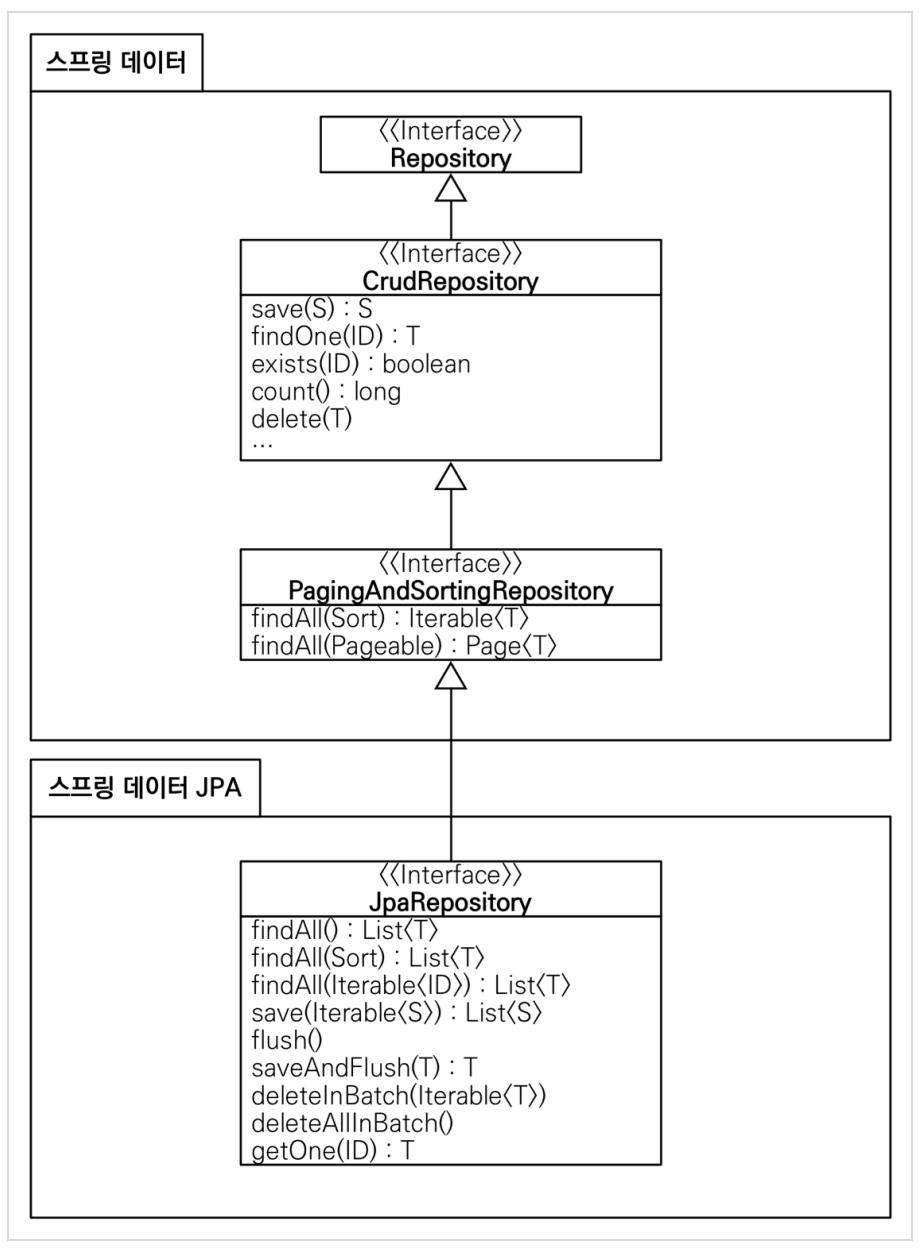
Spring Data JPA는 자기 혼자 돌아가는 기술이 아니라, JPA를 사용할때 많이 도와주는 기술이다. 정말 다양한 기능을 제공한다.
다만 JPA에 대한 이해없이 Spring Data JPA만 익혀 사용한다면 문제가 생길 수 있다. 탄탄한 JPA기반 지식위에 Spring Data JPA라는 도구를 사용하는 것이 맞을 것이다.
