![]()
1. 포스팅의 목적
개인적으로 CUDA를 학습하는데 있어 중요한 첫 걸음은 CUDA Programming Model - Thread Hierarchy을 명확히 이해하는 것이라고 생각한다.
하지만, 막상 공부를 시작하면 "Thread/Thread Block/Grid만 짚고 넘어가자니 뭔가 가려운 지점이 남는 것 같고", 그렇다고 또 "GPU Architecture까지 염두에 두고 이해해보자니 Architecture별로 너무 달리 적용되는 개념들이 많은 것 같고..." 여러모로 공부하기에는 까다로운듯 하다.
이런 고로, 본 포스팅에서는 Programming Model로서의 Thread Hierarchy와 GPU Architecture를 관련지어 이해하는 것을 목표로하되 Architecture별로 달리 적용될 수 있는 부분들은 최대한 제외하고 학습을 진행해보고자 한다.
사람에 따라 학습하는 스타일에 차이가 있겠지만 개인적으로는 간단한 CUDA 예제(벡터 합 같은)를 몇 개정도 구현해보고 본 포스팅을 읽기를 추천한다.
어차피 예제를 몇 개 돌려보면 합리적인 궁금증이 생기리라.
2. Programming Model: Thread Hierarchy
Programming Model로서의 Thread Hierarchy는 매우 심플하다.
다음 한 문장으로 요약이 가능한데, "Thread가 모여서 Thread Block이되고, Thread Block이 모여서 Grid가 된다."
조금 더 실증적인 예를 통해 설명해보도록 하겠다.
아래 some_kernel과 같이 선언된 벡터 합 Kernel이 있다고 가정해보겠다.
// CUDA kernel adding two vectors, pa and pb, and storing the result at pc
__global__ void some_kernel(std::uint8_t* pa, std::uint8_t* pb, std::uint8_t* pc);위와 같이 선언된 Kernel이 아래와 같은 Execution Configuration(<<<grid_dim, thread_block_dim>>>)을 통해 launch되었다고 가정해보자.
// Memory copy from host to device
// ...
dim3 grid_dim(2, 2, 2);
dim3 thread_block_dim(2, 2, 2);
some_kernel<<<grid_dim, thread_block_dim>>>(a, b, c);
// ...
// Memory copy from device to host이렇게 some_kernel을 Launch했을 때 프로그래머 머릿속에는 반드시 아래의 그림이 떠올라야만 한다.
