
좌표 압축 [C++]
문제 링크: https://www.acmicpc.net/problem/18870
난이도: ⚪⚪
1. 문제 설명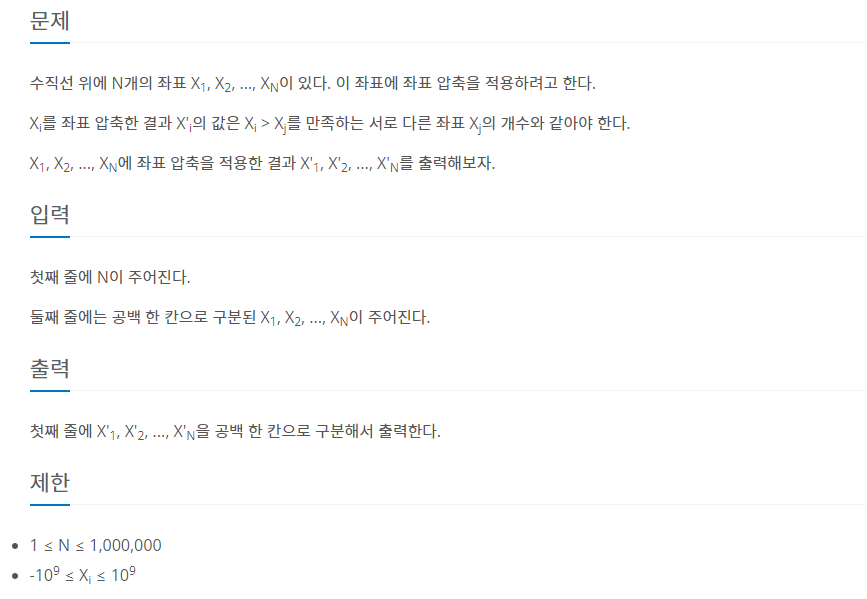
2. 문제 접근
- 💡
find()를 이용하면 시간복잡도가O(n)이 되기 때문에 시간초과가 난다. - 💡
lower_bound()를 이용하면 이진탐색 기반이기 때문에O(log n)으로 통과할 수 있다.
- 좌표의 값은 int형의 범위를 초과할 수 있기 때문에 더 큰 타입의 자료형을 사용한다.
- 좌표를 입력받은 배열을 복사하여 중복을 제거한다.
- 중복을 제거한 배열에서 원본 배열의 원소를 찾아 인덱스를 구한다.
👉lower_bound()를 이용한다.
3. 제출 코드
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main(void)
{
// 빠른 입출력
ios::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N;
cin >> N;
vector<long> v1;
for (int i = 0; i < N; i++) // O(n)
{
long temp;
cin >> temp;
v1.push_back(temp);
}
// v2는 v1을 정렬하고 중복을 제거한 배열이다.
vector<long> v2 = v1;
sort(v2.begin(), v2.end()); // nlog(n)
v2.erase(unique(v2.begin(), v2.end()), v2.end());
for (int i = 0; i < N; i++)
{
// v2에서 v[i]값을 찾는다.
int idx = lower_bound(v2.begin(), v2.end(), v[i]) - v2.begin(); // log(n)
cout << idx << " ";
}
return 0;
}4. 풀이 과정
처음엔 단순히
find()로 접근해서 시간초과가 났다.
..제출 코드와 동일한 부분
for (int i = 0; i < N; i++)
{
int idx = find(v2.begin(), v2.end(), v[i]) - v2.begin(); // O(n)
cout << idx << " ";
}이렇게
find()로 접근한다면 시간복잡도가O(n)이기 때문에 문제에서 제시했던 제한사항1 ≤ N ≤ 1,000,000에서 최악의 경우인1,000,000일 경우 시간초과가 날 수 밖에 없었다.
그래서O(n)보다 빠른 검색 방법을 생각해봤는데 이진탐색 기반의lower_bound()를 이용하면O(log n)의 시간으로 원하는 값의 인덱스를 알 수 있었다.
사용 방법은lower_bound(first iterator, last iterator, value)을 이용하여 이터레이터를 반환받고 인덱스를 알기 위해서는- first iterator를 해주면 된다.
아래 코드를 이용해서 index를 알 수 있었다.
int idx = lower_bound(v2.begin(), v2.end(), v[i]) - v2.begin()
5. 결과

클라이언트 개발자가 되는 그날까지 👊