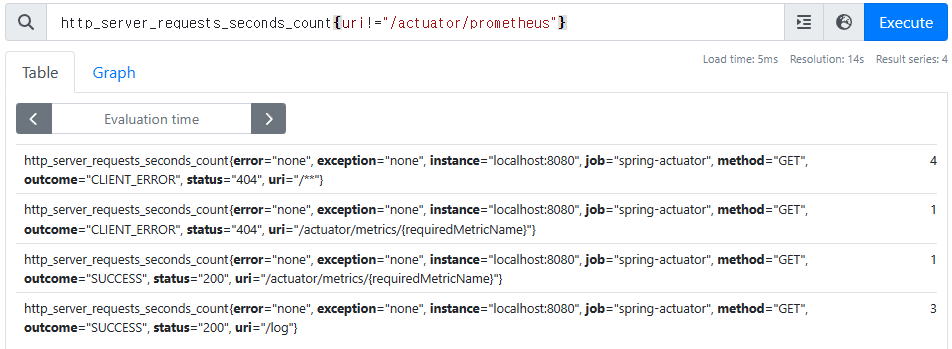
-
/actuator/prometheus는 제외한 조건으로 필터
http_server_requests_seconds_count{uri!="/actuator/prometheus"}
연산자 쿼리와 함수
+(덧셈)-(빼기)*(곱셈)/(분할)%(모듈로)^(승수/지수)
count
count(http_server_requests_seconds_count)
메트릭 자체의 수 카운트
오프셋 수정자
http_server_requests_seconds_count offset 10m
offset 10m과 같이 나타낸다. 현재를 기준으로 특정 과거 시점의 데이터를 반환한다.
4-5. 게이지와 카운터
메트릭은 크게 게이지 카운터 두가지로 분류 할 수 있다.
게이지(Gauge)
- 임의로 오르내일 수 있는 값
- 예) CPU 사용량, 메모리 사용량, 사용중인 커넥션
카운터(Counter)
- 단순하게 증가하는 단일 누적 값
- 예) HTTP 요청 수, 로그 발생 수
