SQL
1.SQL 기초_SELECT, FROM
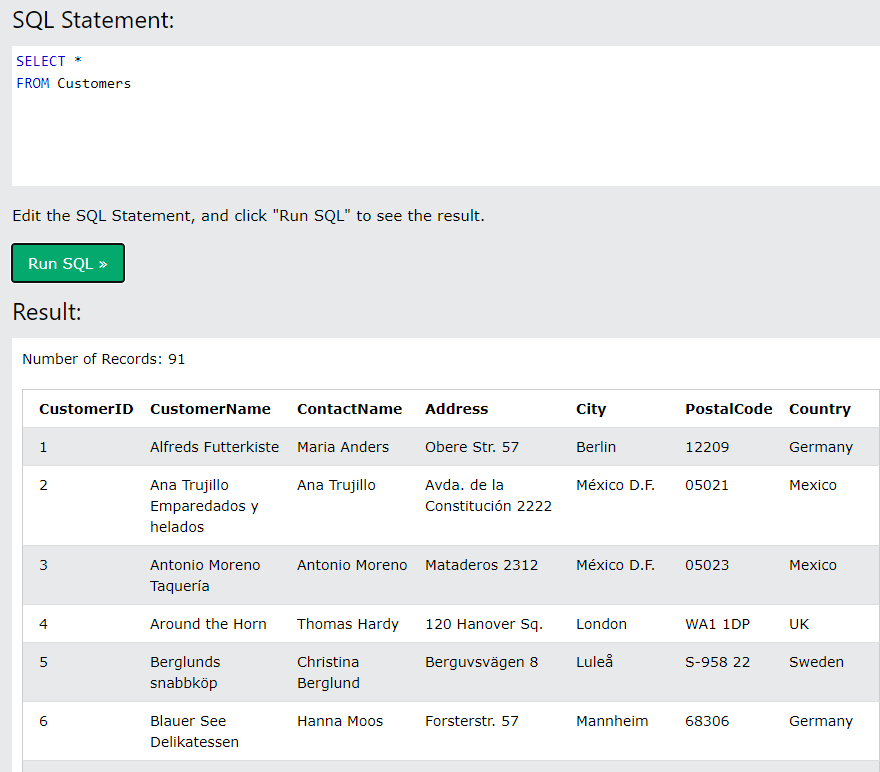
table 이름을 FROM 절에 쓴다. 속성 이름 (학교, 이름 등)을 SELECT절에 쓴다.
2.SQL 기초_WHERE절
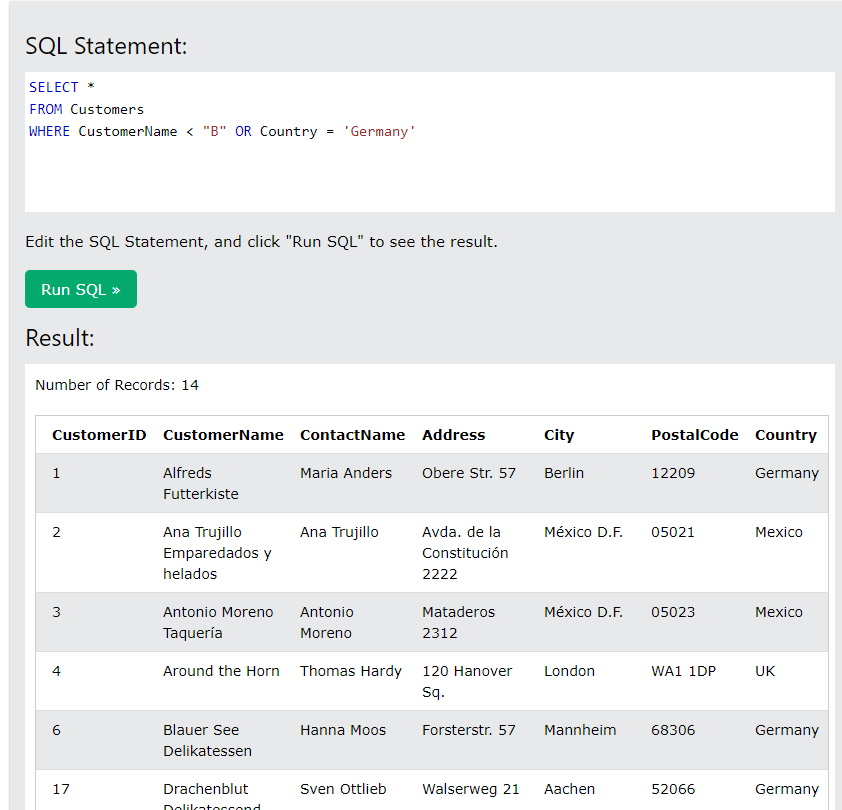
특정 조건을 만족하는 데이터를 불러오기 위해 WHERE절 사용, LIKE(): 비슷한 것 찾기, IN(a,b,c, ...): 조건의 범위를 지정하는 데 사용, BETWEEN : 사이에 포함하는 값 조건 걸 때, IS NULL : 비어 있는 값이 있는지 확인할 때 주로
3.SQL 기초_정렬하기
ORDER BY 함수와 DESC
4.SQL 기초_문자열 자르기 (SUBSTR)
