소개
현대 클라우드 환경에서 인프라 관리와 애플리케이션 배포를 효율적으로 수행하는 것은 DevOps 엔지니어의 핵심 과제입니다. 특히 Kubernetes 환경에서 AI 워크로드를 안정적으로 운영하기 위해서는 인프라의 자동화와 표준화가 필수적입니다. 이 블로그에서는 Terraform과 GitOps 원칙을 활용하여 EKS(Amazon Elastic Kubernetes Service) 클러스터를 관리하고, AI 워크로드를 효율적으로 운영하는 아키텍처에 대해 소개합니다.
아키텍처
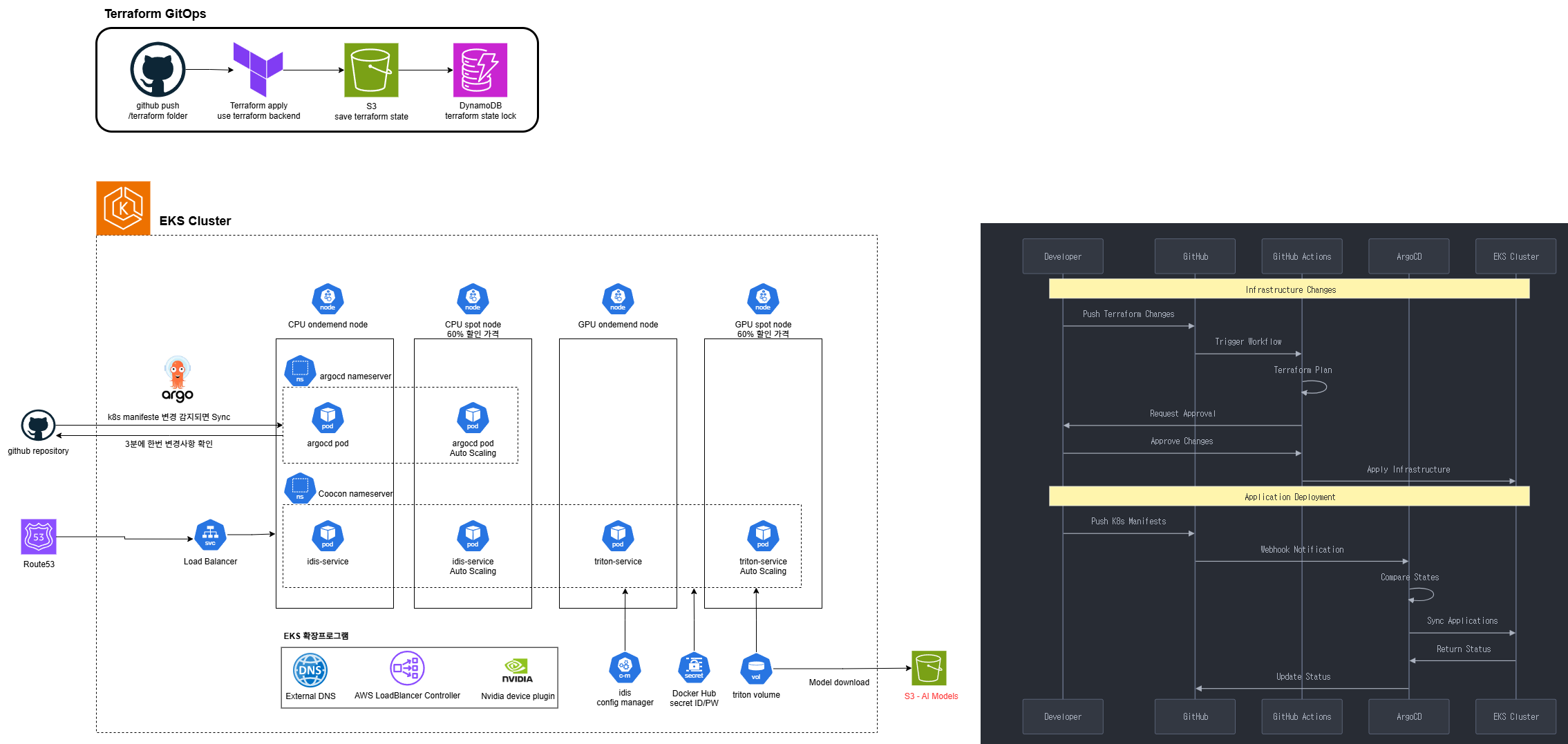
아키텍처 개요
본 시스템은 크게 두 가지 핵심 컴포넌트로 구성되어 있습니다:
- Terraform GitOps 파이프라인: 인프라 변경 관리를 위한 자동화된 워크플로우
- EKS 클러스터 및 AI 워크로드 시스템: AI 모델 서비스를 위한 확장 가능한 Kubernetes 환경
Terraform GitOps 파이프라인
구성 요소
- GitHub Repository: Terraform 코드 저장소
- Terraform Apply 단계: terraform backend를 활용한 코드 적용
- S3: Terraform 상태 파일 저장
- DynamoDB: Terraform 상태 잠금(state lock) 관리
작동 원리
- 개발자가 인프라 변경사항을 GitHub에 푸시
- 자동화된 파이프라인이 Terraform 코드를 실행
- S3에 상태 파일이 저장되고 DynamoDB를 통해 동시 실행 방지
- 변경사항이 검증되고 적용됨
GitOps 워크플로우 (오른쪽 다이어그램)
- Push Terraform Changes: 개발자가 인프라 변경사항 푸시
- Trigger Workflow: CI/CD 파이프라인 실행
- Terraform Plan: 변경 계획 생성 및 검토
- Request Approval: 변경사항 승인 요청
- Approve Changes: 책임자의 변경사항 승인
- Apply Infrastructure: 실제 인프라 변경 적용
- Push HPA Manifests: 애플리케이션 배포 설정 푸시
- Webhook Notification: 배포 알림
- Deploy Status: 배포 상태 추적
- Sync Application: 애플리케이션 동기화
- Return Status: 상태 보고
- Update Status: 최종 결과 업데이트
EKS 클러스터 구성
클러스터 구성 요소
- CPU 노드 그룹:
- 일반 워크로드용 언더멘드(ondamand) 노드
- 오토스케일링 지원 스팟(spot) 노드 (60% 할인 가격)
- Argo CD: GitOps 기반 배포 관리 도구
- 로드 밸런서: 서비스 진입점 관리
서비스 구성
- Argocd Nameserver: 배포 관리 서버
- Argocd Pod: 배포 에이전트 (Auto Scaling 지원)
- Coscon Nameserver: 추가 서비스 관리
- lds-service: AI 서비스 (Auto Scaling 지원)
- triton-service: NVIDIA Triton 추론 서비스 (Auto Scaling 지원)
인프라 관리 컴포넌트
- External DNS: 외부 DNS 관리
- AWS LoadBalancer Controller: AWS 로드밸런서 자동화
- NVIDIA Device Plugin: GPU 리소스 관리
- Config Manager: 설정 관리
- Docker Hub Secret: 이미지 레지스트리 인증
- Triton Volume: 모델 스토리지