(그림을 발로 그린 나머지 계속 보다보면 매직아이가 되는 것 같은 느낌이 있지만...양해해주길 바람)
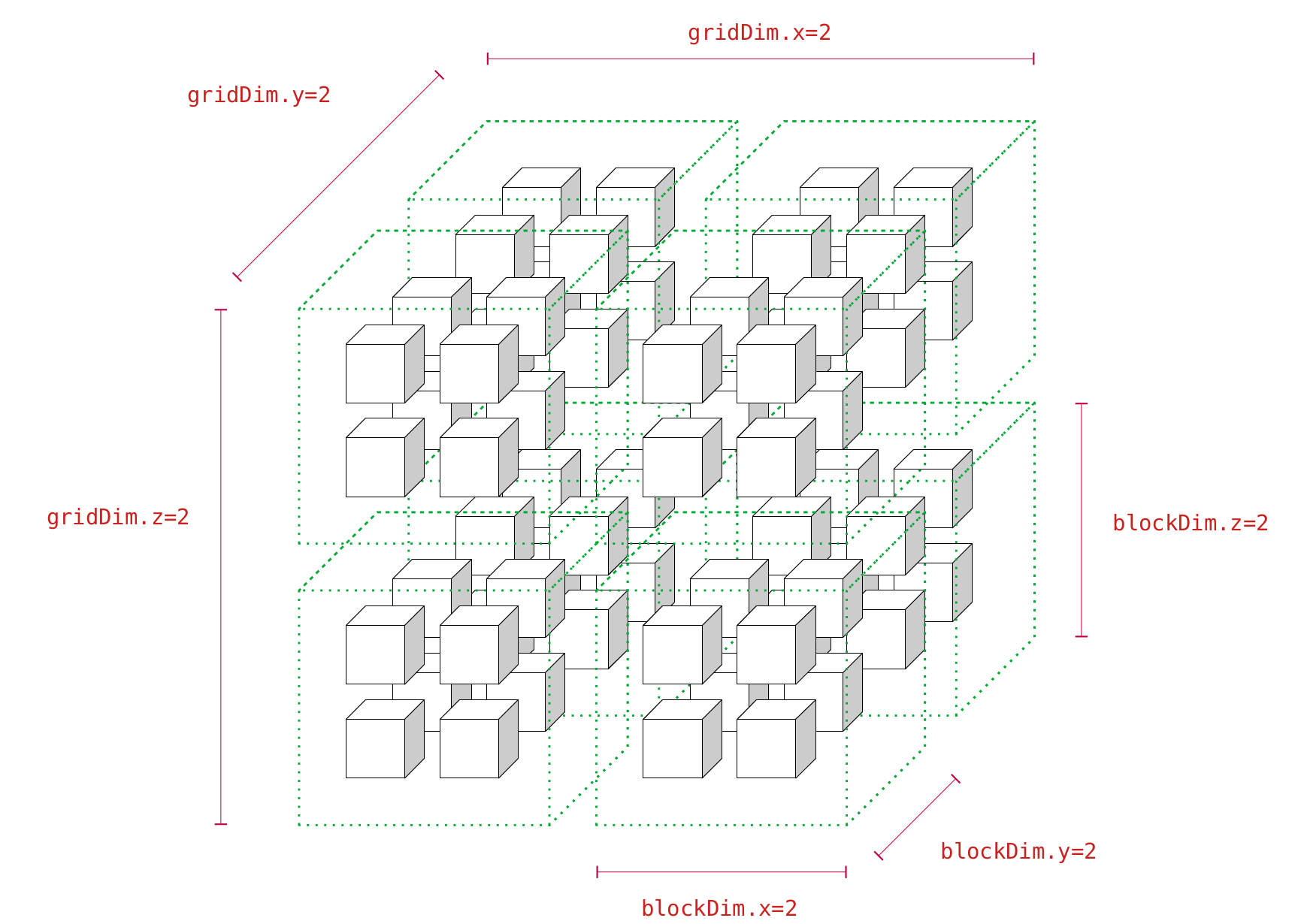
이제 이 그림에서 각각의 요소가 나타내는 바가 무엇인지 뜯어보도록 하자.
2.1. 각설탕 1개는 Thread와 같다
위에 도시한 그림은 총 64개의 각설탕(?!)을 그려놓았다.
1개의 각설탕은 1개의 Thread를 의미한다.
Thread라 함은 GPU Kernel을 구성하는 최소 단위로서(엄밀히 실행의 최소 단위는 아닌데, 이는 이어지는 섹션에서 마저 기술하도록 하겠음) some_kernel에 정의될 Function Body를 수행하는 여러 Context들 중 하나를 의미한다.
2.2. 녹색 점선 육면체 1개는 Thread Block과 같다
그림을 다시 찬찬히 뜯어보면 2x2x2, 총 8개의 Thread가 하나의 녹색 점선 육면체에 둘러쌓여 있는 것을 볼 수 있다.
이 녹색 점선 육면체 1개는 1개의 Thread Block을 의미한다.
CUDA에서는 여러 개의 Thread를 묶어 Thread Block이라는 그룹으로 관리할 수 있는데, 상기한 코드의 thread_block_dim의 정의부를 잘 살펴보면 이 그룹(Thread Block)을 어떤 모양으로 사용할지 지정한 것을 볼 수 있다.
위의 예제에서는 2x2x2 모양으로 Thread Block을 만들도록 thread_block_dim을 정의하였고, 이는 Thread Block의 각 Dimension을 나타내는 Built-in 변수들(blockDim.x, blockDim.y, blockdim.z )을 통해 some_kernel 내부에서 접근이 가능하다.
2.3. 제일 큰 육면체 1개는 Grid와 같다
마지막으로 전체 64개의 육면체의 모임인 하나의 제일 큰 육면체는 Grid를 의미한다.
직전 절에서 Thread들을 묶어 Thread Block을 정의한 것과 유사하게 CUDA는 다시 Thread Block들을 묶어 Grid라는 그룹으로 관리할 수 있다.
상기한 코드의 grid_dim의 정의부를 잘 살펴보면 Grid를 어떤 Dimension의 Thread Block들로 구성할 것인지를 지정한 것을 볼 수 있다.
예제에서는 2x2x2, 총 8개의 Thread Block으로 하나의 Grid를 구성하였으며 역시 some_kernel 내부에서 Built-in 변수들(gridDim.x, gridDim.y, gridDim.z)을 통해 접근할 수 있다.
2.4. Indexing을 해보자
필자가 예시하고 있는 some_kernel은 두 개의 벡터를 합하여 저장하는 Kernel이다.