LEFT(컬럼명/문자열, 문자열의 길이), RIGHT(컬럼명/문자열, 문자열의 길이), SUBSTRING(컬럼명/문자열, 시작위치, 길이) = SUBSTR()
5.SQL 기초_소수점처리 (CEIL, FLOOR, ROUND)
CEIL, FLOOR, ROUND
6.SQL 기초_집계함수

모든 값들을 세준다. 중복된 값들 없이 보고 싶을 때합계함수평균을 내는 함수Null 값 주의! 합계/개수를 하는데 개수에 null 행을 포함시키지 않는다.
7.SQL 기초_GROUP BY, HAVING
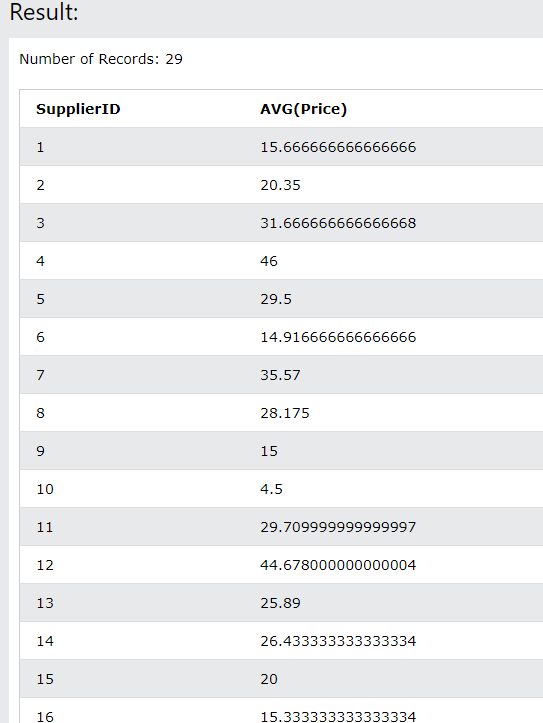
1,2 숫자로 적는 것 보다는 컬럼명을 적어 주는 것이 후에 유지보수에 좋다.예시) 평균가격이 100불 이상인 supplier와 category를 보고 싶다.WHERE 를 쓰게 되면 100불이상인걸 먼저 거르고 그룹바이로 묶기 때문에 HAVING을 쓴다.
