http://pythonstudy.xyz/python/article/408-pandas-%EB%8D%B0%EC%9D%B4%ED%83%80-%EB%B6%84%EC%84%9D
start
pip install pandas
판다스는 데이터 분석을 위해 널리 사용되는 파이썬 라이브러리 패키지이다.
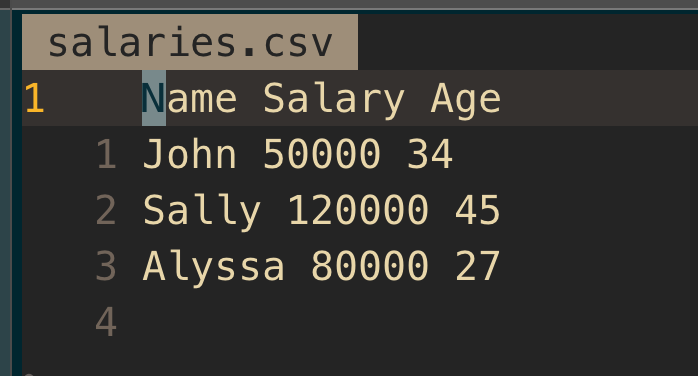
Name,Salary,Age
John,50000,34
Sally,120000,45
Alyssa,80000,27csv 파일은 준비한다.
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
print(df["Salary"])
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
0 50000
1 120000
2 80000
Name: Salary, dtype: int64이라고 출력이 된다.
pandas mutiple columns
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
print(df[['Name','Salary']])
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
Name Salary
0 John 50000
1 Sally 120000
2 Alyssa 80000pandas columns max , min
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
print(df['Salary'].min())
print(df['Salary'].max())
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
50000
120000True False
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
ser_of_bool = df['Age'] > 30
print(ser_of_bool)
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
0 True
1 True
2 False
Name: Age, dtype: bool해당 row 만 출력
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
ser_of_bool = df['Age'] > 30
print(df[ser_of_bool])
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
Name Salary Age
0 John 50000 34
1 Sally 120000 45unique() 리스트 출력
import pandas as pd
df = pd.read_csv('salaries.csv')
print(df)
print("-"*10)
print(df['Age'])
print(df['Age'].unique())
Name Salary Age
0 John 50000 34
1 Sally 120000 45
2 Alyssa 80000 27
----------
0 34
1 45
2 27
Name: Age, dtype: int64
[34 45 27]https://www.opentutorials.org/module/3873/23171
특정 목록만 출력
import pandas as pd
products = {'Product': ['Tablet','iPhone','Laptop','Monitor'],
'Price': [250,800,1200,300]
}
df = pd.DataFrame(products, columns= ['Product', 'Price'])
products_list = df.values.tolist()
print (products_list)
# [['Tablet', 250], ['iPhone', 800], ['Laptop', 1200], ['Monitor', 300]]column names
https://datatofish.com/convert-pandas-dataframe-to-list/
import pandas as pd
products = {'Product': ['Tablet','iPhone','Laptop','Monitor'],
'Price': [250,800,1200,300]
}
df = pd.DataFrame(products, columns= ['Product', 'Price'])
products_list = [df.columns.values.tolist()] + df.values.tolist()
print (products_list)
# [['Product', 'Price'], ['Tablet', 250], ['iPhone', 800], ['Laptop', 1200], ['Monitor', 300]]데이터 formatting
import pandas as pd
products = {'Product': ['Tablet','iPhone','Laptop','Monitor'],
'Price': [250,800,1200,300]
}
df = pd.DataFrame(products, columns= ['Product', 'Price'])
products_list = [df.columns.values.tolist()] + df.values.tolist()
f = '{:<8}|{:<15}' # formatting
for i in products_list:
print(f.format(*i))Product |Price
Tablet |250
iPhone |800
Laptop |1200
Monitor |300
꾸준함이란 ... ?