의존성 추가
//JPA, 스프링 데이터 JPA 추가
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
//p6spy 라이브러리(query 보기 쉽게 해주는거)
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.9.0'Spring Data JPA는 결국 JPA를 쉽게 쓰기위한 기술.. 꼭 JPA를 익혀라
설정과 레포지토리
JPA를 사용하다보면 기본적인 CRUD 기능들을 중복해서 만들게 된다.
findAll(), save(), delete(), findById()등 아주 기본적인 쿼리문들을 반복해서 짜게 되는 상황이 의외로 많다.
Spring Data JPA를 사용하기위해선 @EnableJpaRepositories로 설정해야된다.
@Configuration
@EnableJpaRepositories(basePackages = "jpabook.jpashop.repository")
public class AppConfig {}- 스프링 부트 사용시
@SpringBootApplication위치를 지정(해당 패키지와 하위 패키지 인식) - 만약 위치가 달라지면
@EnableJpaRepositories필요
Repository 만들어 보기
public interface MemberRepository extends JpaRepository<Member, Long> {
}- 끝이다. 인터페이스만 구현해서 JpaRepository를 상속받으면 되고, 그 엔티티와 엔티티의 Id 타입을 넣어주면 됨.
- 실제로 이렇게 아무 구현체 없이 그냥 save(), findById(), findAll(), delete() 등 간단한 명령어들은 그냥 사용이 된다.
- 이게 어떻게 가능한 것일까? 구현체도 없이 저런 명령어들이 사용이 된다니?
Spring Data JPA가 proxy로 구현체를 만들어서 대신 넣어준다. 엔티티와 Id의 타입을 보고 프록시 구현체를 만들어 넣어줌. 또한 코드들을 살펴보면 CRUDRepository등 여러가지에서 이미 여러가지 쿼리 기능들을 만들어 넣어놓음.
그리고 위에 Repository를 보면 @Repository가 생략 되어 있는데 컴포넌트 스캔을 스프링 데이터 JPA가 자동으로 처리, JPA 예외를 스프링 예외로 변환하는 과정도 자동으로 처리해준다.
실제 우리가 그전에 짜보았던 순수 JPA 코드들이 기억날 것이다. 그 코드들과 거의 비슷한 코드들이 그냥 Spring Data JPA가 만들어서 넣어준다고 보면 된다.
Spring Data 분석
Spring Data Commons라는 라이브러리가 있고, 이는 Spring Data project들이 다 사용하는것.
Spring Data JPA는 Spring Data프로젝트들 중 JPA관련 라이브러리, 여기엔 Spring Data JDBC, Spring Data JPA ,Spring Data LDAP , Spring Data MongoD, Spring Data Redis, Spring Data R2DBC, Spring Data REST 등 이 외에도 더 많은 것이 있다.
Commons에는 말그대로 Spring Data에서 공통으로 사용할 수 있는 것이고, 다른 DB를 쓰더라도 상관없이 다 같이씀. JPA쪽 프로젝트는 JPA에서만 사용할 수 있는것.
Paging같은 기능들은 Commons에 있고, Spring에서 처리하기 쉽게 만들어줌.
주요 메서드
save(S) : 새로운 엔티티는 저장하고 이미 있는 엔티티는 병합한다.
delete(T) : 엔티티 하나를 삭제한다. 내부에서 EntityManager.remove() 호출
findById(ID) : 엔티티 하나를 조회한다. 내부에서 EntityManager.find() 호출
getOne(ID) : 엔티티를 프록시로 조회한다. 내부에서 EntityManager.getReference() 호출
findAll(…) : 모든 엔티티를 조회한다. 정렬( Sort )이나 페이징( Pageable ) 조건을 파라미터로 제공할 수 있다.
참고: JpaRepository 는 대부분의 공통 메서드를 제공한다.
만약 공통의 기능이 아니라 어떤 특화된 기능을 구현하고 싶다면?
일반적인 구현체와 같이 Implements를 해서 하면 될까?
이는 안된다. 기존의 공통 기능들조차도 전부 상속받아서 구현해야된다. Spring Data JPA는 다른 방식으로 이런 기능 구현을 지원을 한다.
쿼리 메서드
메서드 이름으로 쿼리 생성
순수 JPA
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery("select m from Member m
where m.username = :username and m.age > :age")
.setParameter("username", username)
.setParameter("age", age)
.getResultList();
}스프링 데이터 JPA의 쿼리 메서드
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}장점
- 스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행
- 쿼리문을 만들 필요가 없어지고, 조건에 맞춰 이름을 짜면 된다.