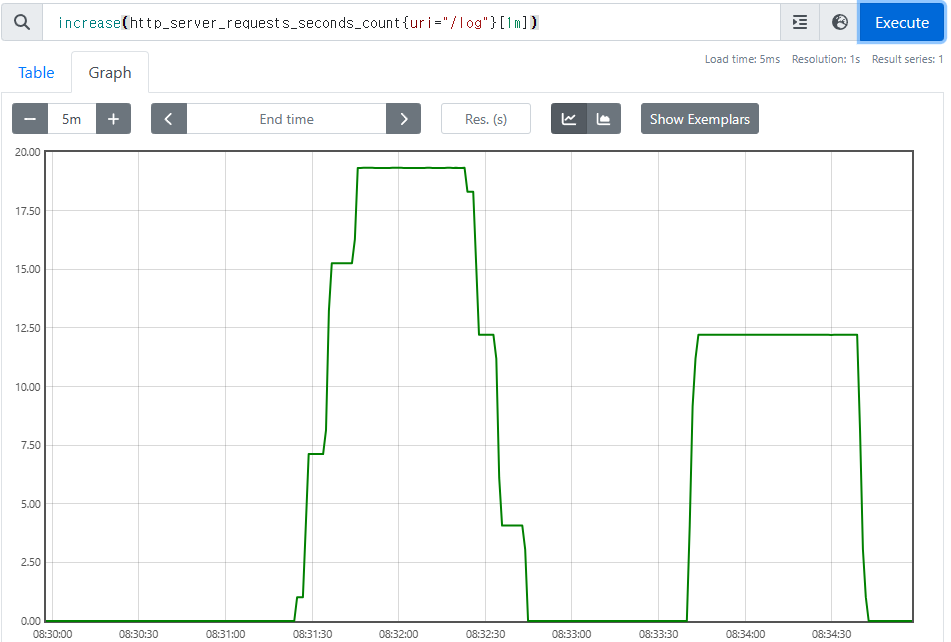
http_server_requests_seconds_count{uri="/log"}
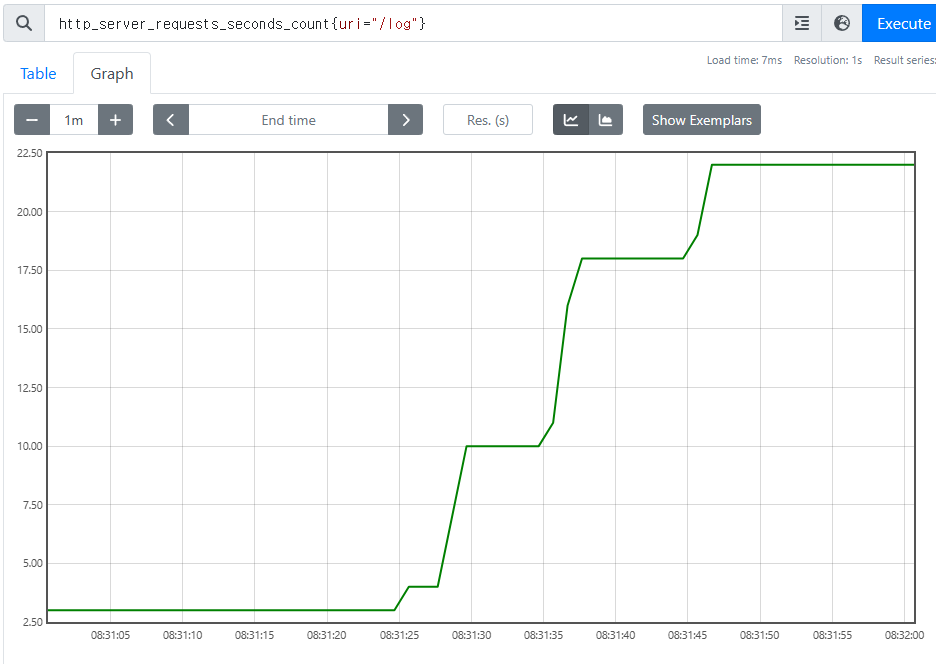
이렇게 증가만 하는 그래프에서는 특정 시간에 얼마나 고객의 요청이 들어왔는지 한눈에 확인하기 매우 어렵다. 이런 문제를 해결하기 위해 increase(), rate()같은 함수를 지원한다.
increase()
- 지정한 시간 단위별로 증가를 확인할 수 있다.
- 마지막에
[시간]을 사용해서 범위 벡터를 선택해야 한다.
Ex)increase(http_server_requests_seconds_count{uri="/log"}[1m])
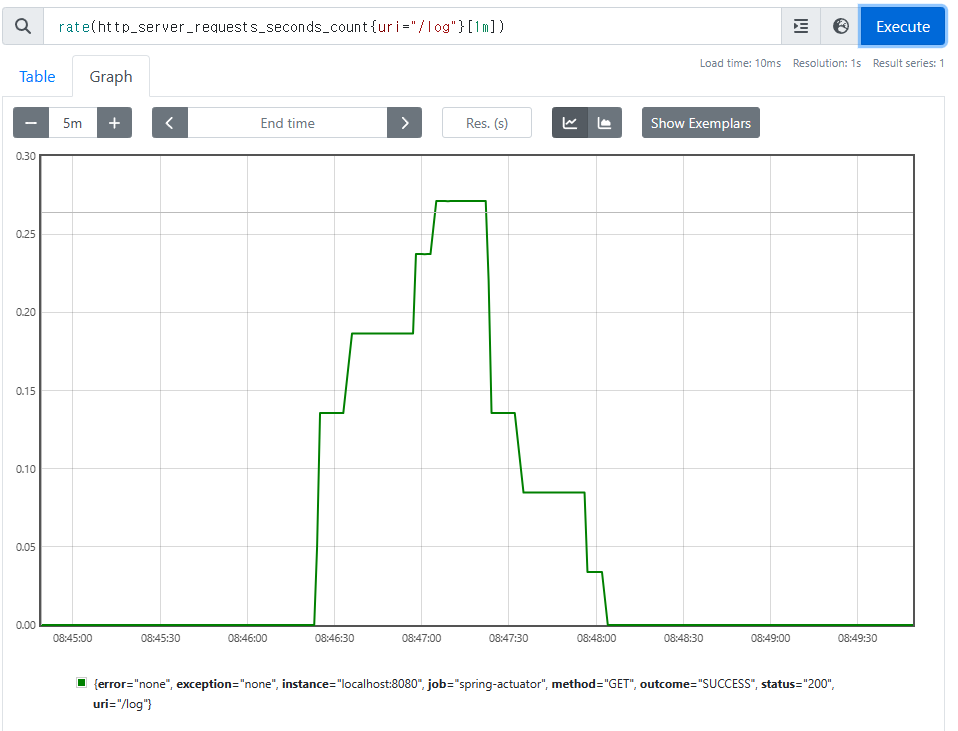
rate()
- 범위 백터에서 초당 평균 증가율을 계산한다.
increase()가 숫자를 직접 카운트 한다면,rate()는 여기에 초당 평균을 나누어서 계산한다.rate(data[1m])에서[1m]이라고 하면 60초가 기준이 되므로 60을 나눈 수이다.
