📌 문서제어
웹 페이지의 내용은 Document 객체가 관리한다.
- 웹브라우저가 웹페이지를 읽으면 렌더링 엔진은
HTML문서 구문 해석 Document객체는DOM트리라는 객체의 트리 구조 형성
하게 되며 ,
DOM 트리를 구성하는 객체 하나를 노드 라고한다.
- 문서노드 : 전체 문서를 가리키는
Document객체 . document로 참조 - HTML 요소 노드 :
HTML요소를 가리키는 객체 - 텍스트 노드 : 텍스트를 가리키는 객체

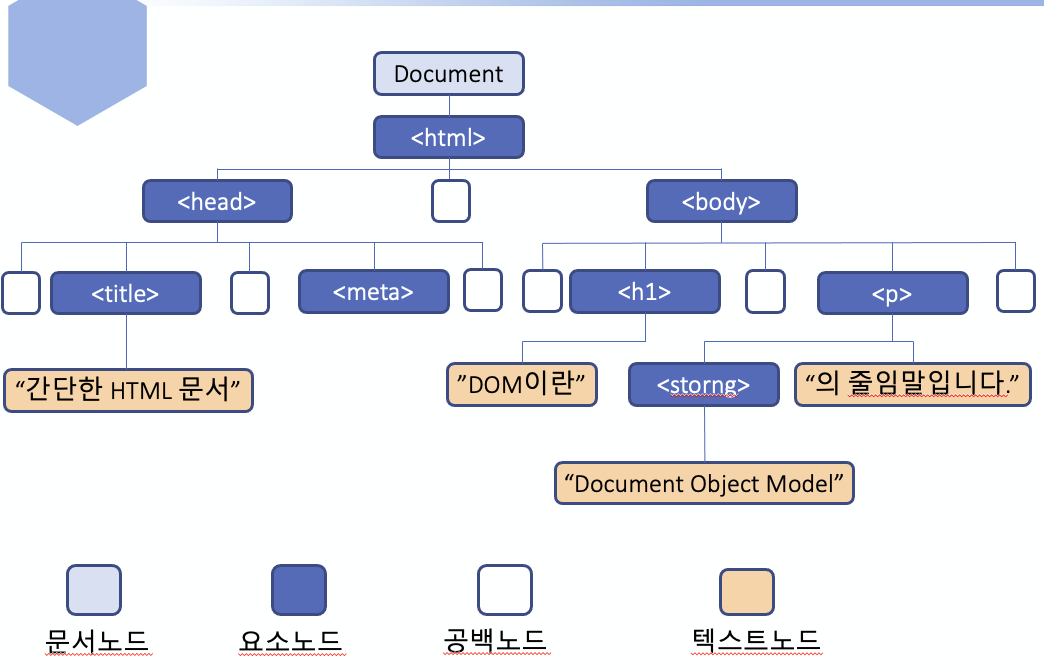
공백 노드
HTML 은 요소 뒤에 공백 문자가 여러 개 있어도 무시하지만
DOM 트리는 요소 앞뒤에서 연속적인 공백 문자를 발견하면 텍스트로 취급하여 텍스트 노드로 생성
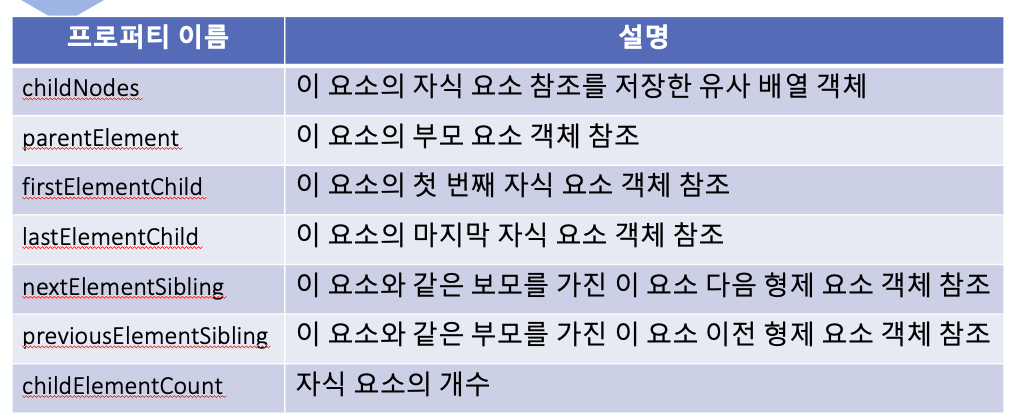
👉 노드 객체의 프로퍼티

이렇게 생긴 parentNode ~ previousSibling 프로퍼티 DOM 트리의 계층 구조가 있다는것을 알면 될것같다
이것을 외울려고 하지말고 , 위에 봤듯이 NodeList 트리가 있는데 ,
계층구조 정의하는 것에 정확한 의미를 알고싶을때 찾아보면 될것같다.
HTML 요소의 트리
HTML 요소의 트리도 마찬가지이다.
HTML 문서의 body 요소 객체를 참조 할 수가 있다.
document.children[0].children[1]
document.firstElementChild.lastElementChild그러면 <body> ...<body> 결과가 나오게 된다.
주요 노드 객체
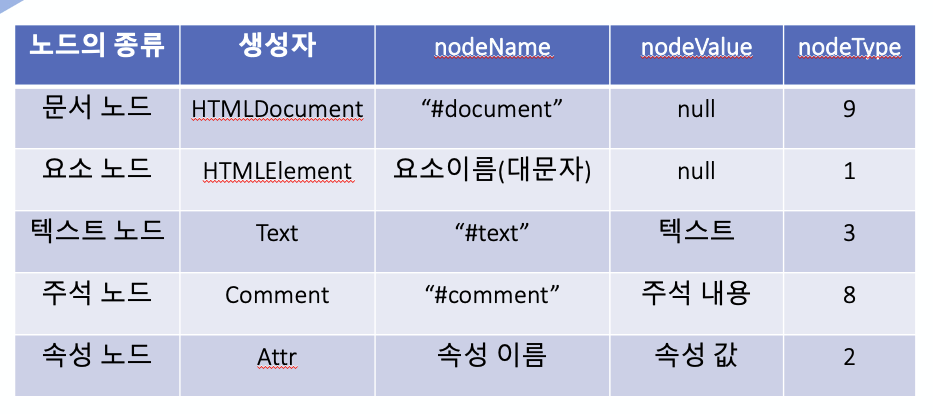
👉 노드 객체 가져오기

말고도 class 혹은 태그이름 으로 가져올 수가 있다.
이렇게 가져오게 되면
NodeList 객체를 반환하게 된다. NodeList 객체는 유사 배열 객체이며 읽기 전용이다.
나머지..불러오는것은 다비슷한 형태이고 궁금한 사항은 책을 보면 좋겠다.
중요한것은 이렇게 불러오게 되면 NodeList 객체를 반환하게 되며
NodeList 객체는 유사 배열객체이며 읽기 전용이라는것이다.

꾸준함이란 ... ?