알고리즘 7일, 8일, 9일차
(2021.06.21 - 23)
30번 - 회전하는 큐
찾으려는 숫자 리스트를 오른쪽 왼쪽으로 조건에 맞게 리스트 배열을 움직여서 인덱스 0번째에서 뽑아내는 최소 횟수를 구하는 문제이다.
deque를 활용하는 것이 좋은데(시간복잡도를 낮춰줌) 일단 이 문제에서는 일반 리스트 내장함수를 활용해서 풀었다.
개념
- 큐 란?
자료구조의 일종이다. 스택과 달리 FIFO(선입선출)의 구조를 갖는다. 리스트에서 보면 오른쪽으로 append되고 왼쪽으로 pop 된다.
풀이
-
처음 큐의 크기에 관한 n을 입력받고 뽑으려는 수의 갯수를 입력받는다.
-
왼쪽, 오른쪽으로 이동할 때마다 횟수를 세야하므로 count 변수를 만들어준다.
-
찾고 싶은 숫자를 찾을 때까지 while 문을 돌고, 그것을 총 찾으려는 숫자만큼 for문으로 반복한다.
-
큐라는 리스트는 오른쪽, 왼쪽으로 회전하고 또 값을 빼내기도 하므로 리스트의 길이와 인덱스에 해당하는 값들이 가변적이다.
-
때문에 찾으려는 숫자가 해당 큐의 왼쪽에 있으면 왼쪽으로 돌리고 오른쪽에 가까우면 오른쪽으로 돌린 뒤 숫자를 찾으면 큐와 찾는 숫자 리스트에서 해당 값을 pop 해준다.
from sys import stdin
n, m = map(int, stdin.readline().rstrip().split())
# result_list = []
count = 0
goal = list(map(int, stdin.readline().rstrip().split()))
q = list(range(1, n + 1))
for _ in range(len(goal)): # 목표 숫자갯수만큼 반복
while q[0] != goal[0]: # 목표 숫자를 찾을 때 까지 반복
if goal[0] in q[int(len(q)//2) + 1:]: # 찾는 숫자가 큐의 오른쪽에 있으면 오른쪽으로 회전시키라는 조건
q.insert(0, q[-1]) # 오른쪽 끝 값을 왼쪽에 추가
q.pop() # 오른쪽 값 제거
count += 1
else:
q.append(q[0]) # 왼쪽에 있으면 오른쪽에 값 추가
q.pop(0) # 왼쪽 값 제거
count += 1
if q[0] == goal[0]: # 일치하는 값 찾으면
# result_list.append(q[0]) # 문제 풀때 썼던 참고용 리스트
q.pop(0) # 큐에서 해당 값 삭제
goal.pop(0) # 찾는 값에서 삭제
print(count)포인트
-
오른쪽으로 돌때 리스트의 왼쪽에 값을 추가해 줘야하기 때문에 insert함수를 사용했다.
-
기본 리스트로 이러한 동작을 구현하기 위해서는 리스트의 모든 원소를 한칸씩 이동시켜야하므로 시간복잡도가 O(N)이된다.
-
이때문에 deque를 사용해서 appendleft(), popleft()를 사용해서 시간복잡도를 낮추는 것이 훨씬 효율적이다.
31번 - 큐 구현
조건에 맞게 큐를 구현하는 문제다.
풀이
- 클래스를 만들어서 큐를 구현한다.
클래스 개념 - 22번 참고
# PyPy3 으로는 맞다고 나옴
from sys import stdin
class Node():
def __init__(self, data):
self.data = data
self.next = None
class Queue():
def __init__(self):
self.head = None
self.tail = None
self.len = 0
def push(self, data):
new_data = Node(data)
self.len += 1
if self.head == None:
self.head = new_data
self.tail = new_data
else:
self.tail.next = new_data
self.tail = new_data
return
def empty(self):
if self.head is None:
return 1
else:
return 0
def pop(self):
if self.empty() == 1:
return -1
else:
pop_data = self.head.data
self.head = self.head.next
self.len -= 1
return pop_data
def size(self):
return self.len
def front(self):
if self.empty() == 1:
return -1
else:
return self.head.data
def back(self):
if self.empty() == 1:
return -1
else:
return self.tail.data
queue = Queue()
n = int(stdin.readline())
for _ in range(n):
cmd = stdin.readline().rstrip().split()
if cmd[0] == 'push':
queue.push(int(cmd[1]))
elif cmd[0] == 'pop':
print(queue.pop())
elif cmd[0] == 'size':
print(queue.size())
elif cmd[0] == 'empty':
print(queue.empty())
elif cmd[0] == 'front':
print(queue.front())
elif cmd[0] == 'back':
print(queue.back())- deque를 활용한다.