프로메테우스의 단점은 한눈에 들어오는 대시보드를 만들어보기 어렵다는 점이다. 이 부분은 그라파나를 사용하면 된다.
5. 그라파나
5-1. 연동
윈도우 다운로드
https://dl.grafana.com/enterprise/release/grafana-enterprise-9.3.6.windows-amd64.zip
그라파나는 프로메테우스를 통해서 데이터를 조회하고 보여주는 역할을 한다.
연동
- 왼쪽 하단 톱니바퀴 선택
- Add data source 선택
- Prometheus 선택
- URL: http://localhost:9090 설정
- Save & test 선택
5-2. 대시보드 만들기
- 왼쪽 Dashboards 메뉴 선택
- New 버튼 선택 New Dashboard 선택
- 오른쪽 상단의 Save dashboard 저장 버튼(disk 모양) 선택
- Dashboard name: (원하는 name)를 입력하고 저장
패널 만들기
1. 오른쪽 상단의 Add panel 버튼(차트 모양) 선택
2. Add a new panel 메뉴 선택
3. 패널의 정보를 입력할 수 있는 화면이 나타난다.
4. 아래에 보면 Run queries 버튼 오른쪽에 Builder, Code라는 버튼이 보이는데, Code를 선택하자.
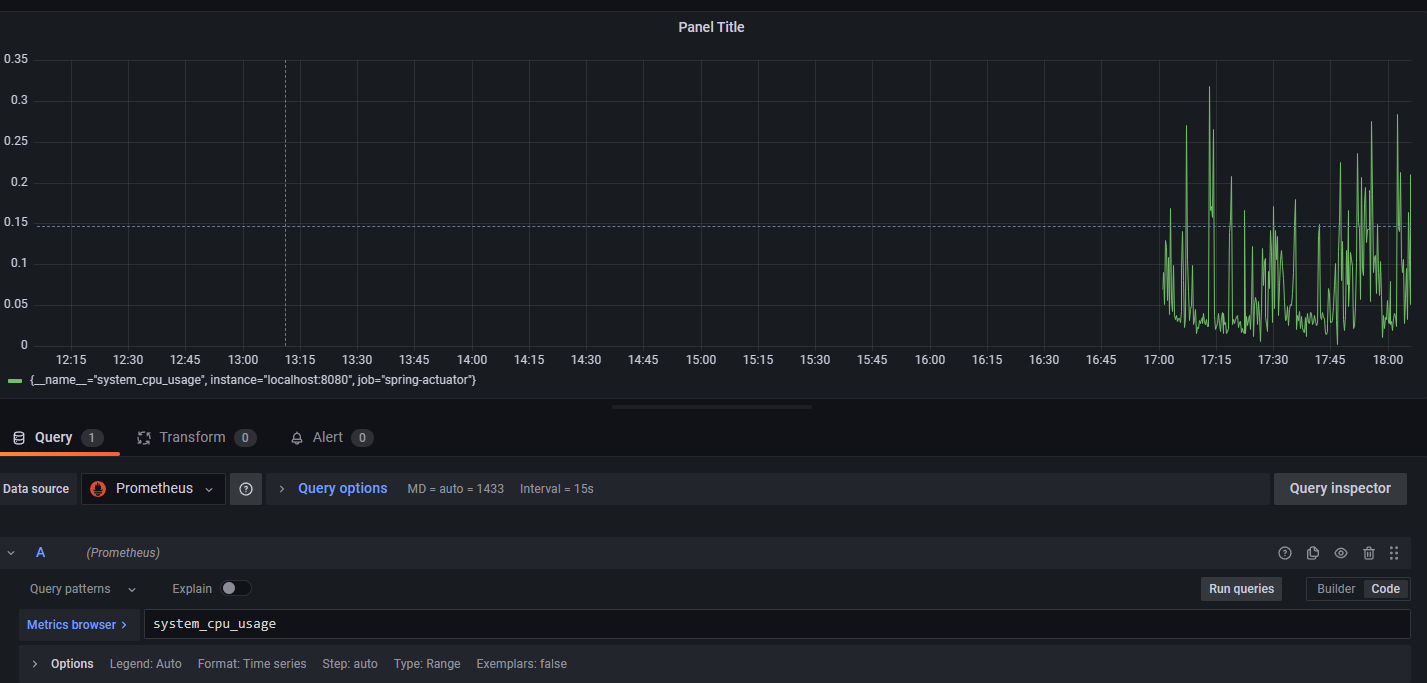
5. Enter a PromQL query... 이라는 부분에 메트릭을 입력하면 된다.
system_cpu_usage 쿼리 입력
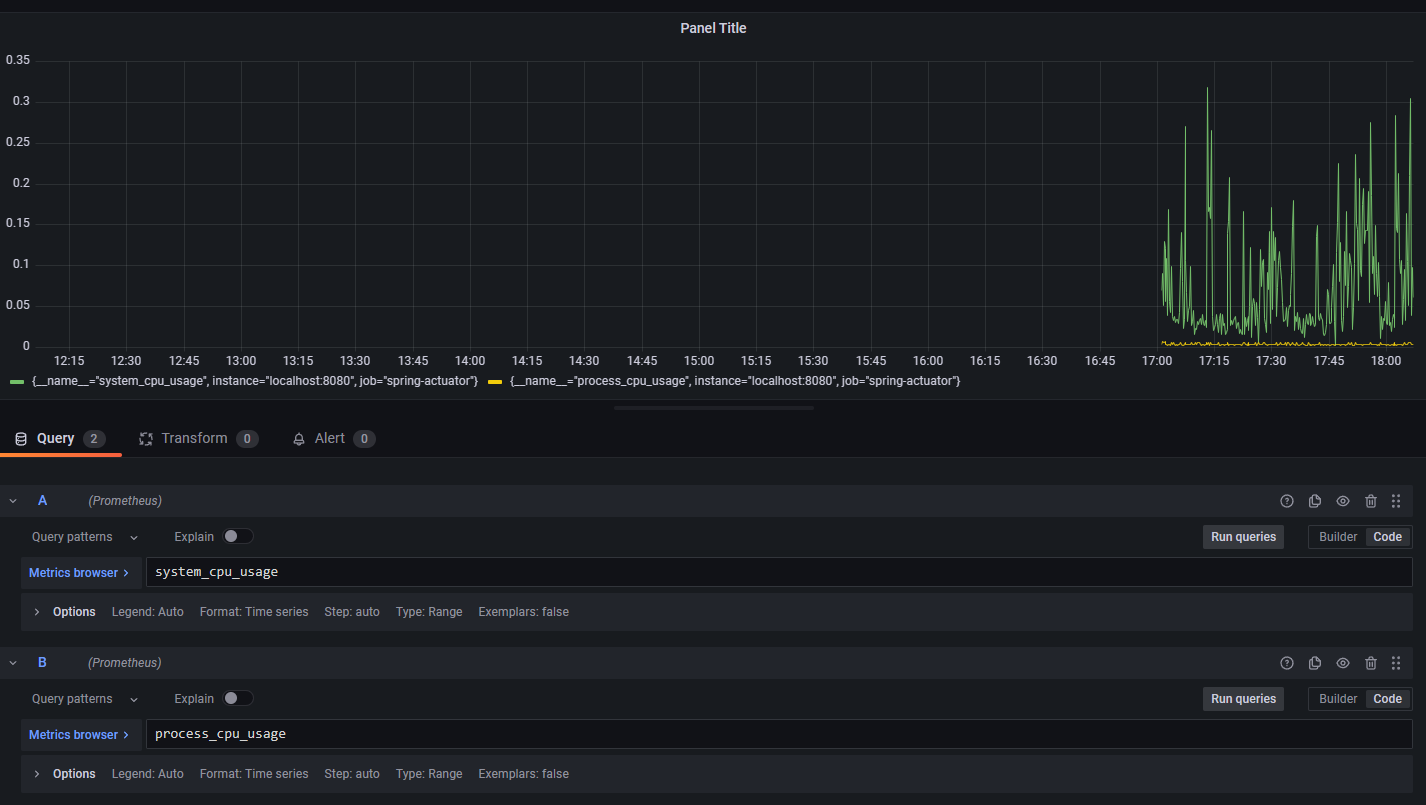
process_cpu_usage 쿼리 추가
- +Query
- process_cpu_usage
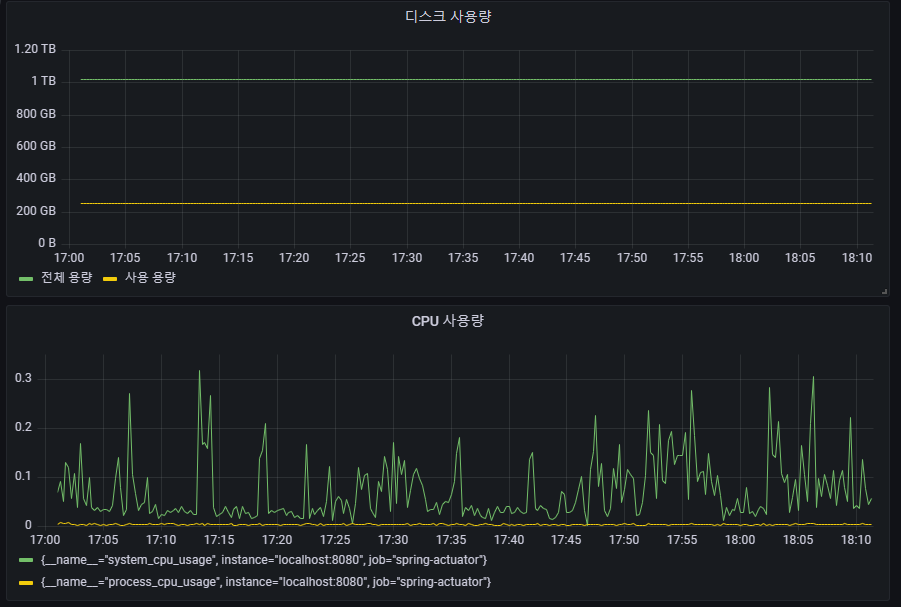
패널 이름 변경 및 저장

디스크 사용량 추가
