
6주 동안 실전 프로젝트를 진행하면서 학습한 내용을 기록하고, 팀의 리더로서 프로젝트 매니징 경험을 기록하는 시리즈입니다.
요구 사항
한국특허정보원에서 개발한 언어모델 KorPatELECTRA 사용자 정의 사전을 적용해야 한다.
1. 서버 구축
1) EC2 인스턴스 생성
| 인스턴스 크기 | vCPU | 메모리(GiB) |
|---|---|---|
| t2.xlarge | 4 | 16 |
2) 엘라스틱서치의 힙메모리 설정은 전체 메모리의 50%를 넘게 되면 메모리 오버헤드로 인해 실행이 되지 않는 것을 확인했습니다. 따라서 엘라스틱서치의 힙메모리는 다음과 같이 정하였습니다.
- Elasticsearch: 8GB, Kibana(키바나)-1.4GB
3) 노드 역할별 분리
- 데이터의 무결성 확보와 검색 속도 성능 개선을 위해 노드를 마스터노드 1개와 데이터 노드 2개로 분리하였습니다.
4) KorPatELECTRA 사용자 정의 사전을 적용하기 위해 노드별로 pat_dic_v3.txt파일을 저장했습니다
문제 상황
로컬에서는 사용자 정의 사전을 적용하여도 인덱스 생성에 문제가 없었습니다. 그래서 사용자 정의 사전을 적용하여 테스트를 진행했는데, 서비스 배포용 EC2 서버에서는 인덱스 생성시 메모리의 오버헤드 문제가 발생하였기 때문에 기존 메모리 설정을 조정해야 했습니다.
현재 Elasticsearch의 사용자 계정인 patent의 limits.conf 설정은 다음과 같습니다.
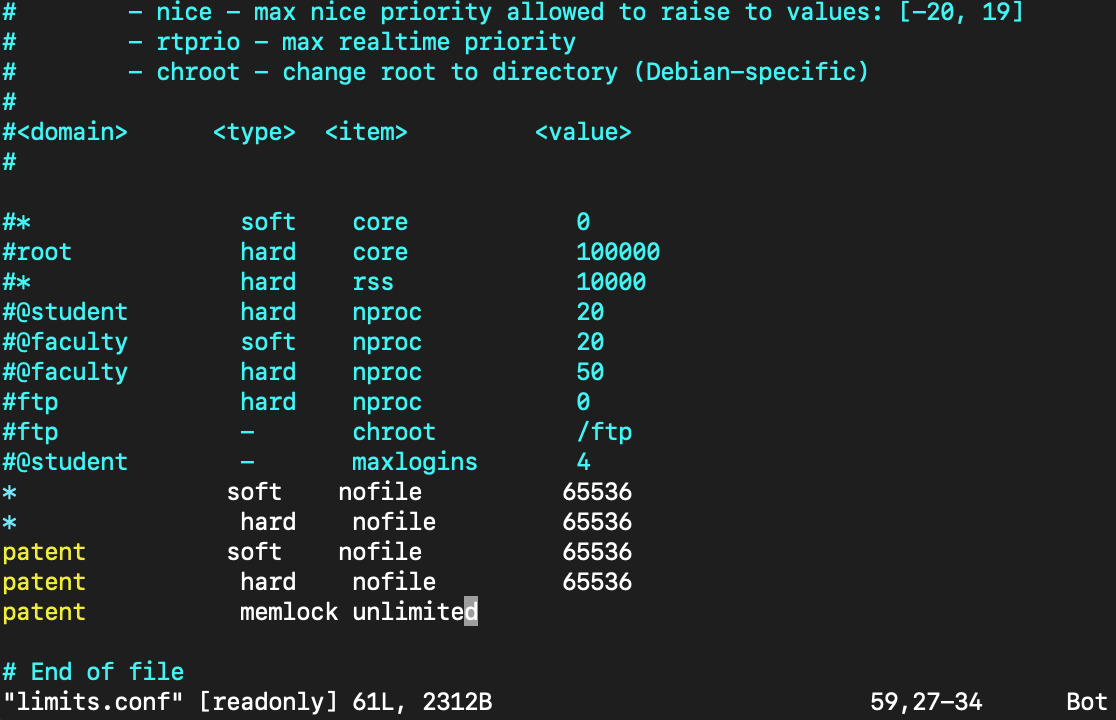
선택지
1안
인덱싱을 담당하는 마스터 노드의 힙메모리 설정을 높인다.
-
EC2 xlarge 인스턴스의 메모리는 16GiB
-
기존) 마스터노드- 1GB , 데이터노드1- 3GB, 데이터노드2- 3GB
→ GC Overhead → shard의 배치가 false가 된다. unsigned node에 배치가 실패한 샤드들이 생김인덱스 설정 리퀘스트 결과:

-
변경 1) 마스터노드- 2GB, 데이터노드1,2- 3GB → 같은 문제로 실패하였습니다
-
변경 2) 마스터노드- 4GB, 데이터노드1,2- 2GB → 같은 문제로 실패하였습니다.
