논문 리뷰 스터디_BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
논문리뷰
논문에 대해서
NLP (자연어 처리)분야에서 큰 발전을 가져온 BERT에 대한 논문이다.
-
위키에서 말하는 BERT:
두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련시킵니다. 이를 위해서 50:50 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어붙인 두 개의 문장을 주고 훈련시킵니다.
-
https://paperswithcode.com/paper/bert-pre-training-of-deep-bidirectional
: 2019년에 Google AI Language에서 발표한 논문 -
기타 참고하면 좋을 논문 링크: https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap
0. Abstract

1. BERT의 약자
: BERT는 Bidirectional Encoder Representations from Transformers(트랜스포머의 양방향 인코더 표현)의 약자이다.
2. BERT의 설계
: 모든 레이어에 양방향 문맥에서 공동으로 조절함으로써 라벨이 없는 텍스트로부터 깊은 양방향 표현들을 사전 훈련하도록 디자인 됨
3. BERT모델의 결과
: 사전훈련된 BERT모델은 작업별 구조 수정을 크게 할 필요가 없고 질문 답변과 언어 추론과 같은 넓은 분야의 작업에서 최신기술모델(state-of-the-art)을 만들기 위해 하나의 출력레이어(output layer)만 추가해도 파인튜닝(fine-tuned)할 수 있다.
- Fine Tuning(=전이 학습) 뜻: 이미 존재하는 모델에 추가 데이터를 투입하여 파라미터를 업데이트 하는 것을 말한다. 임의의 값으로 초기화한 파라미터로 처음부터 다시 학습하는 것보다 속도가 빠른 것이 장점
> 예시: A라는 목적을 위해서 학습된 파라미터 C-> B라는 목적을 위해 문제를 풀고 싶을 때 C를 토대로 수정해서 B를 푸는데 사용4. BERT의 장점
: 컨셉적으로 간단하며 실질적으로 파워풀하다. (뒤에 이어지는 문맥상 성능이 좋다 라는 뜻으로 알아들었다.)
5. BERT의 성능
-
GLUE 점수 => 80.5% (7.7% 절대적으로 향상됨)
GLUE: 범용적인 자연어처리 모델 평가 방법. 하나가 아니라 여러가지 task를 수행하고, 그 값들을 취합하여 최종 점수를 얻는다. GLUE에 포함되어 있는 TASK data set:
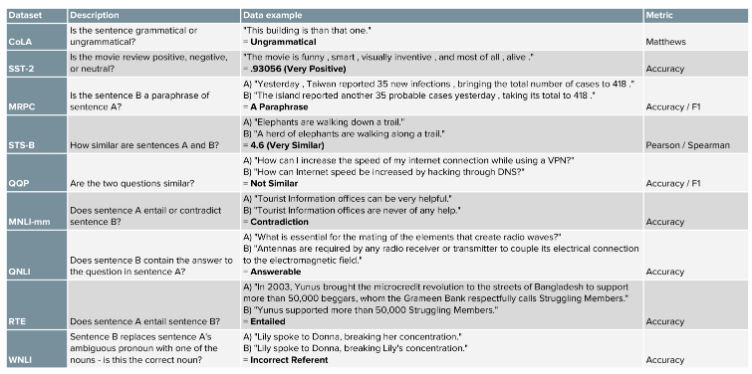
-
MultiNLI 정확도 => 86.7%
MultiNLI (문장 쌍 수준): 텍스트 수반 정보 주석으로 433,000개의 쌍으로 된 문장 모음. 예시:
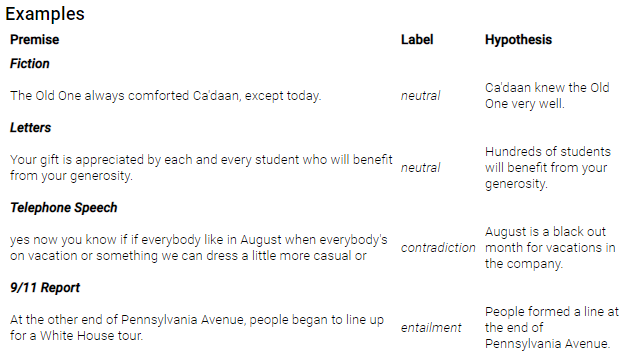
-
SQuAD v1.1 질문 답변 테스트 => F1이 93.2 (1.5점 향상)
-
SQuAD v2.0 질문 답변 테스트 => F1이 83.1 (5.1점 향상)
SQuAD: Stanford Question Answering Dataset의 줄임말로 련의 Wikipedia 기사에서 크라우드 워커가 제기 한 질문으로 구성된 독해 이해 데이터 세트이다.
데이터 셋 및 리더보드는 여기서 확인 가능: https://rajpurkar.github.io/SQuAD-explorer/- 입력 : Context / question 쌍의 형태
- 출력 : Answer, 정수 쌍으로, Context 내에 포함된 답변 Text의 시작과 끝을 색인화 한다.

등 11개의 자연어 처리 작업에서 새로운 최신기술결과를 얻는다.
1. Introduction
1번째 문단: 언어모델 사전훈련에 대한 과제
- 언어모델을 사전 훈련하는 것은 많은 자연어처리작업 향상에 효과적
- 사전훈련 과제:
- 문장수준의 과제: 자연어 추론 및 의역(paraphrasing) -> 문장간의 관계를 전체적으로 분석하여 예측
- 토큰수준의 과제: 토큰수준에서 미세한 산출물을 출력하기 위해 모델이 요구되는 명명된 개체 인식 및 질문 답변
2번째 문단: 사전훈련된 언어 표현을 적용하기 위한 두가지 전략
down stream tasks(구체적을 풀고 싶은 문제)를 위해 사전 훈련된 언어표현들을 적용하는 것에 두 가지 전략이 존재:
- Feature based: 사전 훈련된 표현들을 추가기능으로 포함하는 작업별 구조를 사용
EX. ELMo (Embeddings from Language Model의 약자): 언어모델로하는 임베딩
- Feature based: 사전 훈련된 표현들을 추가기능으로 포함하는 작업별 구조를 사용
- Fine-tuning: 최소한의 작업별 파라미터를 도입하고 모든 사전 훈련된 파라미터를 간단하게 미세조정함으로써 다운스트림 과제에 대해 훈련한다.
EX. GPT (Generative Pre-trained Transformer의 약자): 자연어 처리의 기반이 되는 조건부 확률 예측 도구. 여러텍스트 데이터들을 분석해서 적절한 문장을 만들어내는 것
- Fine-tuning: 최소한의 작업별 파라미터를 도입하고 모든 사전 훈련된 파라미터를 간단하게 미세조정함으로써 다운스트림 과제에 대해 훈련한다.
계속 작성 예정