8.SQL 중급_CASE 문
쿼리 구문에서 if문 처럼 조건문을 사용하여 결과값을 내야 하는 경우 사용조건에 따라 True->읽기 중지& 반환, False->Else절의 값 반환, Else부분이 없고 조건이 False->NULL반환WHEN - THEN은 항상 같이 사용됨, 여러개 사용 가능결과:
9.SQL 중급_JOIN
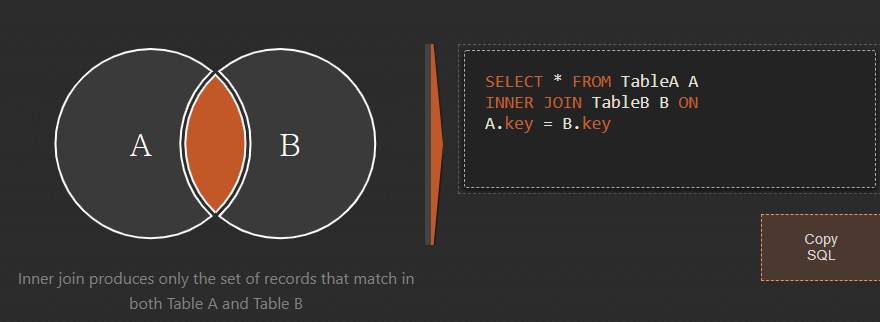
users 와 orders 테이블을 합쳐서 만들 수 있는 모든 경우의 수 행에서 users_id = orders_id 조건 뽑기 INNER JOIN에 또 INNER JOIN을 사용해도 괜찮다. 잇고 싶은 table들을 INNER JOIN 계속 써서 붙일 수 있다.
10.SQL 중급_집합연산 UNION

두 테이블을 합칠때, 중복되어 있는 행이 있으면 그 중복값을 제외하고 합침SELECT DISTINCT처럼 유니크한것만 보여준다고 생각하면된다. 두 테이블을 합칠때, 중복값 까지 다 합침mysql에서는 해당 함수가 지원이 안된다.
11.SQL_자주하는 실수 모음

GROUP BY 쓸 때 이렇게 쿼리를 작성할 때가 많은데, GROUP BY와 SELECT는 항상 짝을 이루어야 한다 SELECT에 집계함수를 제외하고는 GROUP BY와 항상 짝을 이루어야 한다는 점을 기억해주세요! SELECT x , y ,
12.SQL 고급_subquery
가상의 테이블을 하나더 만든다. 주의해야할 점: 원래의 데이터 값에 null이 있으면 서브쿼리로 만들어진 table에 들어가지 않기 때문에 집계합수 쓸 때 주의하기= 으로 들어갈 때, 서브쿼리의 결과물이 1개 여야 한다. IN 또는 OR 으로 들어갈 때, 서브쿼리의 결
