2020.06.04 업데이트 쿼테이션 값 추출
정규식 테스트 사이트
정규식 보충 자료 => 작성중
정규식이란 ??
정규표현식 은 특정한 규칙을 가진 문자열의 집합을 표현하는데 사용하는 형식 언어이다.
복잡한 문자열의 검색과 치환을 위해 사용되며 , python 뿐만 아니라 문자열을 처리하는 모든 곳에서 사용된다.
import re
text = "에러 1122 : 레퍼런스 오류\n 에러 1033: 아규먼트 오류"
mo = regex.search(text)
if mo !=None:
print(mo.group())https://cheatography.com/davechild/cheat-sheets/regular-expressions/
파이썬에서 자주 사용하는 정규식함수
re.search(pattern , string[,flags]) : string 전체에 대해서 pattern 이 존재하는지 검색
re.match(pattern , string[,flags]) : string 시작부분부터 pattern 이 존재하는지 검색
re.split(pattern , string[,maxsplit=0]) : pattern 을 구분자로 string 을 분리하여 리스트로 반환
re.findall(pattern , string[,flags]) : string 에서 pattern 과 매치되는 모든 경우를 찾아서 리스트로 반환
re.sub(pattern , repl , string[,count]) : string 에서 pattern 과 일치하는 부분에 대하여 repl 로 교체하ㅣ여 결과 문자열을 반환함
re.compile(pattern , [flags]) : pattern 을 컴파일하여 '정규표현식 객체 를 반환
또는 or
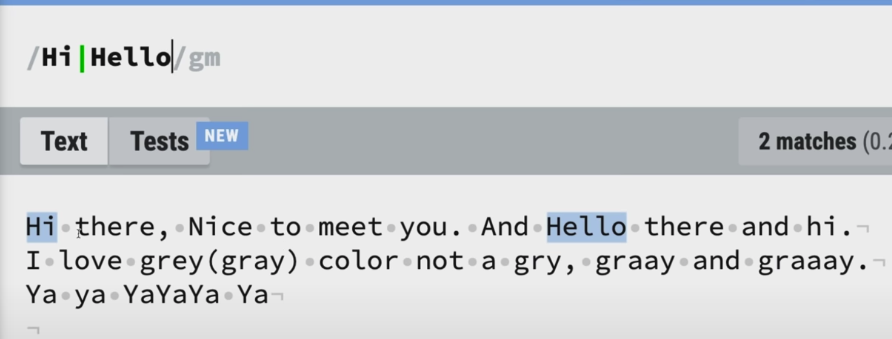
hi 아니면 hello 하나라도 매칭이 되면 보이게 된다.
Search 함수
import re
#Check if the string starts with "The" and ends with "Spain":
txt = "The rain in Spain"
x = re.search("^The.*Spain$", txt)
if (x):
print("YES! We have a match!")
else:
print("No match")
# 출력 YES! We have a match!import re
txt = "The rain in Spain"
x = bool(re.search("rain", txt))
print(x) # Trueimport re
#Search for an upper case "S" character in the beginning of a word, and print the word:
txt = "The rain in Spain"
x = re.search(r"\bS\w+", txt)
print(x.group()) # Spain전화번호 발췌하기
정규 표현식은 단순한 리터럴 문자열을 검색하는 것보다 훨씬 많은 기능들을 제공한다.
특정 패턴의 문자열을 검색하는데 매우 유용하다 .
import re
text = "문의사항이 있으면 032-232-3245 으로 연락주시기 바랍니다."
regex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
matchobj = regex.search(text)
phonenumber = matchobj.group()
print(phonenumber) 다양한 정규식 패턴 표현
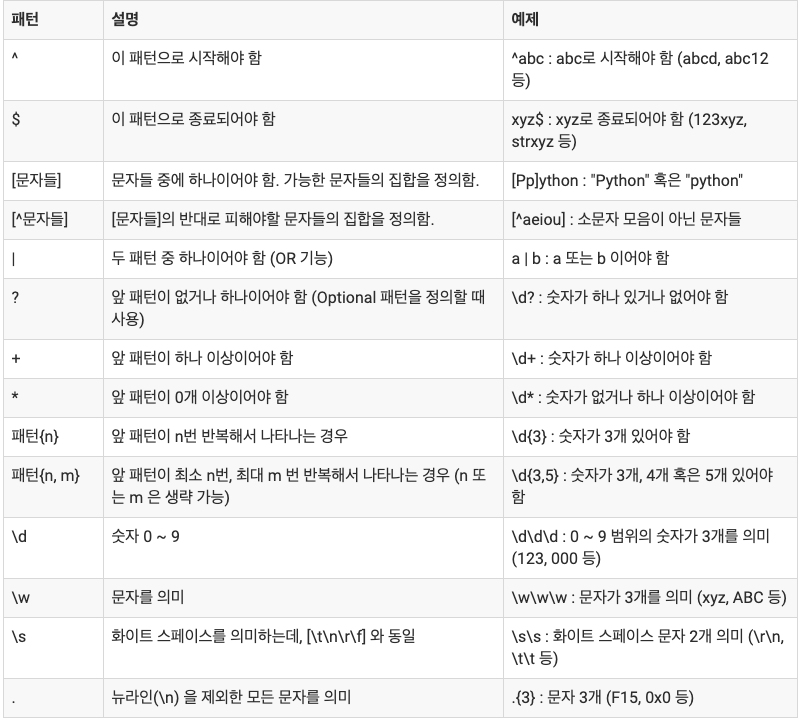
정규식 패턴의 한 예로
"에러 {에러번호}" 와 같은 형식을 띄는 부분을 발췌해 내는 예제를 보자 .