이제 Function Body를 주행할 각 Thread가 벡터의 몇 번째 요소를 합할지 정하고(Indexing) some_kernel을 완성해보도록하자.
사실 벡터 합 같이 1-Dimensional한 문제에 굳이 위와 같이 3-Dimensional한 Thread Hierarchy를 정의하는 경우는 매우 드물지만, 보다 일반화된 설명을 위한 예제이니 이해해주기를 바란다.
// CUDA kernel adding two vectors, pa and pb, and storing the result at pc
// Let's assume that the length of arrays, pa, pb and pc is 64
__global__ void some_kernel(std::uint8_t* pa, std::uint8_t* pb, std::uint8_t* pc)
{
int block_idx = blockIdx.x * gridDim.y * gridDim.z + blockIdx.y * gridDim.z + blockIdx.z;
int thread_idx = threadIdx.x * blockDim.y * blockDim.z + threadIdx.y * blockDim.z + threadIdx.z;
int array_idx = block_idx * (blockDim.x * blockDim.y * blockDim.z) + thread_idx;
pc[array_idx] = pa[array_idx] + pb[array_idx];
}위의 코드에서는 정의한 Thread Block, Grid의 모양을 사용하여 각 Thread를 Indexing해주고 있다.
너무나 당연하게도, 이러한 Indexing은 순수하게 Logical한 Indexing이기 때문에 xyz-major로 하던, zyx-major로 하던, 심지어 변태 같이 yzx-major로 하던 아무런 상관이 없다.
필자의 경우에는 xyz-major로 진행하였는데, 우선 block_idx 변수에 "내가 Grid 내에서 몇 번째 Thread Block인가?"를 정의했다.
다음으로는 thread_idx 변수에 "내가 하나의 Thread Block 내에서 몇번째 Thread인가?"를 정의하였다.
마지막으로 위에서 구한 block_idx와 thread_idx를 사용해서 "내가 전체 Grid 내에서 몇 번째 Thread인가?"를 정의하였고, 이를 곧장 Array의 Index로 활용하였다.
상술한 일련의 Indexing을 거치고나면 간단하게 벡터 합을 위한 Kernel을 정의해줄 수 있다.
3. GPU Architecture Fundamental
사실 GPU Architecture를 정확히 설명하기 위해서는 Tesla, Fermi, Kepler, Maxwell, Pascal, Volta 등과 같은 하나의 Architecture를 정해놓고 그 구조를 논하는 것이 옳다.
하지만, CUDA의 Programming Model을 익히는 단계에서 한 Architecture를 정해놓고 기술하는 것은 매우 혼란스러울뿐더러, CUDA라는 Abstraction의 존재 의미와도 부합하지 않는다.
물론, GPGPU의 절정 초고수라면 여러 Architecture를 늘어놓으면서도 혼란스럽지 않고, CUDA라는 Abstraction 틀 안에서 내용을 설명할 수 있을 것이다.
필자는 아직 그러한 레벨에 도달하지 못했으므로, 본 섹션에서는 GPU Architecture가 변화함에도 그 큰 틀은 변하지 않는, Fundamental의 관점에서 설명을 진행해보도록 하겠다.
3.1. Overview
아래 그림은 필자가 생각하는 GPU Architecture의 Fundamental을 보이고 있다.
적어도 아래 그림에 등장하는 컴포넌트에 대해서는 자세한 설명을 이어나가보려 한다.
.png)
3.2. Thread Block Scheduler
프로그래머가 임의의 Kernel을 Launch했다고 가정하자.
이 때 Launch된 Grid는 제일 먼저 GPU의 Thread Block Scheduler 손에 떨어지게 된다.
Thread Block Scheduler는 수행해야하는 Grid를 Thread Block으로 나눈 뒤(물론 이는 섹션2.3에서 이야기한 바와 같이 프로그래머가 지정함) 각 Thread Block을 1개씩 Streaming Multiprocessor에 Round-Robin으로 Scheduling해준다.
"Streaming Multiprocessor가 뭔지도 설명하지 않고 Streaming Multiprocessor에 Round-Robin할당이라니 이런 쓰레기 같은 포스팅이 있나?"라고 생각할 수 있지만, 곧 설명할 터이니 조금만 인내를 가져주기를 바란다.