5-3. 공유 대시보드 활용
https://grafana.com/grafana/dashboards 접속해서 공유 대시보드 확인
스프링 부트 시스템 모니터 대시보드 불러오기
Copy Id to clipboard를 선택하자. 또는ID: 11378이라고 되어 있는 부분의
숫자를 저장하자
- 왼쪽 Dashboards 메뉴 선택
- New 버튼 선택 Import 선택
- 불러올 대시보드 숫자( 11378 )를 입력하고 Load 버튼 선택
- Prometheus 데이터소스를 선택하고 Import 버튼 선택
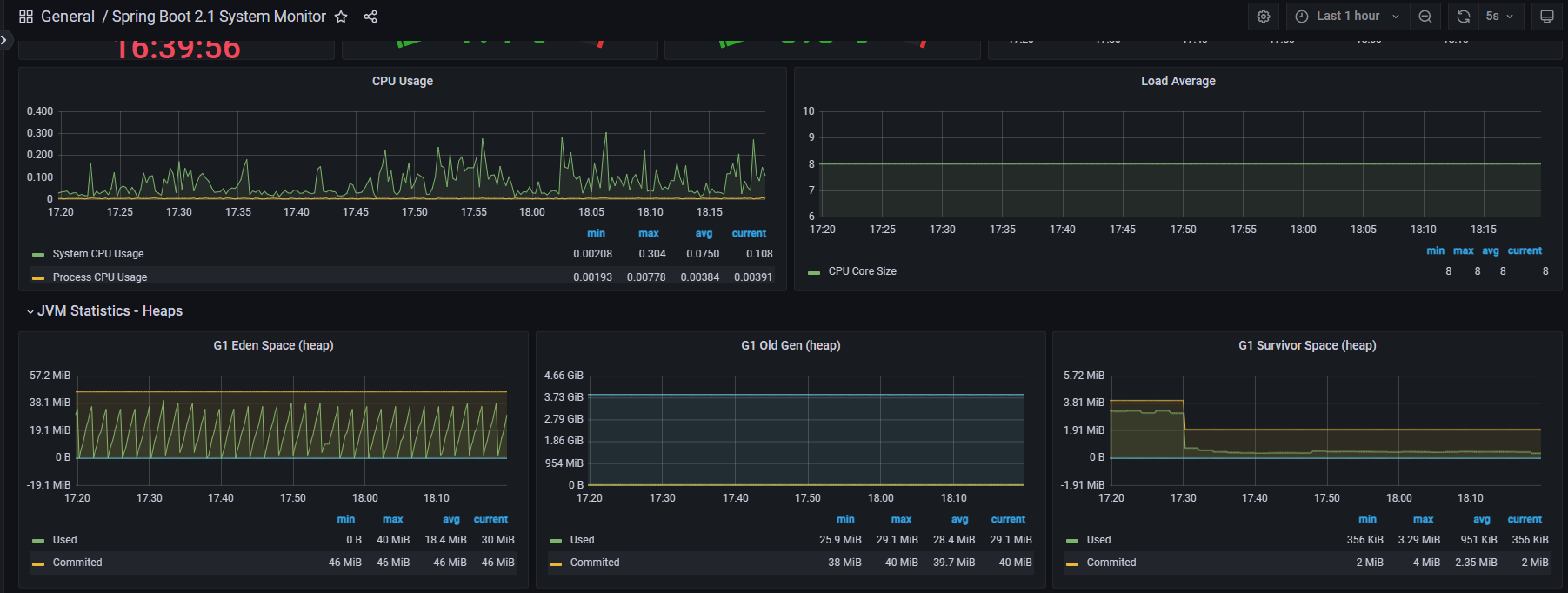
- 수 많은 기능들을 제공한다.
- 이미 잘 만들어진 대시보드를 활용하면 편리하게 모니터링 환경을 구성할 수 있다.
5-4. 메트릭을 통한 문제 확인
애플리케이션에 문제가 발생했을 때 그라파나를 통해서 어떻게 모니터링 하는지 확인해보자.
