
6주 동안 실전 프로젝트를 진행하면서 학습한 내용을 기록하고, 팀의 리더로서 프로젝트 매니징 경험을 기록하는 시리즈입니다.
고민 지점 및 의사결정
1. search_analyzer를 사용해야 하는가?
기본적으로 text 필드는 match 쿼리로 검색을 할 때 색인에 사용한 동일한 애널라이저로 검색 쿼리를 분석합니다. 하지만 nori analyzer를 사용해보니 형태소 분석이 정확하지 않다고 판단하였고, ‘search_analyzer를 따로 사용해야 하는 가’에 대한 고민이 있었습니다.
몇 번의 테스트를 반복한 결과, 텍스트에서 정확한 뜻을 가진 명사, 동사, 어근 등을 남기고 다른 부분을 제거한다면 저희가 원하는 검색이 가능하다고 판단하였고, search_analyzer를 적용하지 않기로 결정했습니다.
2. 어떤 데이터 타입을 지정할까?
-
[출원일자] 필드가 사용되는 경우
1) 드롭다운으로 ‘연도’를 선택하고 ‘연도’를 입력하면 출원일자 필드에서 데이터를 찾아 반환한다.
MVP 때는 [출원일자] 필드가 ‘keyword’ 타입으로 동적 매핑되어 연도만 검색할 수 없었습니다. 그래서 와일드카드 쿼리를 사용했습니다.


2) 날짜 범위를 지정하여 해당 범위에 해당하는 데이터만 반환하는 기능을 추가할 수 있습니다. Range Query를 데이터 타입에 상관없이 활용할 수 있는지 확인이 필요합니다.
Range Query 파라미터 - gte (Greater-than or equal to) - 이상 (같거나 큼) - gt (Greater-than) – 초과 (큼) - lte (Less-than or equal to) - 이하 (같거나 작음) - lt (Less-than) - 미만 (작음)
ES가 쿼리를 실행하는 데 걸린 시간(took) 비교 테스트
📌 동일한 데이터 2만 건으로 인덱스 생성, 최대 반환: 15000 건
case 1) date 타입, Range Query 사용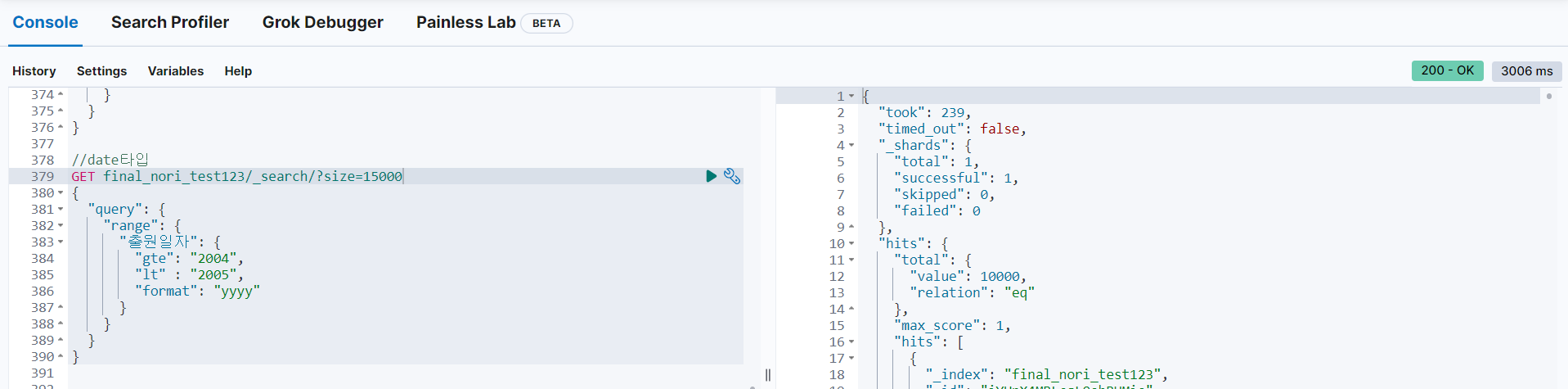 [출원일자] 필드를 date 데이터 타입으로 매핑하고, Range Query를 사용하여 2004년 데이터만 검색했을 때 took = 239
[출원일자] 필드를 date 데이터 타입으로 매핑하고, Range Query를 사용하여 2004년 데이터만 검색했을 때 took = 239
case 2) text 타입, Range Query 사용
 [출원일자] 필드를 text 데이터 타입으로 매핑하고, Range Query를 사용하여 2004년 데이터만 검색했을 때 took = 246
[출원일자] 필드를 text 데이터 타입으로 매핑하고, Range Query를 사용하여 2004년 데이터만 검색했을 때 took = 246
case 3) text 타입, Wildcard Query 사용

[출원일자] 필드를 text 데이터 타입으로 매핑하고, Wildcard Query를 사용하여 2004년 데이터만 검색했을 때 took = 532
case 4) text 타입, Analyzer 적용
 [출원일자] 필드를 text 데이터 타입(Pattern Analyzer를 적용)으로 매핑하고, 2004년 데이터만 검색했을 때 took = 206
[출원일자] 필드를 text 데이터 타입(Pattern Analyzer를 적용)으로 매핑하고, 2004년 데이터만 검색했을 때 took = 206
테스트 결과
text 데이터 타입(Pattern Analyzer 적용)으로 매핑했을 때 반환 속도가 206ms로 가장 빨랐기 때문에 이 방식을 사용하기로 결정했습니다.