- 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다. 애플리케이션 로딩 시점에 오류를 인지할 수 있는 장점이 있다.
- 쿼리 메소드 조건은 공식 홈페이지의 문서에 잘 나와있다. 이동
단점
- 복잡한 쿼리일수록 메서드 네임이 너무 길어지고 어려워진다.
- 위의 메서드만 봐도 엄청 길어지고 있다.
간단간단한 쿼리문들은 쿼리 메서드를 이용해서 짜고, 좀 더 복잡한 쿼리는 다른 방법을 이용해서 풀어 나갈 수 있다.
JPA Named Query
JPA의 NamedQuery를 호출할 수 있음
@NamedQuery 어노테이션으로 Named 쿼리 정의
@Entity
@NamedQuery(
name="Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}스프링 데이터 JPA로 NamedQuery 사용
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);
@Query 생략 가능
List<Member> findByUsername(@Param("username") String username);스프링 데이터 JPA는 선언한 "도메인 클래스 + .(점) + 메서드 이름"으로 Named 쿼리를 찾아서 실행. 만약 실행할 Named 쿼리가 없으면 메서드 이름으로 쿼리 생성 전략을 사용한다.
Named Query는 기본적으로 정적쿼리이다. 애플리케이션 로딩 시점에서 파싱해서 잘못된 문법이 있으면 바로 알려준다. 매우 큰 장점이다.
하지만.. Named Query를 사용을 안한다.
첫째, Entity에 직접 쿼리를 작성하는 점이 좋지 않음.
둘때, 이것이 더 큰 이유인데 Spring Data JPA가 비슷하면서도 더 강력한 기능을 제공한다.
@Query, 리포지토리 메소드에 쿼리 정의하기
메서드에 JPQL 쿼리 작성
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") intage);
}- 실행할 메서드에 정적 쿼리를 직접 작성하므로 익명 Named 쿼리라 할 수 있음
- JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있음(매우 큰 장점!)
- 메소드 이름 쿼리 생성 기능은 파라미터가 증가하면 메서드 이름이 매우 지저분해진
다. 따라서 @Query 기능을 자주 사용하게 된다.
@Query, 값, DTO 조회하기
단순 값 하나를 조회
@Query("select m.username from Member m")
List<String> findUsernameList();JPA 값 타입( @Embedded )도 이 방식으로 조회할 수 있다.
DTO로 직접 조회
@Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) " +
"from Member m join m.team t")
List<MemberDto> findMemberDto();- DTO 직접 조회를 위해서는 패키지 경로와 클래스이름을 정확하게 적어줘야되고, 생성자도 파라미터에 맞는 생성자가 있어야한다.
- JPQL문법과 차이가 없음. 사실 당연하다. 그냥 리포지토리에 JPQL 쿼리를 적어서 실행해 줄 수 있게 하는 것이
@Query애노테이션이니 적는 쿼리문은 JPQL과 똑같음.
파라미터 바인딩
이름 기반 vs 위치 기반 바인딩
-
일단 위치기반은 사용하지 않는다. 이런 비슷한 방식으로 위치냐 이름이냐가 있는데, 거의 대부분 위치 기반은 사용하지 않는다고 보면 된다.
-
코드 가독성과 유지보수를 위해 이름 기반 파라미터 바인딩을 사용하자 (위치 기반은 파라미터가 추가되거나 순서가 바뀌기라도 한다면 찾기도 어렵고 큰 장애로 이어질 수 있다…)
컬렉션 파라미터 바인딩 - Collection 타입으로 in절 지원
@Query("select m from Member m where m.username in :names")
List<Member> findByNames(@Param("names") List<String> names);반환 타입
스프링 데이터 JPA는 유연한 반환 타입 지원
List<Member> findByUsername(String name); //컬렉션
Member findByUsername(String name); //단건
Optional<Member> findByUsername(String name); //단건 Optional조회 결과가 많거나 없으면?
컬렉션
- 결과 없음: 빈 컬렉션 반환(null이 아님!! Empty컬렉션을 반환해줌!!)