-
먼저 클래스로 노드를 활용하여 큐를 구현하면 pypy3에서 정상적으로 처리되지만 데이터 처리 속도에 불리한 파이썬을 사용하게 되면 시간초과로 처리가 된다.
-
따라서 시간복잡도를 낮출 수 있는 deque를 사용해야하는 문제다.
deque 함수 종류
# 덱 사용 = deque
from sys import stdin
from collections import deque
deq = deque()
n = int(stdin.readline())
count = 0
for _ in range(n):
cmd = stdin.readline().rstrip().split()
if cmd[0] == 'push':
count += 1
deq.append(cmd[1])
elif cmd[0] == 'pop':
if count == 0:
print(-1)
else:
count -= 1
print(deq.popleft())
elif cmd[0] == 'size':
print(count)
elif cmd[0] == 'empty':
if count == 0:
print(1)
else:
print(0)
elif cmd[0] == 'front':
if count == 0:
print(-1)
else:
print(deq[0]) # deq = dequeue() 여기서 () 안에 리스트가 들어갈 수도 있고 그냥 쓰면 문자열 형태로 들어감 그래서 deq[0] 이렇게 쓸수있는 것
elif cmd[0] == 'back':
if count == 0:
print(-1)
else:
print(deq[-1]) 32번 - DFS와 BFS
탐색의 개념이 잡히지 않은 상태로 문제를 접해서 굉장히 어려웠지만 이 문제로 깊이우선탐색과 너비우선탐색의 개념을 잡을 수 있었다.
- 탐색을 위해서는 노드와 인접노드의 관계를 나타낼 수 있는 그래프 (리스트를 value로 갖는 딕셔너리형태나 리스트형태 등)가 필요하다. 이때 이 그래프는 정렬되어 있는 리스트를 가져야한다.