3. [출원일자] 멀티 필드의 필요성?
- 출원일자가 keyword 타입도 가질 필요가 있을까요? mvp 기능에는 없던 내용이지만, 만약 keyword 타입이면 오름차순, 내림차순 정렬이 가능합니다.
⇒ 논의 결과, [출원일자]로 정렬하는 기능이 있으면 좋을 것 같아서 [출월일자]를 멀티 필드로 매핑하기로 결정했습니다.
인덱스 매핑 정의
PUT nori-test
{
"settings": {
"index": { //1️⃣샤드 수는 클러스터 설계가 완료된 후 변경할 계획입니다.
"number_of_shards": 1,
"number_of_replicas": 1
},
"analysis": {
"analyzer": { // 2️⃣애널라이저
"nori_analyzer": {
"type": "custom",
"tokenizer": "korean_nori_tokenizer",
"filter" : ["nori_posfilter"]
},
"number_analyzer" : {
"type" : "pattern",
"pattern" :"[.]"
}
},
"tokenizer": { // 3️⃣토크나이저
"korean_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
},
"filter": { //4️⃣ 토큰 필터
"nori_posfilter": {
"type": "nori_part_of_speech",
"stoptags": ["J","E","NNB","MAJ","MM","XSV","XSA","VCP","SE","XSN","VCN","SP","NA","UNA","VSV","XPN","IC"]
}
}
}
},
"mappings": {
"properties": { //5️⃣ 필드에 데이터 타입 매핑
"CPC분류": {
"type": "text"
},
"IPC분류": {
"type": "text"
},
"event": {
"properties": {
"original": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"log": {
"properties": {
"file": {
"properties": {
"path": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
},
"공개번호": {
"type": "keyword"
},
"공고번호": {
"type": "keyword"
},
"등록번호": {
"type": "keyword"
},
"발명의명칭": {
"type": "text",
"analyzer": "nori_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"법적상태": {
"type": "keyword"
},
"요약": {
"type": "text",
"analyzer": "nori_analyzer"
},
"출원번호": {
"type": "text",
"fields": {
"keyword" : {
"type" : "keyword",
"ignore_above": "256"
}
}
},
"출원인": {
"type": "text",
"analyzer": "nori_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"출원일자": {
"type": "text",
"analyzer": "number_analyzer",
"fields": {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}1. 샤드 설정은 클러스터 설계가 완료된 후 변경할 예정.