단건 조회
결과 없음: null 반환 (원래 JPA는 NoResultException이 뜸. Spring Data JPA가 try-catch로 감싸서 null로 반환 해주는 것)
결과가 2건 이상: javax.persistence.NonUniqueResultException 예외 발생
(스프링이 IncorrectResultSizeDataAccessException으로 바꿔서 반환해줌)
단건 조회에서 이제 자바8 이후 Optional을 사용하면서 null이나 이런쪽에 신경을 덜 써도 되긴함. 반환타입을 보면서 확실하게 알 수 있기 때문에.
페이징과 정렬
JPA로만 짠 페이징 쿼리
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m
where m.age = :age order by m.username desc")
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m
where m.age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}setFirstResult(offset),setMaxResults(limit)를 통해 바로 페이징을 할 수 있다- JPA가 DB에 맞게 쿼리문을 날려주기 때문에 상관없이 사용 가능.
Spring Data JPA 페이징과 정렬
페이징과 정렬 파라미터
org.springframework.data.domain.Sort : 정렬 기능
org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
특별한 반환 타입
org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능(내부적으로 limit + 1조회)
List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
페이징 패키지들을 보면 JPA가 아니다. 즉 JPA에서만 사용한 기술은 아니고, 스프링이 DB전반적으로 추상화해서 제공하는 기술이다.
Page<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용
Slice<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Sort sort);Spring Data page는 페이지를 1부터가 아니라 인덱스와 같이 0부터 받음.
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Sort.Direction.DESC, "username"))`
순서대로, page, size, sorting(빼도 됨), properties를 받음
Page<Member> page = memberRepository.findByUserName(name,pageRequest);
List<Member> content = page.getContent();
long tatalElements = page.getTotalElements();
-
totalCount를 받는 쿼리를 짤 필요가 없음. Page에서 알아서 totalCount를 계산해 준다.
-
totalCount 쿼리도 최적화되서 나감.
-
Page가 아닌 Slice로 받을 시 count쿼리를 사용안함.(페이지가아닌 모바일에서 화면을 쭉 내릴때, 더보기나 그런식으로 볼때 사용할 수 있는 것. 요청한것보다 하나 더 받음)
-
Page에서 Slice로 바꿀때 그냥 반환 타입만 바꿔줘도 됨.
-
totalCount 쿼리를 짤때 잘 짜야됨. 실제 쿼리랑 다를 수 있음. 실제 자료는 join을 했을수 있지만 toOne 관계에서는 어차피 row수는 같음. 그럼 totalCount는 join을 할 필요가 없음.
-
정렬도 위에 제공한 기능을 사용할 수 있지만 복잡해지면 따로 정렬 쿼리를 짜는게 맞다.
totalCount 쿼리를 따로 짤 수 있게 해준다.
@Query(value = "select m from Member m left join m.team t",
countQuery = "select count(m.username) from Member m")
Page<Member> findByAge(int age, Pageable pageable);- 카운터 쿼리를 따로 없이 value 부분만 짠다면, 카운터 쿼리도 같이 join으로 나가게 된다.
- 카운터 쿼리를 조인할 필요가 없음. join을 다 해서 가져온다면 성능 이슈가 발생할 수 도 있음. 그럴땐 따로 카운터 쿼리를 짜는게 좋다.
위의 Member를 받아오면서 바로 DTO로 변환할 수 있다.
Page<Member> page = memberRepository.findByAge(10, pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto());Spring Data JPA를 잘 사용하면 JPA를 사용하는 것 보다 훨씬 편리한 기능을 제공하며, 폭발적인 생산성 향상이 일어날 수 있.
벌크성 수정 쿼리
JPA를 사용한 벌크성 수정 쿼리
public int bulkAgePlus(int age) {
return em.createQuery(
"update Member m set m.age = m.age + 1" +
"where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
}스프링 데이터 JPA를 사용한 벌크성 수정 쿼리
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);-
@Modifying을 달아줘야 그냥 JPA를 사용할때 나갓던.executeUpdate();가 적용이된다. 만약@Modifying이 없다면 ResultList나 singgleResult가 나간다. -
@Modifying이 없다면 DML 명령어를 날릴 수 없다고 한다. -
벌크성 연산을 조심해야 되는 점. 영속성 컨텍스트를 무시하고 DB에 바로 쿼리를 날려버린다.
-
만약 벌크성 연산을 날리고, 바로 영속성 컨텍스트를 조회하면 벌크연산의 쿼리가 반영이 되어 있지 않다. 따라서 영속성 컨텍스트를 flush와 clear를 하고 다음 작업을 해야 됨.