- S3: AI 모델 저장 (KR_IDCARD_ANTHROPONMY 등)
핵심 기술적 이점
1. 인프라의 코드화(IaC)와 GitOps
이점:
- 버전 관리: 모든 인프라 변경사항이 Git으로 추적되어 감사 및 롤백 용이
- 자동화된 검증: PR 및 코드 리뷰를 통한 변경사항 검증
- 상태 일관성: Terraform 상태 파일을 통한 드리프트 방지
- 협업 효율성: 개발자와 운영팀 간 명확한 작업 흐름
2. 비용 효율적인 EKS 클러스터 설계
이점:
- 스팟 인스턴스 활용: 스팟 노드 사용으로 60% 비용 절감
- 자동 스케일링: 워크로드 요구에 따른 리소스 자동 조정
- 리소스 최적화: GPU 노드의 효율적인 활용
3. AI 워크로드에 최적화된 아키텍처
이점:
- GPU 가속: NVIDIA 디바이스 플러그인을 통한 GPU 최적화
- 모델 관리: S3와 Triton 볼륨을 활용한 효율적인 모델 관리
- 고가용성: 자동 스케일링과 로드 밸런싱을 통한 안정적인 서비스
- 보안: 시크릿 관리와 접근 제어를 통한 보안 강화
4. 지속적 배포 및 모니터링
이점:
- 자동화된 배포: ArgoCd를 통한 선언적 배포 관리
- 상태 동기화: Git 레포지토리와 클러스터 상태의 지속적 동기화
- 가시성: 배포 상태 및 결과에 대한 실시간 모니터링
- 롤백 용이성: 문제 발생 시 이전 상태로 신속한 복원
실제 구현 사례
이 아키텍처를 통해 다음과 같은 AI 서비스를 성공적으로 운영할 수 있었습니다:
- 신분증 인식 서비스: 신분증에서 개인정보 추출
- 얼굴 검출 서비스: 신분증 내 얼굴 영역 감지
- 텍스트 탐지 및 인식: 문서 내 텍스트 처리
이러한 서비스들은 Triton 추론 서버를 통해 효율적으로 제공되며, 트래픽 증가 시 자동으로 스케일링되어 안정적인 성능을 유지합니다.
구현 시 고려사항 및 교훈
1. Terraform 상태 관리
S3와 DynamoDB를 활용한 상태 관리는 팀 협업 시 매우 중요합니다. 상태 파일의 안전한 관리와 잠금 메커니즘을 통해 동시 변경으로 인한 충돌을 방지할 수 있었습니다.
2. EKS 노드 그룹 설계
온디맨드와 스팟 인스턴스를 혼합하여 사용함으로써 비용과 안정성 사이의 균형을 맞추는 것이 중요했습니다. 중요 서비스는 온디맨드 노드에, 확장 가능한 워크로드는 스팟 노드에 배치하는 전략이 효과적이었습니다.
3. CI/CD 파이프라인 설계
인프라 변경과 애플리케이션 배포를 분리하면서도 연동된 파이프라인을 구축하는 것이 중요했습니다. 이를 통해 인프라 변경 후 자동으로 애플리케이션 배포까지 이어지는 완전한 자동화를 달성할 수 있었습니다.
4. GPU 리소스 관리
AI 워크로드에서 GPU는 가장 비싼 리소스이므로 효율적인 관리가 필수적입니다. NVIDIA 디바이스 플러그인과 Kubernetes의 리소스 할당 기능을 활용하여 GPU 활용도를 최적화했습니다.
결론
Terraform GitOps와 EKS를 활용한 이 아키텍처는 AI 워크로드를 안정적으로 운영하면서도 인프라의 자동화와 표준화를 달성할 수 있는 효과적인 접근 방식입니다. 특히 인프라의 변경 관리를 코드로 관리하고, 검증된 파이프라인을 통해 배포함으로써 운영 안정성을 크게 향상시킬 수 있었습니다.
이러한 방식은 단순히 AI 워크로드 뿐만 아니라 다양한 클라우드 네이티브 애플리케이션에도 적용할 수 있는 확장성 있는 접근법입니다. 앞으로도 클라우드 환경에서의 인프라 관리와 애플리케이션 배포는 이러한 GitOps 원칙을 중심으로 발전해 나갈 것으로 전망됩니다.