Ex)
- CPU 사용량 초과
- JVM 메모리 사용량 초과
- 커넥션 풀 고갈
- 에러 로그 급증
CPU 사용량 초과
TrafficController
package hello.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
@RestController
public class TrafficController {
@GetMapping("cpu")
public String cpu() {
log.info("cpu");
long value = 0;
for (long i = 0; i < 1000000000000L; i++) {
value++;
}
return "ok value=" + value;
}
}
localhost:8080/cpu 실행
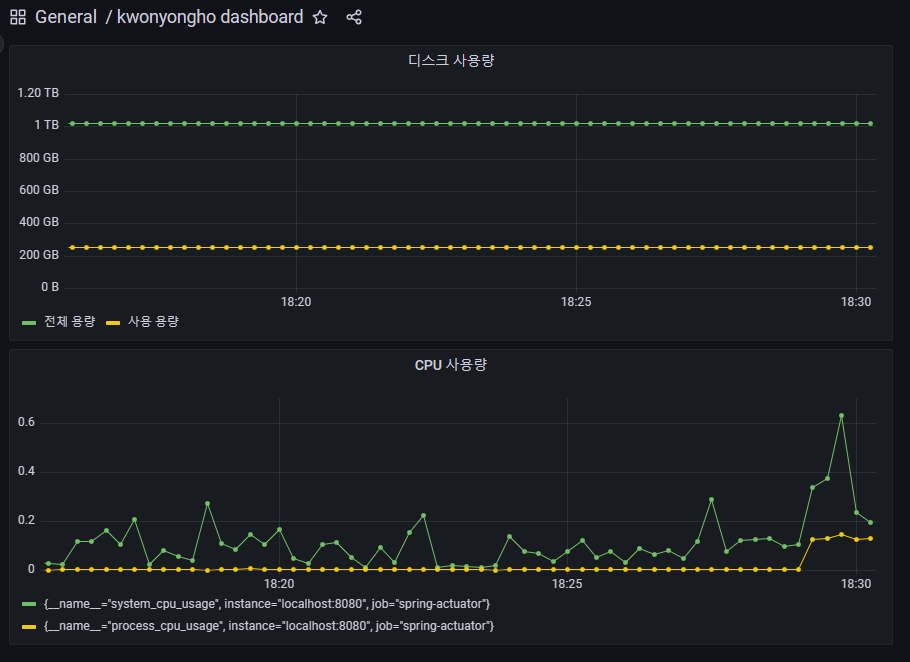
- CPU 사용량이 증가하는 것을 확인할 수 있다.