-
Spring Data JPA는 편리하게 그런 기능을 제공한다. EntityManager를 받아서 flush와 clear를 쓰는게 번거러움.
@Modifying(clearAutomatically = true)를 사용한다면 자동으로 해준다.
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법
member team은 지연로딩 관계이다. 따라서 다음과 같이 team의 데이터를 조회할 때 마다 쿼리가 실행된다. (N+1 문제 발생)
JPQL 페치 조인을 사용하면 이런 N+1 문제에 대해 해결이 가능하다.
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin();Spring Data JPA를 사용할때, 메서드 이름으로 만든는 쿼리에서는 이 페치 조인을 적어줄 수 없다. 그럼 결국 JPQL을 작성해야 된다는 말인데 이때 @EntityGraph라는 것을 이용해서 해결이 가능하다.
스프링 데이터 JPA는 JPA가 제공하는 엔티티 그래프 기능을 편리하게 사용하게 도와준다. 이 기능을 사용하면 JPQL 없이 페치 조인을 사용할 수 있다. (JPQL + 엔티티 그래프도 가능)
//공통 메서드 오버라이드
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//JPQL + 엔티티 그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으로 쿼리에서 특히 편리하다.
@EntityGraph(attributePaths = ("team"))
List<Member> findByUsername(String username);- 간단하게 할때는
@EntityGraph, 결국 복잡하게 짤 때는 JPQL을 작성하자. - @EntityGraph는 결국 fetch join을 쉽게 해준다는 거다. JPA에 대한 이해도가 높다면 이 @EntityGraph에대한 이해도 쉽게 될 것이다.
JPA Hint && Lock
JPA Hint
JPA 쿼리 힌트(SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트)
쿼리 힌트 사용
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);
@Test
public void queryHint() throws Exception {
//given
memberRepository.save(new Member("member1", 10));
em.flush();
em.clear();
//when
Member member = memberRepository.findReadOnlyByUsername("member1");
member.setUsername("member2");
em.flush(); //Update Query 실행X
}쿼리 힌트 Page 추가 예제
@QueryHints(value = { @QueryHint(name = "org.hibernate.readOnly",
value = "true")},
forCounting = true)
Page<Member> findByUsername(String name, Pageable pageable);org.springframework.data.jpa.repository.QueryHints 어노테이션을 사용
forCounting : 반환 타입으로 Page 인터페이스를 적용하면 추가로 호출하는 페이징을 위한 count 쿼리도 쿼리 힌트 적용(기본값 true )
Lock
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findByUsername(String name);- Lock을 Spring Data JPA가 쉽게 사용할 수 있게 @Lock이라는 애노테이션을 제공함.
확장 기능
사용자 정의 리포지토리 구현
-
스프링 데이터 JPA 리포지토리는 인터페이스만 정의하고 구현체는 스프링이 자동 생성
-
스프링 데이터 JPA가 제공하는 인터페이스를 직접 구현하면 구현해야 하는 기능이 너무 많음
-
다양한 이유로 인터페이스의 메서드를 직접 구현하고 싶다면?
(JPA 직접 사용( EntityManager ) , 스프링 JDBC Template 사용 , MyBatis 사용, Querydsl 사용 등...)
사용자 정의 인터페이스
public interface MemberRepositoryCustom {
List<Member> findMemberCustom();
}사용자 정의 인터페이스 구현 클래스
@RequiredArgsConstructor
public class MemberRepositoryImpl implements MemberRepositoryCustom {
private final EntityManager em;
@Override
public List<Member> findMemberCustom() {
return em.createQuery("select m from Member m")
.getResultList();
}
}사용자 정의 인터페이스 상속
public interface MemberRepository extends JpaRepository<Member, Long>, MemberRepositoryCustom {
}- 기존의 인터페이스와 구현체를 만들듯이 하면 된다.
- 규칙: SpringDataJPA리포지토리 인터페이스 이름 + Impl, 스프링 데이터 JPA가 인식해서 스프링 빈으로 등록
참고: 항상 사용자 정의 리포지토리가 필요한 것은 아니다. 그냥 임의의 리포지토리를 만들어도 된다. 예를 들어 MemberQueryRepository를 인터페이스가 아닌 클래스로 만들고 스프링 빈으로 등록해서 그냥 직접 사용해도 된다. 물론 이 경우 스프링 데이터 JPA와는 아무런 관계 없이 별도로 동작한다.