text = "에러 1122 : 레퍼런스 오류\n 에러 1033: 아규먼트 오류"
regex = re.compile("에러\s\d+")
mc = regex.findall(text)
print(mc)
# 출력: ['에러 1122', '에러 1033']ex )
def find_special(name):
return bool(re.search('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]', name))특수 문자를 찾아준다.
ex ) 이메일 체크
import re
def email_check(email):
print(email)
return bool(re.match('^[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$', email))
email = 'jakdu@gmail.com'
print(email_check(email))
자주 쓰이는 정규식
이메일
/^[a-z0-9_+.-]+@([a-z0-9-]+\.)+[a-z0-9]{2,4}$/
HTML 태그
/\<(/?[^\>]+)\>/
전화 번호 - 예, 123-123-2344 혹은 123-1234-1234:
/(\d{3}).*(\d{3}).*(\d{4})/
적어도 소문자 하나, 대문자 하나, 숫자 하나가 포함되어 있는 문자열(8글자 이상 15글자 이하) - 올바른 암호 형식을 확인할 때 사용될 수 있음:
/(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,15}/
숫자만 가능 : [0 ~ 9 ] 주의 : 띄어쓰기 불가능
/^[0-9]+$/
숫자만 가능 : [ 0 ~ 9 ] 주의 : 띄어쓰기 불가능
/^[0-9]+$/
이메일 형식만 가능
/^([\w-]+(?:\.[\w-]+)*)@((?:[\w-]+\.)*\w[\w-]{0,66})\.([a-z]{2,6}(?:\.[a-z]{2})?)$/
한글만 가능 : [ 가나다라 ... ] 주의 : ㄱㄴㄷ... 형식으로는 입력 불가능 , 띄어쓰기 불가능
/^[가-힣]+$/
한글,띄어쓰기만 가능 : [ 가나다라 ... ] 주의 : ㄱㄴㄷ... 형식으로는 입력 불가능 , 띄어쓰기 가능
/^[가-힣\s]+$/
영문만 가능 :
/^[a-zA-Z]+$/
영문,띄어쓰기만 가능
/^[a-zA-Z\s]+$/
전화번호 형태 : 전화번호 형태 000-0000-0000 만 받는다. ]
/^[0-9]{2,3}-[0-9]{3,4}-[0-9]{4}$/
도메인 형태, http:// https:// 포함안해도 되고 해도 되고
/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
도메인 형태, http:// https:// 꼭 포함
/^((http(s?))\:\/\/)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
도메인 형태, http:// https:// 포함하면 안됨
/^[^((http(s?))\:\/\/)]([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
한글과 영문만 가능
/^[가-힣a-zA-Z]+$/;
숫자,알파벳만 가능
/^[a-zA-Z0-9]+$/;
주민번호, -까지 포함된 문자열로 검색
/^(?:[0-9]{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1,2][0-9]|3[0,1]))-[1-4][0-9]{6}$/
괄호 및 특수문자 포함한 사이 글자 지우기
import re
remove_text = 'asdf(asdf)'
print(re.sub(r'\([^)]*\)', '', remove_text))
# asdf위의 ( ) 값 대신에 다른 특수문자를 사용해서 지워도 됩니다
예) <, > 안의 글자 지우기
re.sub(r'\<[^)]*\>', '', remove_text)
정규식 쿼테이션 값 추출
>>> import re
>>> string = '"Foo Bar" "Another Value"'
>>> print re.findall(r'"(.*?)"', string)
['Foo Bar', 'Another Value']remove_text = "asdf(xcv)"
def bracket(string) :
print(re.sub(r'(\"[\w\s]+\")', '', string))
print(bracket(remove_text))python 정규식
공백제거
def re_palce(tag):
pattern = re.compile(r'\s+')
sentence = re.sub(pattern, '', tag)
return sentence
꾸준함이란 ... ?