개념
- DFS (depth first search) : 깊이 우선 탐색
스택의 특성을 이용해서 최근에 탐색한 노드의 인접노드를 가장 최신에 탐색해야할 리스트에 저장해두고 우선으로 탐색하는 방식이다. 이렇게하면 루트에 인접되어 있던 노드 중 처음 탐색하게 된 노드를 제외한 나머지 노드의 순서가 처음 탐색을 들어가게 된 노드 가지의 인접노드보다 뒤로 밀리면서 깊이 탐색의 모양새를 가지게 된다.
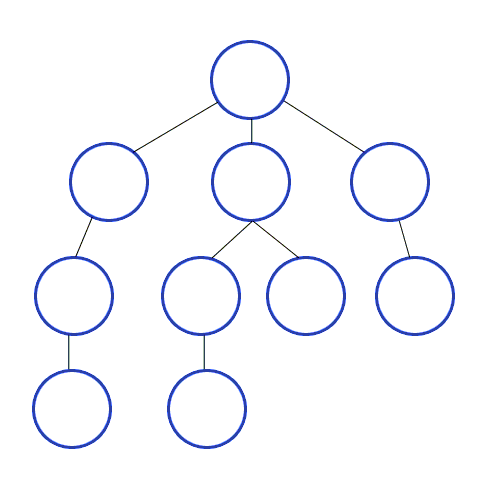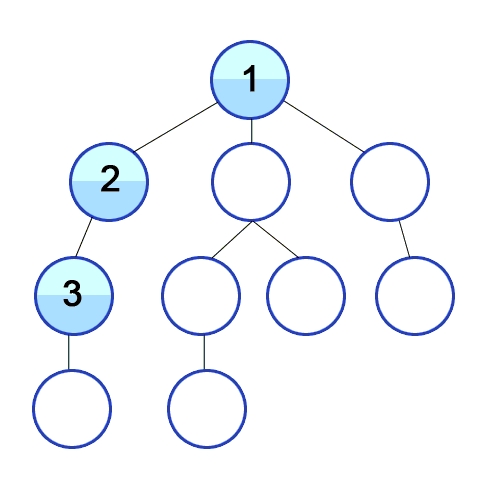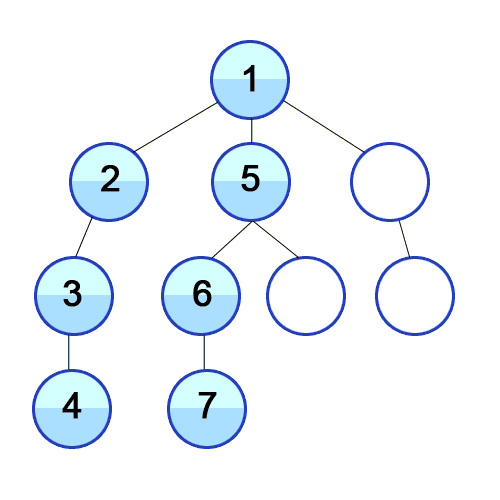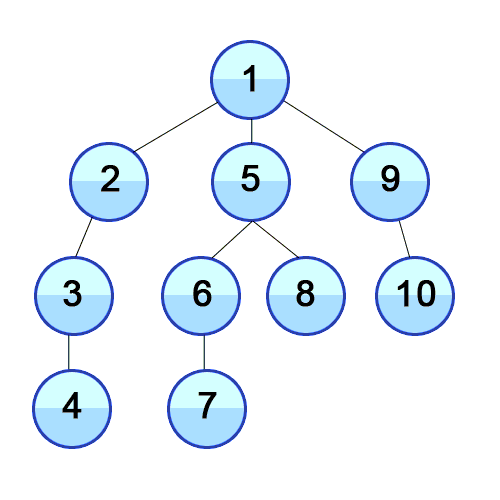
- BFS (breadth first search) : 너비 우선 탐색
큐 자료구조를 사용해서 현재 노드의 탐색이 완료되면 가장 처음 인접노드로 저장해뒀던 노드의 탐색으로 넘어가는 형식이다. BFS를 구현할때 즉, 큐를 구현할 때는 리스트의 append와 pop(0)을 사용하게 되면 시간복잡도가 O(N)이 되기때문에 지양해야한다. 따라서 collections 라이브러리의 deque를 사용하며, 방문하지 않은 인접노드를 선별하기 위해서 set 타입을 잘 활용해야한다.
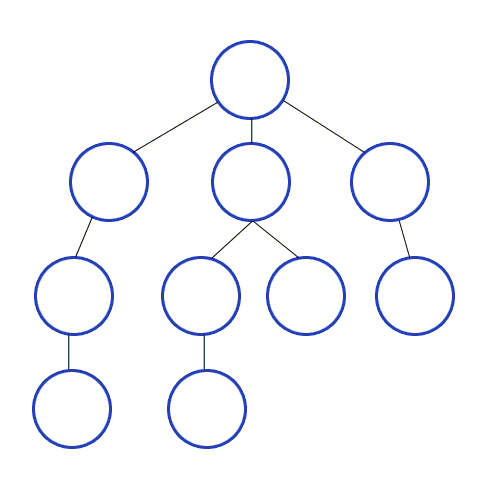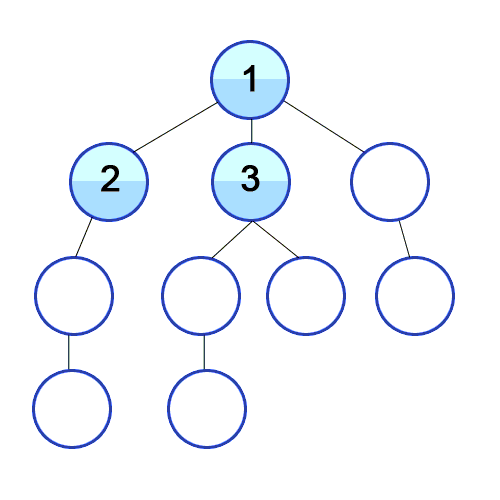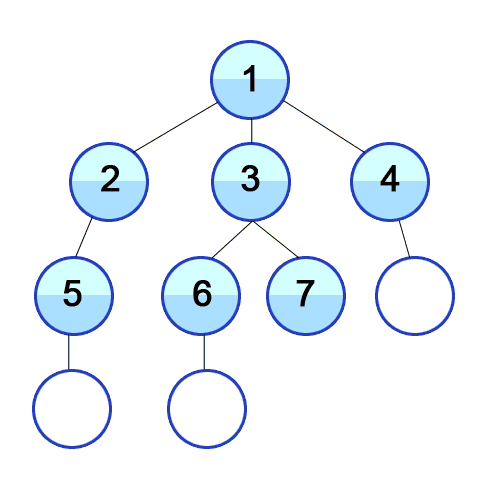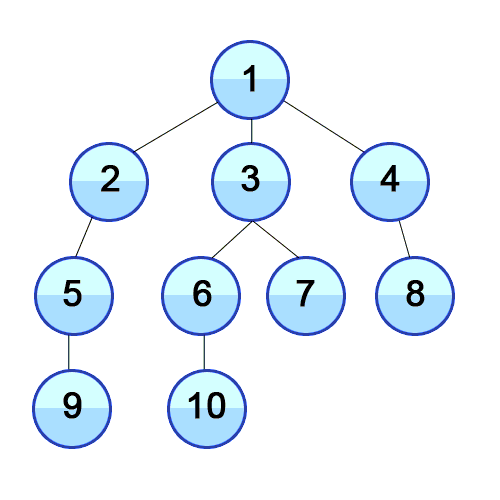
출처 및 참고 링크
풀이
- BFS 함수 구현
from collections import deque # 큐에서 pop 할때 시간복잡도를 낮춰줌
def bfs(graph, v):
visit = []
queue = deque([v])
while queue:
node = queue.popleft() # 맨처음 들어온 값을 뽑아냄, 선입선출로 여기서 넓이 탐색의 특색이 나타남
if node not in visit: # 중복으로 큐에 들어온 노드값이 여기서 걸러짐 ex) queue = [4, 4, 4]일때 결국 다 방문한 거라서 다 popleft로 빠져나가고 종료됨
visit.append(node)
if node in graph: # 이 부분 없으면 key error 발생함.
temp = list(set(graph[node]) - set(visit)) # graph의 value인 리스트가 정렬되지 않은 상태이므로 정렬 후 이미 검토한 내용을 빼줌
temp.sort() # set은 순서가 없어서 위에 리스트로 만든걸 다시 정렬 해줘야 함. 참고로 셋은 정렬도 못함 리스트만 가능. 순서대로 큐에 더해져야 넓이 탐색 순서를 제대로 지킬 수 있음
queue += temp
return " ".join(str(i) for i in visit)-
deque를 사용할 수 있는 큐 리스트(앞으로 방문해야할 인접노드를 저장해두는 곳)와 이미 방문한 노드를 저장할 visit 리스트가 필요하다.
-
큐가 빈리스트가 되기 전까지는 반복문을 계속 돌면서 가장 처음 저장된 인접노드를 popleft()로 데이터를 들고온다.
-
만약 그 노드 값이 visit에 없다면 이 순간부터 방문했다는 의미로 visit에 추가해주고, 그 값이 그래프에 있다면 인접노드 리스트에서 이미 방문한 노드를 제외하고 큐에 추가해준다.
-
여기서 중요한 것은 set은 우리 눈에는 정렬된 값처럼 보이지만 실제로는 인덱스를 갖지않는 순서가 없는 자료형이므로 다시 list화 시켜서 sort해주어야 제대로된 값이 출력된다. (bfs, dfs 동일)
-
정렬할 때, 조건에 따라 reverse=True 를 해야할 때도 있다.
-
큐의 인접노드를 모두 방문했다면 queue가 0이되면서 반복문을 탈출하고 방문한 노드를 반환하도록 한다.
