1. 집합 연산자, 그룹 함수, 윈도우 함수
(1) 집합 연산자의 개념과 종류
- 집합 연산자의 개념과 특징
- 집합 연산자
- 두 개 이상의 '테이블에 대한 쿼리 결과'를 하나로 결합하여 원하는 결과를 만드는 연산
- JOIN을 사용하지 않고 연관된 데이터를 조회할 수 있음
- 쿼리 결과의 열 개수와 데이터 타입이 같아야 함
- ORDER BY는 전체 결과에 대해 마지막에 한 번만 사용 가능
- 집합 연산자
- 주요 집합 연산자의 종류
| 종류 | 설명 |
|---|---|
| UNION | - 쿼리 결과의 합집합 (중복 제거) |
| UNION ALL | - 쿼리 결과의 합집합 (중복 허용) `SELECT * FROM user_t UNION ALL SELECT * from student_t;` |
| INTERSECT | - 쿼리 결과의 교집합 (중복 제거) |
| MINUS (또는 EXCEPT) | - 첫번째 쿼리 결과에서 두번째 쿼리 결과를 제외한 차집합 (중복 제거) `SELECT * FROM user_t MINUS SELECT * from student_t;` |
(2) 그룹 함수의 개념과 종류
- 그룹 함수의 개념과 특징
- 그룹 함수
- 테이블의 여러 행(Row)을 하나의 그룹으로 묶어 집계(Aggregation) 결과를 반환하는 함수
- 주로 GROUP BY 절과 함께 사용, 특정 기준으로 데이터를 그룹화 한 후 원하는 정보 추출
- GROUP BY 사용시 SELECT 절에는 그룹화 기준 컬럼과 집계 함수만 사용 가능
- HAVING 절을 사용하여 그룹화된 결과에 조건을 적용할 수 있음
- 그룹 함수
- 그룹 함수의 종류 (NULL과 중복 데이터 처리에 주의 필요)
- 집계 함수
COUNT(\*), COUNT(column), COUNT(DISTINCT column)- COUNT
- SUM
- AVG
- MAX
- MIN 등
- 총계 합수
- ROLLUP
- CUBE
- GROUPING SETS
- GROUPING 등
- 집계 함수
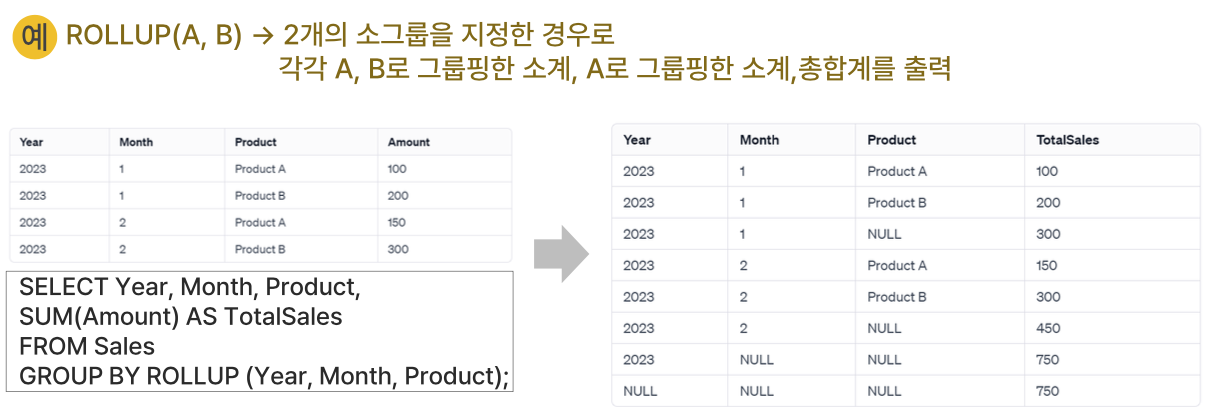
- 그룹 함수의 종류별 특징- ROLLUP
- GROUP BY로 묶인 컬럼의 소계(Subtotal)를계층적으로 계산
- GROUP BY 칼럼의 순서가 변경되면 결과도 변경
- Grouping Column의 개수가 N이면 N+1 Level의 소계가 생성됨
- 그룹 함수의 종류별 특징- CUBE
- 결합 가능한 모든 조합에 대한 다차원 집계 생성

- 그룹 함수의 종류별 특징- GROUPING SETS
- 특정 항목 (원하는 부분)의 소계를 계산, 인수의 순서가 바꾸어도 동일한 결과

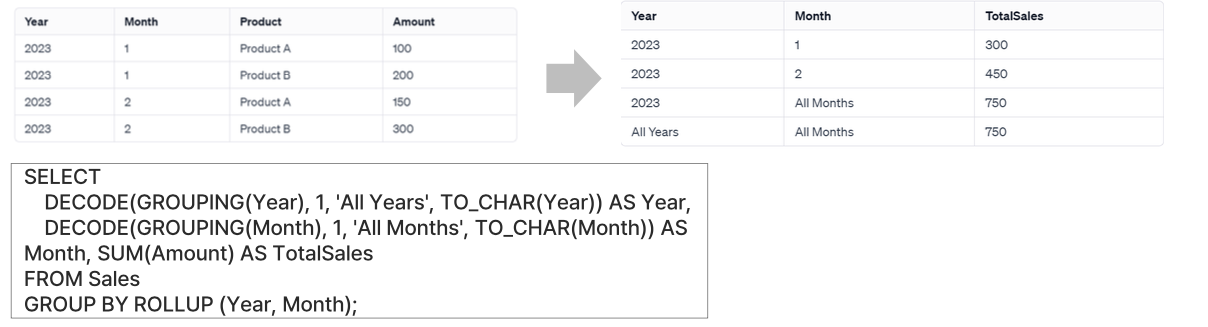
- 그룹 함수의 종류별 특징- GROUPING
- 소계 여부에 따라 1, 0 혹은 원하는 문자열을 표시할 수 있음
- 참고
- ROLLUP, CUBE, GROUPING SETS와 함께 쓰임
- 결과값에 따라 CASE 혹은 DECODE를 이용하여 표시할 문자열 선택
(3) 윈도우 함수의 개념과 종류
- 윈도우 함수 (Window Function)의 개념과 특징
- 윈도우 함수 (Window Function)
- 특정 범위(윈도우, Window) 내에서 각 행에 대해 연산을 수행하는 SQL 함수
- 그룹 함수와 다르게 전체 데이터를 그룹화하지 않고도 개별 행을 유지한 상태에서 계산할 수 있음
- OVER 절을 사용하여 윈도우의 범위와 계산 방식을 정의
- 특정 범위(윈도우, Window) 내에서 각 행에 대해 연산을 수행하는 SQL 함수
- 윈도우 함수의 종류
- 순위 함수: RANK, DENSE_RANK, ROW_NUMBER
- 집계 함수: SUM, MAX, MIN, AVG, COUNT
- 행 순서 함수: FIRST_VALUE, LAST_VALUE, LAG, LEAD
- 비율 함수: CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT
- 윈도우 함수의 종류별 특징- 순위 함수
- RANK
- 순위를 카운트, 중복 순위를 포함
- 즉, 중복된 수 만큼 증가한 후 그 다음 카운트 시작
- DENSE_RANK
- 순위를 카운트, 중복 순위를 무시
- ROW_NUMBER
- 동일한 값(순위)라도 고유한 순위를 부여
- RANK
- 윈도우 함수의 종류별 특징- 집계 함수
- SUM (합계)
- MAX (최대값)
- MIN (최소값)
- AVG (평균값)
- COUNT (건수)
- 윈도우 함수의 종류별 특징- 행 순서 함수
- FIRST_VALUE (가장 앞의 데이터)
- LAST_VALUE (가장 마지막의 데이터)
- LAG (특정 수 만큼 앞의 데이터)
- LEAD (특정 수 만큼 뒤의 데이터)
- 윈도우 함수의 종류별 특징- 비율 함수
- RATIO_TO_PERCENT: 파티션 합계에서 차지하는 비율 계산
- PERCENT_RANK: 현재 행의 백분위 수를 계산 (0 ~ 1을 구간으로 함)
- CUME_DIST: 누적 백분율을 계산 (0 ~ 1 사이의 값
- NTILE: 행들을 N 등분 후 현재 행의 등급을 계산
- 윈도우 함수 (Window Function)
2. TOP-N 쿼리, 계층 쿼리, SELF JOIN
(1) TOP-N 쿼리의 개념과 방식
- TOP-N 쿼리의 개념
- TOP-N 쿼리
- 테이블에서 상위 N 개의 행을 검색하는 쿼리
- TOP-N 쿼리의 실행 방식
- ROWNUM
- 오라클에서 사용하는 의사 컬럼
- ‘=‘ 조건은 사용할 수 없으며, < 혹은 <= 조건을 이용함
- FETCH FIRST N ROWS ONLY
- ANSI SQL에서 사용하는 구문
- ORDER BY 절과 함께 사용
- 계층 쿼리 (계층형 질의)
- 계층형 데이터를 조회하기 위해 사용
- 엔터티를 순환관계의 데이터 모델로 설계한 경우 발생 (예: 조직, 메뉴, 부품 등)
- START WITH … CONNECT BY 구문 사용
- 셀프 조인 (Self Join)
- 동일한 테이블 간 조인
- 한 테이블 내 컬럼간 연관 관계가 있을 경우에 사용, ALIAS(별칭) 사용 필수
- ROWNUM
- TOP-N 쿼리
# ROWNUM
SELECT column_name
FROM (
SELECT column_name
FROM table_name
ORDER BY column_name DESC
)
WHERE ROWNUM <= N;
# FETCH FIRST N ROWS ONLY
SELECT column_name
FROM table_name
ORDER BY column_name DESC
FETCH FIRST N ROWS ONLY;
# 계층 쿼리
SELECT employee_id, first_name, manager_id
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id
ORDER SIBLINGS BY first_name;
# 셀프 조인
SELECT e.employee_id, e.first_name AS Employee, m.first_name AS Manager
FROM employees e LEFT JOIN employees m ON e.manager_id = m.employee_id;3. PIVOT과 UNPIVOT
(1) PIVOT과 UNPIVOT의 특징
- PIVOT의 특징
- 행을 열로 변환하여 데이터를 요약하기 위해 사용
- UNPIVOT의 특징
- 열을 행으로 변환하여 데이터를 요약하기 위해 사용
(2) 정규 표현식의 특징
- 정규표현식
- 문자열의 특정 패턴을 기술하는 방법
SELECT phone_number,
CASE
WHEN REGEXP_LIKE
(phone_number, '^01[0-1|6-9]-?[0-9]{3,4}-?[0-9]{4}$’)
THEN '유효한 휴대폰 번호’
ELSE '유효하지 않은 휴대폰 번호’
END AS validation_result
FROM contacts;
🚀 내가 보려고 쓰는 기술블로그