JVM 메모리 사용량 초과
TrafficController - jvm() 추가
private List<String> list = new ArrayList<>();
@GetMapping("/jvm")
public String jvm() {
log.info("jvm");
for (int i = 0; i < 1000000; i++) {
list.add("hello jvm!" + i);
}
return "ok";
}localhost:8080/jvm 요청
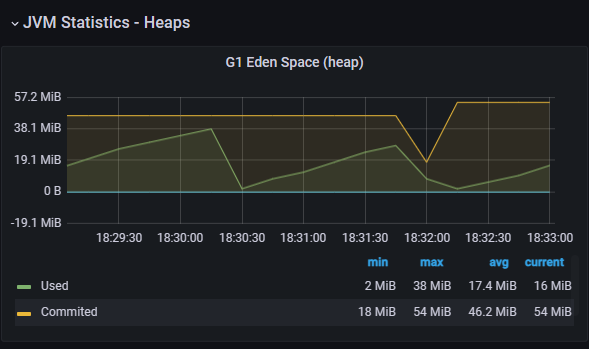
커넥션 풀 고갈
TrafficController - jdbc() 추가
@GetMapping("/jdbc")
public String jdbc() throws SQLException {
log.info("jdbc");
Connection conn = dataSource.getConnection();
log.info("connection info={}", conn);
//conn.close(); //커넥션을 닫지 않는다.
return "ok";
}localhost:8080/jdbc 실행(많이)
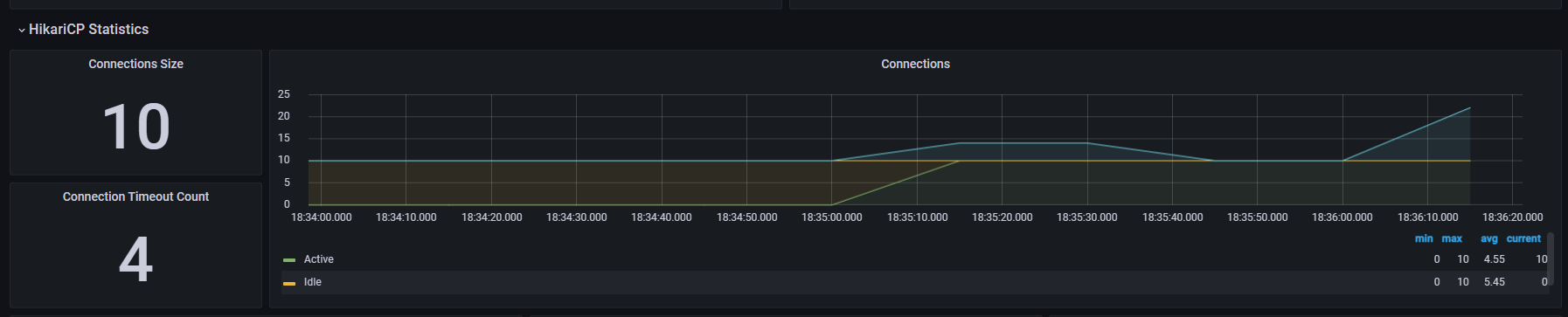
- Active 커넥션이 커넥션 풀의 최대 숫자인 10개를 넘어가게 되면, 커넥션을 획득하기 위해 대기(Pending)하게 된다. 그래서 커넥션 획득 부분에서 쓰레드가 대기하게 되고 결과적으로 HTTP 요청을 응답하지 못한다.
에러 로그 급증
TrafficController - errorLog() 추가
@GetMapping("/error-log")
public String errorLog() {
log.error("error log");
return "error";
}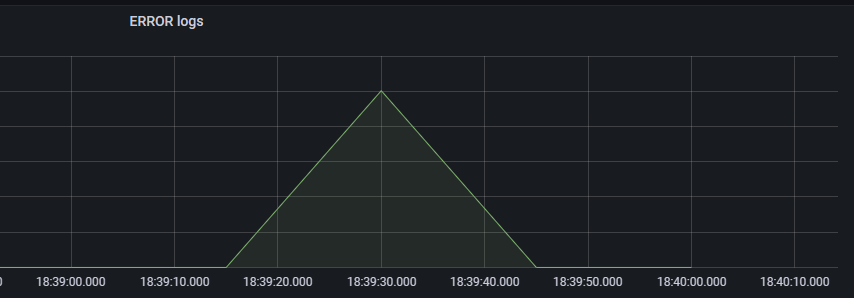
- 에러 로그 급증을 확인 할 수 있다.
