자료구조와 알고리즘, 자료형, 빅 오 표기법
데이터 구조와 알고리즘
✨ 데이터 구조란?
- 데이터를 구성하고 저장하는 방법
- 데이터를 식별하는 방법을 제공
- 데이터의 관계를 보여주는 개념
✨ 알고리즘 이란?
- 문제를 해결하는 논리적 단계
- 정해진 순서대로 문제를 해결하는 방법. "절차"
데이터 구조와 알고리즘의 관계
✨ 서로 다른 개념이면서 상호 보완적.
- 데이터 구조는 알고리즘이 다루는 데이터를 구성하며, 알고리즘이 데이터를 처리하고 사용자가 원하는 정보를 산출하는 과정에서 필요한 부분을 제공한다.
- 데이터 구조는 알고리즘이 결과를 산출하는 과정에서 처리하는 데이터를 저장하고 구성한다.
💡 데이터 : 컴퓨터에 저장되어 있거나 컴퓨터가 처리 중인 모든 것을 뜻한다.
기본 자료형
📌 컴퓨터는 데이터를 입력받아 처리 및 가공하여 출력하는 장치이다. 올바른 데이터를 입력해도 무의미한 결과를 출력할 수 있다.
✨ 기본 자료형
- 처리할 데이터의 속성이 무엇인지 컴퓨터에 알려주려고 만든 것
- 더는 하위 자료형으로 나눌 수 없어 Atomic 자료형.
✨ 기본 자료형의 종류
- 불(boolean) : 논리 자료형, 참과 거짓, 0과1상태로 표현 가능
- 문자(character) : 문자열을 사용해 데이터를 표현할 수 있도록 하기 위한 기본 단위
- 정수(integer) : 자연수,0 ,음수까지 함께 포함.
- 부동 소수점 수(floating-point number, 단정도 : float, 배정도 : double)
함수
✨ 프로그래밍에서의 함수
- 특정 동작을 수행하는 코드 덩어리.
✨ 수학에서의 함수
- 독립변수를 종속변수에 대응시키는 표현식
매개변수를 입력받아 처리한 값을 반환한다는 점에서 수학에서의 함수와 같다.
✨ 함수, 메서드, 프로시저, 서브루틴
-
프로그래밍에서의 함수는 매개변수(파라미터)라는 데이터를 입력으로 사용하며 때로는 결과를 반환하기도 하고, 아무 결과를 반환하지 않을 수 있다. 이를 void 함수라 한다.
-
메서드는 OOP 언어에서 클래스 내부에 있는 함수를 메서드라고 한다.
-
일부 프로그래밍 언어에서는 함수를 프로시저 또는 서브루틴이라고 한다.
결론
모두 의미와 사용하는 목적이 같다. 단지 사용하는 프로그래밍 언어나 사람에 따라 용어의 선택이 달라질 뿐이다.
재귀와 반복
✨ 재귀 함수
- 함수 실행 도중 자기 자신을 호출하는 함수
- 보통 특정 조건을 충족할 때까지 끊임없이 동작한다.
- 재귀에 한계인 최대 재귀 깊이를 초과해 스택 오버플로가 발생할 수 있다.
📌 프로그래밍 언어에 많이 사용하는 방법. 실제 많은 알고리즘이 재귀적으로 동작.
✨ 반복
- 재귀와 혼동해선 안되는 또 다른 개념.
- 특정 조건이 충족될 때까지 코드 덩어리의 실행이 되풀이 되는 것
알고리즘의 세 가지 유형
✨ 분할 정복 알고리즘(divide and conquer algorithm)
- 큰 문제를 여러 개의 작은 문제로 나눠 해결
- 결과를 결합해 해결 방법을 얻는 알고리즘
✨ 탐욕 알고리즘(greedy algorithm)
- 실행되는 순간마다 최상의 결정(가장 적합한 동작)을 내는 알고리즘
- 단, 매번 최선의 결정을 내려도 그 결정이 전체에 대해 언제나 최선일 수는 없다.
- 탐욕 알고리즘이 내리는 결정이 문제 전체를 해결하는 최적의 결정인지는 장담할 수 없다.