Auditing
엔티티를 생성, 변경할 때 변경한 사람과 시간을 추적하고 싶으면?
- 등록일, 수정일, 등록자, 수정자
테이블에서는 테이블 마다 다루었지만, 객체지향적인 세상에서는 상속과 이런것을 통해 가능.
순수 JPA 사용
우선 등록일, 수정일 적용
package study.datajpa.entity;
@MappedSuperclass //
@Getter
public class JpaBaseEntity {
@Column(updatable = false)
private LocalDateTime createdDate;
private LocalDateTime updatedDate;
@PrePersist
public void prePersist() {
LocalDateTime now = LocalDateTime.now();
createdDate = now;
updatedDate = now;
}
@PreUpdate
public void preUpdate() {
updatedDate = LocalDateTime.now();
}
}
public class Member extends JpaBaseEntity {}JPA 주요 이벤트 어노테이션
@PrePersist , @PostPersist - persist전, persist후
@PreUpdate , @PostUpdate - update전, update후
스프링 데이터 JPA 사용
설정
@EnableJpaAuditing 스프링 부트 설정 클래스에 적용해야함
@EntityListeners(AuditingEntityListener.class) 엔티티에 적용
사용 어노테이션
@CreatedDate
@LastModifiedDate
@CreatedBy
@LastModifiedBy
package jpabook.jpashop.domain;
@EntityListeners(AuditingEntityListener.class)
@MappedSuperclass
public class BaseEntity {
@CreatedDate
@Column(updatable = false)
private LocalDateTime createdDate;
@LastModifiedDate
private LocalDateTime lastModifiedDate;
@CreatedBy
@Column(updatable = false)
private String createdBy;
@LastModifiedBy
private String lastModifiedBy;
}
등록자, 수정자를 처리해주는 AuditorAware 스프링 빈 등록
@EnableJpaAuditing
@SpringBootApplication
public class DataJpaApplication {
public static void main(String[] args) {
SpringApplication.run(DataJpaApplication.class, args);
}
@Bean
public AuditorAware<String> auditorProvider() {
return () -> Optional.of(UUID.randomUUID().toString());
}
}- @EnableJpaAuditing 도 함께 등록해야 합니다.
- 등록자, 수정자는 지금은 그냥 처리했지만 Session으로 처리하거나, SpringSecurity에서 아이디를 가져와 처리하면 된다.
Web확장
- 도메인 클래스 컨버터
Spring data JPA를 사용하면?
@GetMapping("/members/{id}")
public String findMember(@PathVariable("id") Long id) {
Member member = memberRepository.findById(id).get();
return member.getUsername();
}
도메인 클래스 컨버터
@GetMapping("/members/{id}")
public String findMember(@PathVariable("id") Member member) {
return member.getUsername();
}객체로 찾아돋 컨버터를 이용해 매칭해준다. 원래는 다양한 설정들을 등록해줘야 하는데 , 스프링 부트를 사용하면 자동으로 등록이 되어 있다.
주의: 도메인 클래스 컨버터로 엔티티를 파라미터로 받으면, 이 엔티티는 단순 조회용으로만 사용해야 한다.
(트랜잭션이 없는 범위에서 엔티티를 조회했으므로, 엔티티를 변경해도 DB에 반영되지 않는다.)
크게 사용하지 않는것이 좋음.
- 페이징과 정렬
@GetMapping("/members")
public Page<Member> list(Pageable pageable) {
Page<Member> page = memberRepository.findAll(pageable);
return page;
}/members?page=0size=10&sort=id,desc&sort=username,desc
이런 식으로, 페이지 , 사이즈, sort(여러개)를 넣을 수 있다.
글로벌 설정
spring.data.web.pageable.default-page-size=20 /# 기본 페이지 사이즈/
spring.data.web.pageable.max-page-size=2000 /# 최대 페이지 사이즈/개별 설정 - @PageableDefault이용
public String list(@PageableDefault(size = 10, sort = “username”,
direction = Sort.Direction.DESC) Pageable pageable) {
...
}스프링 데이터는 Page를 0부터 시작한다
Page를 1부터 시작하려면?