- DFS 함수 구현
from collections import deque # 큐에서 pop 할때 시간복잡도를 낮춰줌
def dfs(graph, v):
visit = []
stack = [v]
while stack:
node = stack.pop()
if node not in visit:
visit.append(node)
if node in graph:
temp = list(set(graph[node]) - set(visit))
temp.sort(reverse=True) # 스택은 뒤에서 마지막에 넣은게 빠지기 때문에 리버스해줘야 순서대로 잘 찾을 수 있음
stack += temp # 가장 최근에 탐색한 노드의 인접한 노드가 스택 뒤에 다시 들어가게 됨
return " ".join(str(i) for i in visit)- BFS와 거의 같은 구성을 가진다. 대신에 stack을 사용하며, 정렬할 때 reverse=True를 사용하여 stack에 추가해 주어야 우리가 원하는 순서대로 탐색하는 것을 확인할 수 있다.
- 그래프 구현하기
입력받은 인접노드 정보를 가공하여 key값으로는 정점 숫자를 가지고 value로 인접노드의 숫자를 리스트로 가지는 딕셔너리를 만들어준다.
n, m, v = map(int, stdin.readline().rstrip().split())
connect_list = [stdin.readline().rstrip().split() for _ in range(m)]
graph = {}
for x, y in connect_list:
x = int(x)
y = int(y)
if x not in graph: # 정점이 그래프에 없으면
graph[x] = [y] # 인접노드를 value로 가지고 key값이 정점인 딕셔너리를 만들어준다.
elif y not in graph[x]: # 해당 정점이 이미 있지만 인접노드 정보가 해당 key의 value값에 없는 경우
graph[x].append(y) # value에 추가해준다.
if y not in graph: # 반대도 똑같은 생각으로 구현해준다.
graph[y] = [x]
elif x not in graph[y]:
graph[y].append(x)포인트
-
x, y 양방향으로 딕셔너리에 추가해주는 것이 포인트
-
dfs, bfs 함수를 작성할 때 이 코드가 빠지면 value error가 뜬다. 아무래도 해당 조건을 걸어주지 않으면 생기는 예외가 있는 것 같다.
if node not in visit:
- 추가로 알고리즘 강의의 코드형식으로 함수를 작성할 수도 있다.
def bfs(graph, v):
visit = []
queue = deque([v])
while queue:
# print(queue)
node = queue.popleft() # 맨처음 들어온 값을 뽑아냄, 선입선출로 여기서 넓이 탐색의 특색이 나타남
if node not in visit: # 중복으로 큐에 들어온 노드값이 여기서 걸러짐 ex) queue = [4, 4, 4]일때 결국 다 방문한 거라서 다 popleft로 빠져나가고 종료됨
visit.append(node)
if node in graph:
for v_node in sorted(list(graph[node])):
if v_node not in visit:
queue.append(v_node)- 노드가 그래프에 있는지 확인하는 조건절까지는 같고, 해당 노드의 value 값이 방문한 리스트에 없으면 큐에 추가하라는 방식이다. 개념은 같다.
33번 - 통계학
산술평균, 중앙값, 최빈값, 범위를 구하는 문제다. 특별한 부분은 없고 statistics의 함수들을 활용해서 풀어야한다.
참고 링크
from sys import stdin
import statistics
n = int(stdin.readline())
num = [int(stdin.readline().rstrip()) for _ in range(n)]
num.sort()
mean = statistics.mean(num)
median = statistics.median(num)
mode = statistics.multimode(num)
if len(mode) > 1:
mode = mode[1]
else:
mode = mode[0]
range = num[-1] - num[0]
print(round(mean), median, mode, range, sep='\n')- 포인트는 최빈값을 구할때 최빈값이 여러개인 경우를 문제의 조건에 맞게 처리해주는 것이다.
34번 - 분할정복
큰 문제를 작은 문제로 쪼개어서 풀이하는 개념인데, 비슷하게 헷갈리는 개념으로는 백트랙킹과 동적 계획법 등이 있다. 분할 정복은 작게 나누어 생각할 수 있는 문제이지만 각각의 분할된 개념들이 서로에게 영향을 주지 않는 독립적인 분할이며 재귀함수를 활용하여 풀이하게 된다. 각각의 분할된 작은 부분들이 각각 다른조건으로 같은 함수를 공유하게 된다고나 할까
- 나누어진 4면의 상태를 정확히 파악하는 것이 중요한 것 같다.
