[Python] split() map() list array
split()
bytearray.split(sep=None, maxsplit=- 1)
- sep 를 구분자로 사용해서 시퀀스를 같은 형의 서브 시퀀스로 나눔
- maxsplit 만큼 분할이 수행됨
(최대 maxsplit +1 개만큼 생기고, -1이거나 지정되지 않았을 경우 분할 수에 제한이 없음) - 연속된 공백은 단일 구분자로 간주하며 시퀀스 제일 앞이나 뒤에 공백이 있어도 결과의 시작과 끝에 빈 시퀀스가 생기지는 않는다.
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']map()
map(function, iterable, ...)
iterable 의 모든 항목에 function 을 적용한 후 그 결과를 돌려주는 이터레이터를 돌려줌
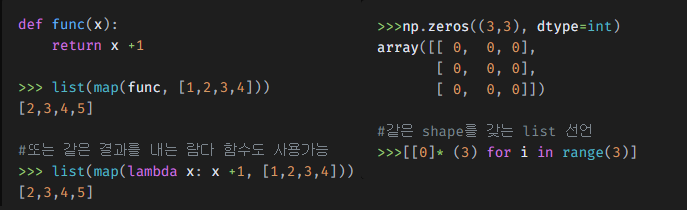
def func(x):
return x +1
>>> list(map(func, [1,2,3,4]))
[2,3,4,5]
#또는 같은 결과를 내는 람다 함수도 사용가능
>>> list(map(lambda x: x +1, [1,2,3,4]))
[2,3,4,5]dictionary 가 iterable로 사용되었을 때, 기본적으로 func는 key에 적용됨
value에 func를 적용하려면, [x[i] for i in x] 를 사용
Numpy array와 list의 차이
Numpy 의 ndarray가 python의 list보다 연산이 빠름
Numpy 는 각 배열마다 타입이 하나만 있다고 간주함
즉, ndarray 에는 동일한 타입의 데이터만 저장할 수 있음
list 는 여러 타입을 혼용해 저장할 수 있음
ndarray 에 여러 타입을 혼용해서 배열에 전달하면 모두 문자열로 변경하여 저장됨
>>> types = np.array([1, 'string', 3.14, False])
['1', 'string', '3.14', 'False']이렇게 모두 동일한 자료형으로 저장하면 각 요소에 필요한 저장공간이 일정하기 때문에
순서만 알면 바로 그 값에 접근할 수 있기 때문에 빠름
numpy 메소드
numpy.zeros(shape, dtype=float, order='C', *, like=None)
| shape | 배열의 모양, (2,3) 또는 3과 같이 지정 |
| dtype | 배열 요소의 타입 |
| order | 'C' 또는 'F' C는 row major, F는 column major |
| like | ndarray가 아닌 배열을 생성 |
>>>np.zeros((3,3), dtype=int)
array([[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]])
#같은 shape를 갖는 list 선언
>>>[[0]* (3) for i in range(3)]numpy.empty(), numpy.ones(), numpy.full() 유사한 방법으로 사용됨
numpy.empty() 의 경우 ndarray 이 쓰레기값으로 채워짐
numpy.full() 는 fill_value 값으로 ndarray 가 모두 채워짐
참고 자료

졸업하기 싫어요