-
- Pageable, Page를 파리미터와 응답 값으로 사용히지 않고, 직접 클래스를 만들어서 처리한다. 그리고 직접 PageRequest(Pageable 구현체)를 생성해서 리포지토리에 넘긴다. 물론 응답값도 Page 대신에 직접 만들어서 제공해야 한다.
-
spring.data.web.pageable.one-indexed-parameters를 true 로 설정한다. 그런데 이 방법은 web에서 page 파라미터를 -1 처리 할 뿐이다. 따라서 응답값인 Page 에 모두 0 페이지 인덱스를 사용하는 한계가 있다.
Spring Data JPA 구현체 분석
스프링 데이터 JPA가 제공하는 공통 인터페이스의 구현체
org.springframework.data.jpa.repository.support.SimpleJpaRepository
클래스파일에 들어가 코드를 살펴보면 @Repository도 있고, @Transactional(readOnly=true) 등이 클래스에 걸려있다.
@Repository 적용: JPA 예외를 스프링이 추상화한 예외로 변환
@Transactional 트랜잭션 적용
- JPA의 모든 변경은 트랜잭션 안에서 동작
- 스프링 데이터 JPA는 변경(등록, 수정, 삭제) 메서드를 트랜잭션 처리
- 서비스 계층에서 트랜잭션을 시작하지 않으면 리파지토리에서 트랜잭션 시작
- 서비스 계층에서 트랜잭션을 시작하면 리파지토리는 해당 트랜잭션을 전파 받아서 사용
- 그래서 스프링 데이터 JPA를 사용할 때 트랜잭션이 없어도 데이터 등록, 변경이 가능했음(사실 은 트랜잭션이 리포지토리 계층에 걸려있는 것임)
*save() 메서드+public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } }
새로운 엔티티면 저장( persist )
새로운 엔티티가 아니면 병합( merge )
영속상태의 엔티티가 어떤 이유로 영속상태를 벗어낫을때 다시 영속 상태가 되어야 될때 사용하는 것이다. 데이터 업데이트할때 쓰는게 아님.(데이터 업데이트에 사용할 수도 있어서 그렇게 사용하면 안된다는 것)
새로운 엔티티를 판단하는 기본 전략
- 식별자가 객체일 때 null 로 판단
- 식별자가 자바 기본 타입일 때 0 으로 판단
- Persistable 인터페이스를 구현해서 판단 로직 변경 가능
public class Item implements Persistable<String> {
@Id
private String id;
@CreatedDate
private LocalDateTime createdDate;
public Item(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public boolean isNew() {
return createdDate == null;
}
}-
식별자 생성 전략을 개발자가 직접 생성해서 넣어 줄때(generatedValue 사용 x) -> merge가 사용이 된다. why? 이미 엔티티 Id에 값을 넣어줬으므로, save에서 id 값이 not null이므로 merge를 호출한다.
-
merge() 는 우선 DB를 호출해서 값을 확인하고, DB에 값이 없으면 새로운 엔티티로 인지하므로 매우 비효율 적이다
-
이것을 해결 하기 위해 persistable을 상속받아 해결 가능. persistable의 isNew를 정의해서 null로 만들어 준다.(이때 주로 createdDate를 사용. 생성 날짜는 null이고, 비교하기 좋은 데이터)
Projections
엔티티 대신에 DTO를 편리하게 조회할 때 사용
전체 엔티티가 아니라 만약 회원 이름만 딱 조회하고 싶으면?
public interface UsernameOnly {
String getUsername();
}
public interface MemberRepository ... {
List<UsernameOnly> findProjectionsByUsername(String username);
}
select m.username from member m
where m.username=‘m1’;- SQL에서도 select절에서 username만 조회(Projection)하는 것을 확인
- 인터페이스 기반 Closed Projections. 프로퍼티 형식(getter)의 인터페이스를 제공하면, 구현체는 스프링 데이터 JPA가 제공
다음과 같이 스프링의 SpEL 문법도 지원
public interface UsernameOnly {
@Value("#{target.username + ' ' + target.age + ' ' + target.team.name}")
String getUsername();
}
target = uername teamA- value에서 지정한 형식으로 출력된다. (여기선 username teamName 형식)
- 단! 이렇게 SpEL문법을 사용하면, DB에서 엔티티 필드를 다 조회해온 다음에 계산한다! 따라서 JPQL SELECT 절 최적화가 안된다