여기서는 Thread Block Scheduler가 대략 아래의 의사코드를 수행한다는 것만을 유념해두도록 하자.
sm = [sm_0, sm_1, sm_2] # Streaming Multiprocessor Array
sm_id = 0 # Streaming Multiprecessor ID
# Round-Robin Scheduing
for thread_block in grid:
if sm[sm_id].assignable(thread_block):
sm[sm_id].assign(thread_block)
sm_id = (sm_id + 1) % len(sm)3.3. Streaming Multiprocesor
보통 여러 문서에서 "SM"이라고 일컫어지는 이 컴포넌트는 상술하였듯이 Thread Block Scheduler에게 실행해야할 Thread들을 Thread Block 단위로 할당받는다.
할당받은 Thread Block을 수행하기 위해 SM 내부에는 실제로 연산을 수행할 Streaming Processor(하나의 Thread를 실행하게 될)들과 Streaming Processor에게 Thread들을 나눠주기 위한 Warp Scheduler가 들어있다.
3.4. Streaming Processor
보통 "SP"라고 줄여말하는 Streaming Processor는 실제로 Thread를 위한 연산을 수행하게되는 주체가 된다.
필자가 포스팅 내내 예시하고 있는 some_kernel을 예로 들면, some_kernel의 Function Body를 이 SP가 수행하게 된다.
참고로, 컴퓨터구조에 익숙하다면 SP를 하나의 ALU로 바라보는 안목을 길러두도록 하자.
3.5. Warp Scheduler
직전 절에서 각 SP가 하나의 Thread를 수행하게 된다고 이야기했다.
조금 더 상세히 동작을 설명하면 SP는 Thread를 수행할 때 Warp라는 단위로 싱크를 맞추게 되는데(Lockstep), 이 Warp를 SP에 할당하는 작업을 Warp Scheduler가 담당해준다.
예를 들어, SM #0에 128x1x1 Dimension의 Thread Block이 할당되었다고 해보자.
SM #0이 처리해야할 Thread의 수는 총 128x1x1=128개이므로, Warp Shceduler는 우선 128개의 Thread들을 32개씩 4개의 Warp로 나눈다(Volta 이전의 Architecture에서 1 Warp는 32 Thread로 구성됨).
편의상 Warp #0(Thread #0~31), Warp #1(Thread #32~63), Warp #2(Thread #64~95), Warp #3(Thread #96~127)이라고 하자.
다음으로 Warp Scheduler는 SP들이 Thread를 실제로 수행하도록 각 Warp를 SP에 할당한다.
필자가 예시했던 GPU Architecture에서는 하나의 SM이 64개의 SP를 가지고 있으므로 Warp Scheduler는 아래 그림과 같이 Warp #0을 SP #0~31에, Warp #1을 SP #32~63에 할당하게 될 것이고, Warp #2, Warp #3은 Warp Scheduler에서 Pending 될 것이다.
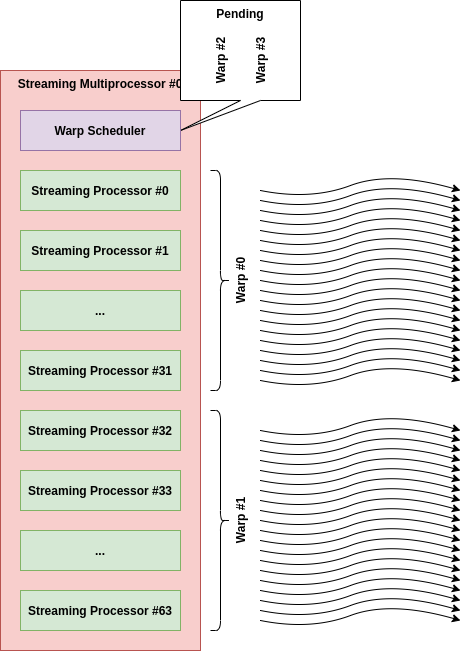
여기서 바로 이 Warp가 비로소 GPU Kernel의 최소수행단위가 되는데, 동일한 Warp 내의 모든 Thread들은 모두 동시에 수행되며 이 Warp 단위로 싱크가 맞음이 보장되게 된다.