2. Analyzer
2.1. nori_analyzer
[발명의명칭], [출원인], [요약] 필드의 데이터에 한글 형태소 분석기(Nori)를 적용하였습니다.
2.2. number_analyzer
[출원일자] 필드의 데이터는 ‘2022.09.21’의 형태를 가집니다.
그 중에서 연도(2022)만 추출하기 위해 패턴 “[.]”을 기준으로 텍스트를 분리하는 패턴 애널라이저를 적용했습니다.
3. Tokenizer
3.1. Nori Tokenizer
nori_tokenizer가 제공하는 옵션은 다음과 같습니다.
- user_dictionary : 사용자 정의 사전 ⇒ 특허 검색 서비스의 경우, 사용자 정의 사전은 설정하기 어렵다고 판단하여 배제하였습니다.
- decompound_mode : 복합 명사를 토크나이저가 처리하는 방식을 결정
| 파라미터명 | 파라미터값 | 설명 |
|---|---|---|
| decompound_mode | none | 복합 명사로 분리하지 않는다 |
| decompound_mode | discard(default) | 복합 명사로 분리하고 원본 데이터는 삭제한다. |
| decompound_mode | mixed | 복합 명사로 분리하고 원본 데이터도 유지한다. |
⇒ 분리된 복합 명사와 원본 데이터 모두 유지하기 위해 mixed로 설정하였습니다.
4. Token Filter
4.1. nori_part_of_speech
nori_part_of_speech 토큰 필터를 이용해서 제거할 품사(POS - Part Of Speech) 코드입니다.
| 태그 | 설명 | 태그 | 설명 | 태그 | 설명 |
|---|---|---|---|---|---|
| E | 어미 | IC | 감탄사 | J | 조사 |
| MAJ | 접속 부사 | MM | 한정사 | NA | 알 수 없음 |
| NNB | 의존명사 | SE | 줄임표 | SP | 공백 |
| UNA | 알 수 없음 | VCN | 부정 지정사 | VCP | 긍정 지정사 |
| VSV | 알 수 없음 | XPN | 접두사 | XSA | 형용사 파생 접미사 |
| XSN | 명사 파생 접미사 | XSV | 동사 파생 접미사 |
5. 필드에 데이터 타입 매핑
- [출원번호] : text, keyword
- [출원일자] : text, keyword
- [발명의명칭] : text, keyword
- [출원인] text, keyword
- [IPC분류] text
- [CPC분류] text
- [공고번호] keyword
- [공개번호] keyword
- [등록번호] keyword
- [법적상태] keyword
- [요약] text
🤔 공고번호, 공개번호, 등록번호는 keyword 타입인데 출원번호는 멀티 필드(text, keyword)인 이유
- 출원번호는 10으로 시작하는지, 20으로 시작하는 지에 따라 권리 구분이 달라지고, 이를 체크박스 기능에 활용합니다.
- MVP 때는 데이터 타입을 keyword로 지정하였기 때문에 Wildcard Query를 사용해야 했습니다.

- Wildcard Query 사용을 지양하기 위해 text, keyword 두 가지 데이터 타입을 가지는 멀티 필드로 지정했습니다.
🤔 출원일자가 date 타입이 아니라 text인 이유
- case를 나누어 반환 속도 테스트를 진행한 결과, 데이터 타입이 text 일 때가 date 타입일 때보다 반환 속도가 빨랐습니다. 해당 내용은 위에 자세히 기록하였습니다.
🤔 IPC분류, CPC분류가 text 타입인 이유
- 부분적으로만 검색해도 결과 데이터를 반환하기 위함입니다.
변경 사항
오타 교정 기능을 적용한 후 인덱스 설정과 매핑 정의가 변경되었습니다.
👉오타 교정 기능 적용 이후 검색 결과 정확도 향상을 위한 인덱스 매핑 변경 과정-①
👉오타 교정 기능 적용 이후 검색 결과 정확도 향상을 위한 인덱스 매핑 변경 과정-②