✨ 동적 프로그래밍(=동적 계획법) 알고리즘(dynamic programming algorithm)
- 탐욕 알고리즘과 대조를 이룸
- 과거에 내린 결정이 앞으로의 결정에 영향을 준다
- 문제를 해결하는 다양한 해결 방법을 찾아 저장한 후 나중에 재사용
✨ 탐욕 vs 동적 프로그래밍
- 둘 다 문제를 더 작은 단위로 나누어 해결
- 탐욕 알고리즘은 근사치를 구한다(바로 눈앞에 있는 것만 봄. 그래서 탐욕)
- 동적 프로그래밍은 최적화를 한다
알고리즘 분석
✨ 알고리즘의 효율성
-
시간 복잡도(time complexity)와 공간 복잡도(space complexity)의 방법 이용
-
일반적으로 사용되는 방법은 시간복잡도이며 그 중 '빅 오 표기법'을 사용한다.
시간복잡도
주어진 입력에 따라 알고리즘이 문제를 해결할 때 걸리는 시간. 가장 일반적으로 사용하는 알고리즘 성능 효율 분석 방법.공간복잡도
알고리즘이 문제를 해결할 때 점유하는 메모리 공간을 뜻함. 자원이 제한된 시스템에서 동작하는 프로그램을 구현하는 것과 같이 특별한 경우에 사용하는 분석 방법.
빅 오 표기법
✨ 알고리즘의 효율성을 설명할 때 빅 오메가, 리틀 오메가, 빅 오, 리틀 오, 세타 등 다양한 표기법이 존재
✨ 참고
- 오메가 표기법은 알고리즘을 실행하는 데 걸리는 최소시간 측정
- 세타 표기법은 알고리즘을 실행하는 데 걸리는 최소 및 최대 시간 모두 측정
- 빅 오 표기법은 알고리즘을 실행하는 데 걸리는 최대 시간 측정
📌 빅 오 표기법은 알고리즘의 실행 시간이 최악인 경우를 나타내는 것이다.
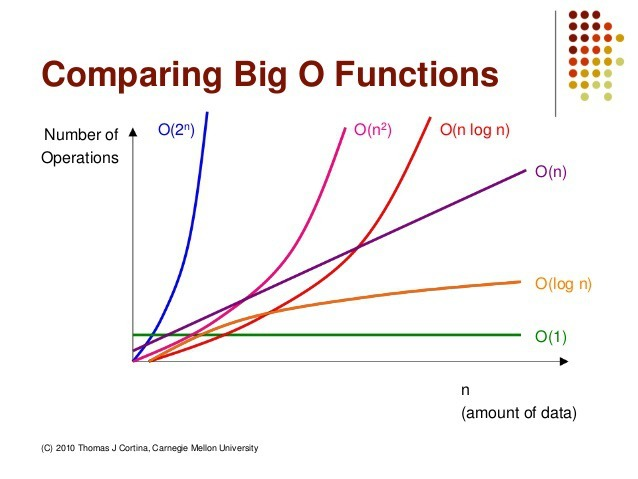
O(1) : 상수형 알고리즘, 데이터 입력량과 무관하게 실행시간이 일정하다
O(n) : 선형 알고리즘, 데이터 입력량에 비례하여 실행 시간이 증가
O(logn) : 로그형 알고리즘, 데이터 입력량이 늘어날수록 단위 입력당 실행 시간이 줄어든다
O(n logn) : 선형-로그형 알고리즘, 데이터 입력량이 n배 늘면 실행 시간이 n배 조금 넘게 늘어남
O(n²) : 2차 알고리즘, 데이터 입력량의 제곱에 비례하여 실행 시간이 늘어 난다.
O(2ⁿ) : 지수형 알고리즘, 데이터 입력량이 추가될 때마다 실행 시간이 두배로 늘어난다
O(n!) : 팩토리얼형 알고리즘, 데이터 입력이 추가될 때마다 실행 시간이 n배로 늘어난다걸리는 시간
O(1) < O(logn) < O(n) < O(n logn) < O(n²) < O(2ⁿ) < O(n!)
왼쪽에서 오른쪽으로 갈수록 느려지고 효율이 떨어 진다.