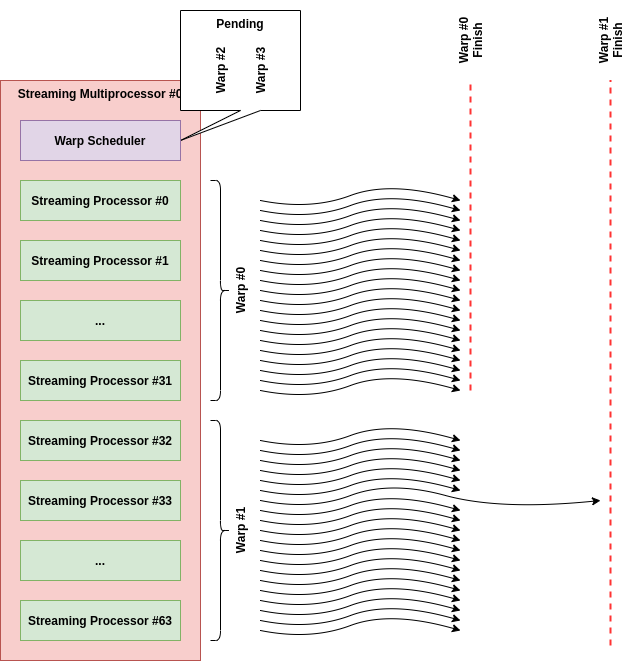
"싱크가 맞는다"라는 표현이 의미하는 바는 아래 그림과 같은데, 달리 표현하면 "한 Thread가 유난히 늦게 끝난다면, 동일한 Warp내의 다른 Thread들이 이를 기다려줍니다." 정도가 될 수 있다.
사실 Warp는 그 동작을 이해하는 것 보다 "대체 이딴 개념을 왜 도입했을까?"를 깨닫는게 훨씬 중요하다고 생각된다.
결론부터 이야기하면 Multiplexing을 통해서 최대한 SP를 놀지 못하게하기 위해서이다.
아마 독자들 중에 Intel 계열 CPU의 Hyper-Threading(학술적으로는 Simultaneous Multi-Threading이라고 불림)에 익숙한 사람들이 꽤나 있으리라 판단된다.
Hyper-Threading의 골자는 "IO/Memory 연산으로 인해 Thread가 Block될 때, 다른 Thread를 수행해서 Throughput을 올리자" 정도가 될 수 있다.
GPU Architecture의 Warp도 사실 이와 유사한 개념인데, 예를 들어 Warp #0의 Thread들이 Memory를 읽어야하는 연산을 만나서 SP가 그닥 할 일이 없는 상황이 발생했다고 가정해보자.
이럴 때 Warp Scheduler는 SP를 놀리지 않기 위해 Pending되어 있던 다른 Warp(필자의 예제에서는 Warp #2, Warp #3)를 Scheduling해서 SP에 할당해주게 된다.
이러한 Scheduling 과정에서 발생하는 Context Switch의 Overhead를 Zero에 가깝게 만들어 놓은 것이 NVIDIA GPU Archtecture의 핵심이라 할 수 있다.
3.6. 그래서 내 GPU는 정확히 어떻게 생긴건데?
아마 앞선 절들을 읽으면서 대부분의 독자들이 "아 성능을 올리려면 어떻게 Thread Hierarchy를 설계해야겠네!"라는 감을 잡았으리라 생각한다.
이제 남은 숙제는 각자가 보유한 GPU에 (1)SM이 몇개인지?, (2)SM 당 SP는 몇 개인지?, (3)Warp 크기는 몇인지?를 아는 것 정도가 될 수 있다.
이를 위하여 필자는 cuda-by-example을 참고하여 GPU Device를 쿼리하는 간단한 예제를 하나 작성하였다.
예제를 수행시키면 multiProcessorCount 출력과 warpSize 출력을 통해 (1)SM의 수, (3)Warp의 크기를 바로 확인할 수 있다.
조금 귀찮은 것은 (2)SP의 수가 바로 쿼리되지 않는 다는 점인데, 조금 조사해보니 현재 시점에서 NVIDIA는 이를 직접 쿼리할 수 있는 방법을 제공해주지 않고 있다.
아마도, 프로그래머가 SP의 갯수까지 알고 프로그래밍하는 건 그들의 철학과 맞지 않기 때문이 아닐까 추측이된다.
하지만, 본인의 아키텍처 이름을 가지고 구글링을 하면 얼마든지 찾아지는 정보이니 너무 낙담하지 말기 바란다.
{Arch} number of SP per SM으로 검색하면 앵간해서는 다 나온다.
또한, 쿼리 예제에는 이 포스팅에서 미처 설명하지 못한 여러 제약사항들을 확인할 수 있으니 꼭 한번 돌려보기를 권한다.
(예를 들어 Thread Block 당 최대 Thread 갯수, SM 당 최대 Thread 갯수 등)


선생님, 감사합니다. GPU 스펙을 쿼리해봤을 때, 하나의 SM이 가지는 SP가 64개인데 MP의 최대 쓰레드 처리량이 1024개인 것이 이해가 안됬었는데 워프 스케줄러 케파를 1024로 이해하면 되겠네요!