풀이
- 각각의 나뉜 면들의 첫 시작점을 지정하고 cut 함수가 받아오는 파라미터를 잘 이해하고 설정해야 한다.
import sys
n = int(sys.stdin.readline())
matrix = [list(map(int,sys.stdin.readline().split())) for _ in range(n)]
one = 0
zero = 0
def cut(x, y, n): # x, y는 좌표 시작점, n은 변의 길이 / x가 가로같지만 리스트 인덱스 특성상 가로임
global one, zero
check = matrix[x][y]
for i in range(x, x + n):
for j in range(y, y + n):
if check != matrix[i][j]: # i가 세로, j가 가로
cut(x, y, n//2) # 1사분면
cut(x, y + n//2, n//2) # 2사분면
cut(x + n//2, y, n//2) # 3사분면
cut(x + n//2, y + n//2, n//2) # 4사분면
return
# 위 이중 반복문을 모두 돌았는데 사분면의 첫번째 좌표 check와 같다면 아래 사항 체크하게 됨
if check == 0:
zero += 1
return
else:
one += 1
return
cut(0, 0, n)
print(zero, one, sep='\n')- 여기서 받아오는 입력값 정보들을 구조화해서 보면 다음과 같은데
matrix = [[1, 1, 0, 0, 0, 0, 1, 1],
[1, 1, 0, 0, 0, 0, 1, 1],
[0, 0, 0, 0, 1, 1, 0, 0],
[0, 0, 0, 0, 1, 1, 0, 0],
[1, 0, 0, 0, 1, 1, 1, 1],
[0, 1, 0, 0, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1],
[0, 0, 1, 1, 1, 1, 1, 1]]이중 for문의 i는 세로, j는 가로 인덱스를 가리키며 각 분할면의 첫 값(check)과 같은지를 비교하게 된다.
35, 36번 - 백트랙킹 (N Queen)
백트랙킹의 개념은 오목, 체스의 개념과 비슷하다. 한수 두수를 생각해보면서 그 결과가 맞지않다면 다시 원점으로 돌아와서 다음 수를 다시 생각해나가며 경우들을 계산하며 오답을 제거해 나가는 방식이다.
- 해당 문제는 아직 구현이 어려운 관계로 더 연습할 예정이다.
37번 - 계단오르기
동적계획법 (Dynamic programming)을 이용한문제다. 동적계획법은 분할정복처럼 큰문제를 작은문제로 쪼개어 생각하는 것은 같지만 분할정복과 달리 작은 문제가 큰문제를 푸는 일에 영향을 준다는 점이다. 따라서 memorization 이라는 계산이 필요한 순간 계산해서 값을 저장해 두는 방식이 필요하다. 이것을 통해 저장했던 값을 재활용해서 사용하는 시간복잡도 O(N)의 매우!!! 효율적인 프로그래밍을 가능하게 만든다.
개념 영상 링크
참고 링크
풀이
from sys import stdin
n = int(stdin.readline())
arr = [0] * 300 # 계단 수가 3보다 작은 경우가 있어서 0으로 초기화 시켜주는 것
for i in range(n):
arr[i] = int(stdin.readline())
dp = [0] * 300 # 계단 수가 3보다 작은 경우가 있어서 0으로 초기화 시켜주는 것
dp[0] = (arr[0])
dp[1] = (max(arr[1], arr[0] + arr[1]))
dp[2] = (max(arr[1] + arr[2], arr[0] + arr[2]))
for i in range(3, n): # 맨 마지막으로 append 되는 값이 마지막 계단을 올랐을 때의 최대값
dp[i] = (max(dp[i-2] + arr[i], dp[i-3] + arr[i-1] + arr[i]))
print(dp[n - 1]) # n번째 계단에 해당하는 값 꺼내기포인트
-
3보다 작은 경우도 고려해줘야한다. 그렇지않으면 인덱스값이 3개가 안되는데 [2]를 호출하는 상황이 발생해서 에러가 발생한다.
-
그래서 초기값으로 0을 넣어서 모든 인덱스값을 채워넣어준다.
38번 - 원 접점 계산
원 좌표와 반지름이 주어질 때, 접점의 갯수를 계산하는 문제이다.
두 원의 중심사이의 거리와 각 원의 반지름 사이의 관계를 이용하여 접점이 2, 1, 0 개인 경우를 따져서 풀이하면 된다.