13.SQL 고급_윈도우 함수

GROUP BY랑 비슷한 기능GROUP BY :But, 한줄로 요약해서 보여주는 것이 아니라 각각의 raw에다가 그 결과물을 쭉 찍어준다. 함수(컬럼1) OVER (PARTITION BY 컬럼2 ORDER BY 컬럼3)컬럼2에는 그룹별로 보고 싶은 컬럼을 쓰면 된다.
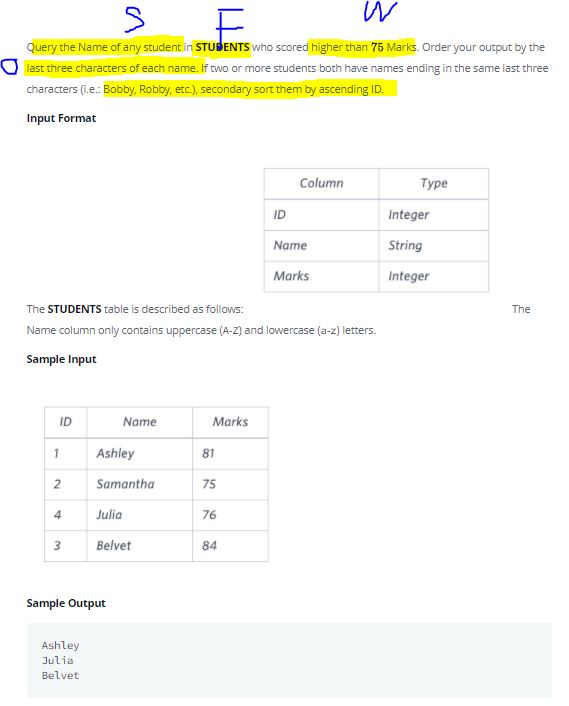
14.SQL_고급- 특이한 Join 조건
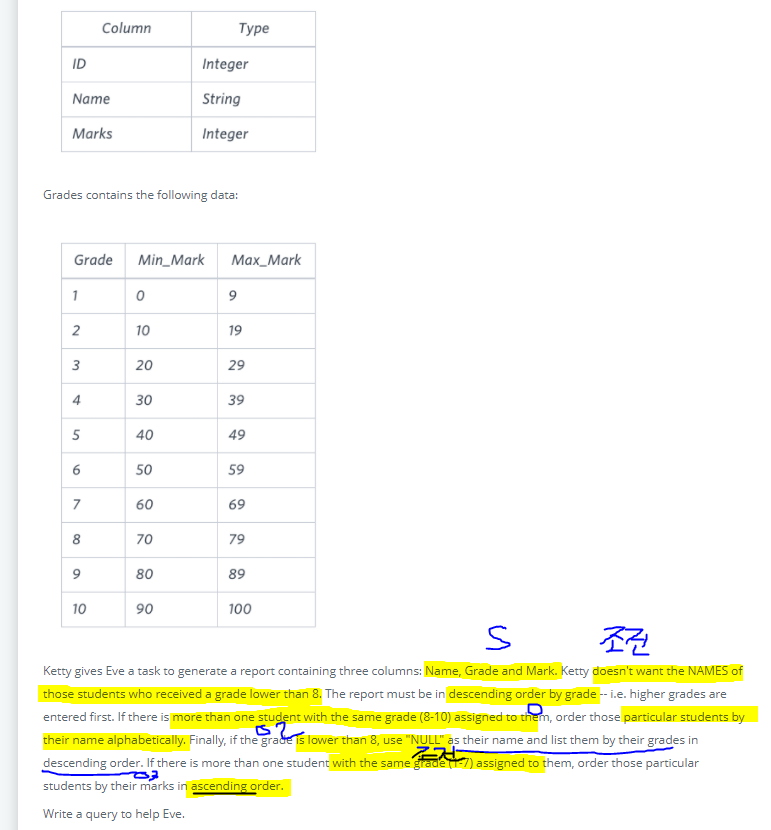
SELECT 문에 출력해야 할 것: Name, Grade, MarkFROM 문에 쓰는 table -> students 랑 grades 합친 것합치는 기준-> marks랑 min_mark와 max_mark사이정렬 기준: 성적은 내림차순, 이름과 점수는 오름차순
15.SQL_프로젝트1_동료의 분석 파악
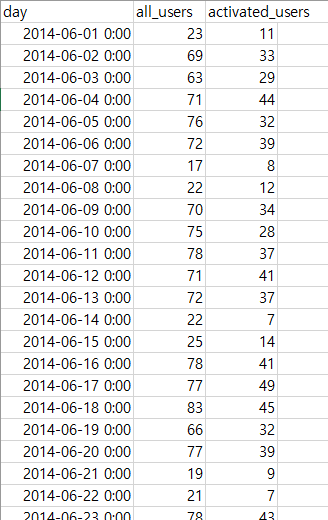
'Yammer'라는 서비스를 만드는 회사에 입사업무: 동료의 분석결과에 대해 리뷰문제 상황 파악 (동료가 어떤 문제를 풀고자 했는지)\-> 제시된 문제상황: Investigating a Drop in User Engagement테이블 파악\-> 동료의 분석결과: Inv
16.SQL 프로젝트 2_검색기능개선

전사적으로 이번 분기에는 검색 기능 개선에 리소스를 많이 투입하려고 한다.검색은 우리의 핵심 기능 중 하나이며, 서비스를 이용하는 사람들의 대다수가 검색 기능을 활발하게 이용하고 있다고 생각된다. 이 부분 사실일까 확인이미 진행한 분석에 대한 리뷰검색 기능 또는 검색을