2안
레플리카 샤드의 수를 0으로 인덱스를 생성한 뒤 인덱스 설정을 1로 변경한다.
→ 한번에 들어가는 프로세스를 줄이기 위한 목적.
- 마스터노드의 힙메모리 설정 최대치인 4GB인 상태에서 프라이머리 샤드 값만 3으로 해서 인덱스를 생성합니다.
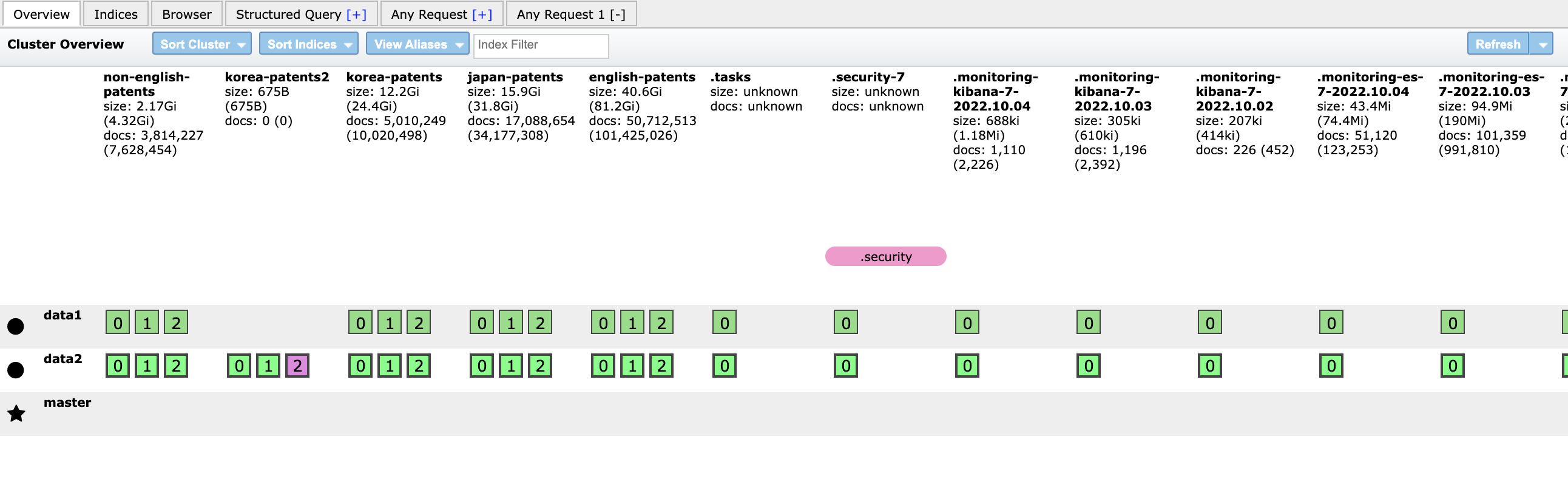
→ 생성시 프라이머리 샤드가 만들어졌지만 배치가 하나의 노드로 몰립니다.
→ 레플리카 샤드의 설정을 1로 재설정합니다.
→ 1안과 같은 문제로 실패하였습니다.Put/korea-patents { "settings": { "index": { "number_of_replicas": 1 } } }
3안
korea-patents 인덱스만 프라이머리 샤드의 수를 1개로 줄여서 생성한다.
- 2안과 같은 에러로 인해 실패하였습니다.
4안
EC2 인스턴스의 메모리 용량을 업그레이드
- 프로젝트 마감기한이 임박하여 테스트를 하지 못했습니다.
의견 조율
- 1안 - 실패
- 2안 - 실패
- 3안
- 샤드의 수가 늘어날수록 검색 소요 시간 성능이 늘어나는 것을 확인했지만 리소스의 한계로 검색 정확도 성능의 개선을 못하는 상황
- 프라이머리 샤드의 수를 1로 줄이고 레플리카를 1개로 설정하여 인덱스 생성
- pat_dic_v3.txt 사전 설정을 뒤로 미루고 기존에 작성한 인덱스 매핑 정의와 쿼리를 개선하여 정확도를 더 높이는 방법
- 4안
- 테스트를 하기에 시간이 부족한 상황
의견 결정
- 인덱스 매핑 정의와 쿼리 개선을 통한 검색 정확도 향상으로 선택
→ 테스트 완료 : 사용자 정의 사전을 적용하지 않은 상태에서도 적용한 것과 동일한 검색 결과 정확도를 얻을 수 있었기 때문에 사용자 정의 사전을 적용하지 않기로 결정하였습니다.
테스트 과정 확인👉 오타 교정 기능 적용 이후 검색 결과 정확도 향상을 위한 인덱스 매핑 변경 과정-②
- 추후 인스턴스 업그레이드를 통해 사용자 정의 사전을 적용해 보기로 하였습니다.