풀이
- 반지름, 거리 사이의 최댓값을 활용하는 풀이
from sys import stdin
n = int(stdin.readline())
for _ in range(n):
x1, y1, r1, x2, y2, r2 = map(int, stdin.readline().strip().split())
r = ((x1 - x2)**2 + (y1 - y2)**2)**0.5
R = [r, r1, r2]
max_r = max(R)
R.remove(max_r)
if r == 0 and r1 == r2:
print(-1)
elif max_r > sum(R):
print(0)
elif max_r == sum(R):
print(1)
else:
print(2)- 두 중심 사이의 거리는 피타고라스의 정리를 활용한다.
- 가장 긴 거리와 나머지 길이의 관계를 활용한다.
참고 링크
- 절대값을 활용한 풀이
from sys import stdin
n = int(stdin.readline())
for _ in range(n):
x1, y1, r1, x2, y2, r2 = map(int, stdin.readline().strip().split())
r = ((x1 - x2)**2 + (y1 - y2)**2)**0.5
if r == 0 and r1 == r2:
print(-1)
elif abs(r1 - r2) == r or r1 + r2 == r:
print(1)
elif abs(r1 - r2) < r < r1 + r2:
print(2)
else:
print(0)참고 링크
39번 - 블랙잭
카드를 중복없이 무작위로 3장 뽑았을 때 목표값에 가장 가까운 큰 수를 구하는 문제이다.
-
처음에는 random함수와 조합을 활용해서 풀려고 했지만 런타임에러 (overflowError)가 발생했다.
-
브루트포스 방법으로 모든 경우를 탐색하며 결과를 출력한다.
풀이
from sys import stdin
n, m = map(int, stdin.readline().strip().split())
cards_num = list(map(int, stdin.readline().strip().split()))
result_guess = []
for i in range(n):
for j in range(i+1, n):
for k in range(j+1, n):
sum_g = cards_num[i] + cards_num[j] + cards_num[k]
if sum_g <= m:
result_guess.append(sum_g)
print(max(result_guess))
- 삼중 반복문의 범위값을 +1 해주면서 중복을 피하는 것이 포인트
40번 - 분해합
주어진 숫자의 생성자를 찾아서 가장 작은 생성자를 출력하고 생성자가 없다면 0을 출력하는 문제다.
풀이
from sys import stdin
n = int(stdin.readline().strip())
sum_list = []
for num in range(1, n):
sum_n = num
for i in range(len(str(num))):
sum_n += int(str(num)[i])
if sum_n == n:
sum_list.append(num)
if sum_list:
print(min(sum_list))
else:
print(0)-
목표 숫자까지 1부터 모든 수의 분해합을 구해서 해당 숫자가 목표숫자의 생성자가 될 수 있는지를 확인하는 프로그램이다.
-
처음에는 몫, 나머지를 활용하려고 했으나 각 자릿수가 달라질때마다 고려할 사항이 많았다. 오히려 str, int로 형변환을 하면서 각 자리수를 더해주는 방식을 사용하니 활용도가 더 높은 코드가 만들어졌다.
소감
백트랙킹을 제외하고는 목표했던 40문제를 모두 풀어보았다는 것이 매우 뿌듯했다. 개념을 잘 모르던 문제들은 문제를 풀면서 개념을 익힐 수 있어서 의미있었다. 코딩은 수학이 아니지만 알고리즘을 수학을 잘하게 되는 방법과 같은 노선에 있다는 것을 알 수 있었다. 지금은 개념익힘책을 풀면서 개념을 몸에 익히는 시간이었다고 생각된다. 이제 이것들을 활용할 수 있는 수준이 될때까지 계속해서 꾸준히 풀어봐야한다. 문제를 푸는 힘을 기르고 점점 문제 풀이의 길이 보일 때까지 반복하며 응용력을 길러야 한다.
유튜브에도 정말 좋은 알고리즘 강의들이 있었다. 알고리즘도 막연히 혼자 끙끙거린다고 잘푸는 것이 아니다. 배우고 익히고 응용하는 연습이 많이 필요하다.
- 알고리즘에 자주 등장하는 중요한 개념들을 더 많이 연습해야한다.
백트랙킹, 분할정복, 스텍, 큐, DFS, BFS, DP 등등
