서론
커뮤니티에서 한 분이 "왜 unbounded capacity가 좋은지 납득이 되지 않는다"라고 질문을 하신 적이 있습니다.
그리고는 만 개의 Task를 수행하는 테스트 결과를 첨부해주셨는데, 첫 번째 사진은 capacity가 1000일 때이며, 두 번째 사진은 기본 값(= unbounded capacity = Integer.MAX.VALUE)일 때였습니다.


첫 번째는 14127ms, 두 번재는 22ms로 상당한 차이가 발생한다는 것을 확인할 수 있습니다.
설정은 다음과 같은 상황이었습니다.
추측
총 두 분께서 다음과 같은 의견을 내주셨습니다.
1-1. 큐의 용량이 작을 경우, 대기열 오버플로우로 인해 새로운 작업의 추가가 거부되어 응답 시간이 증가하거나, 스레드의 빈번한 생성 및 종료로 인한 오버헤드가 발생하여 성능이 저하될 수 있습니다.
1-2. 스레드 수가 많을 경우, 컨텍스트 스위칭에 따른 오버헤드 증가, 자원 경합으로 인한 성능 저하, 데드락 발생 가능성 증가, 그리고 과도한 시스템 자원 사용으로 인한 응답속도 저하 등의 부작용이 발생할 수 있습니다.
2. 큐가 가득차면 새로운 풀을 만들어야 하기 때문에 느릴 수 있습니다.
첫 번째 답변에 대해 질문해주신 분께서 정리한 내용은 다음과 같습니다.
- unbounded queue를 사용 시, 빠른 이유
- corepoolSize가 넘어도 계속 스레드를 생성하면서 처리하는게 아닌 메모리에 올려두고 처리
- bounded queue를 사용 시, 느린 이유
- 비싼 쓰레드 생성 비용을 지불하여 많은 쓰레드를 생성 및 처리하기에, 시간이 오래 걸림
이 의견들이 상당히 애매하다고 느껴져서, 이를 정리하면서 학습하고자 합니다.
ThreadPoolTaskExecutor
ThreadPoolTaskExecutor는 스프링에서 제공하는, "corePoolSize", "maxPoolSize", "keepAliveSeconds", "queueCapacity"의 속성을 통해 커스터마이징이 가능한 스레드 풀 기반의 TaskExecutor 구현체입니다.
initialize()
ThreadPoolTaskExecutor.initialize()는 실질적으로 ExecutorConfigurationSupport.initialize()를 호출합니다.
해당 메서드는 내부적으로 ThreadPoolTaskExecutor.initializeExecutor()을 호출합니다.
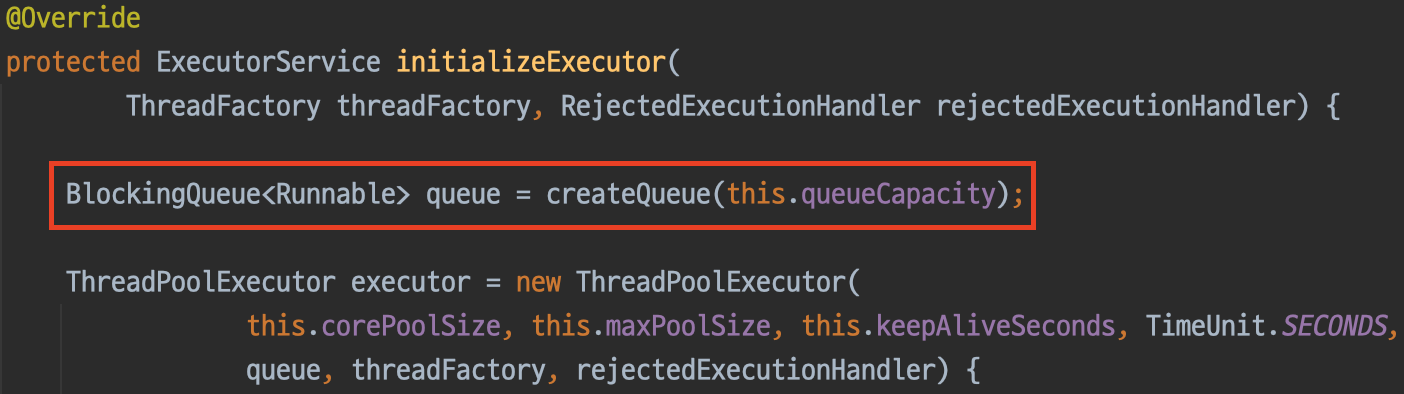

ThreadPoolTaskExecutor에서는 내부적으로 BlockingQueue를 생성할 때 queueCapacity가 0보다 크면 LinkedBlockingQueue를 사용하고, 아니라면 SynchronousQueue를 사용합니다.
queueCapacity가 0이라면 해당 스레드 풀은 큐를 단순히 Task를 전달하는 용도로 사용한다는 것을 의미하므로, 당연하다고 볼 수 있습니다.

기본 값은 Integer.MAX_VALUE로, 일반적인 스레드 풀이라면 LinkedBlockingQueue를 사용하는 것을 확인할 수 있습니다.
즉 unbounded queue나, bounded queue나 모두 동일한 큐를 사용하고 있음을 확인할 수 있습니다.
ThreadPoolExecutor

당연하지만 ThreadPoolTaskExecutor은 내부적으로 ThreadPoolExecutor를 구현해서 사용하고 있습니다.


그러므로 일반적인 ThreadPoolExecutor과 동일한 방식으로 생각하면 될 것 같습니다.
RejectedExecutionHandler

설정에서 RejectedExecutionHandler는 CallerRunsPolicy를 지정한 것을 확인할 수 있습니다.
이는 스레드 풀에 큐가 가득 찬 경우, 이 Task를 전달한 스레드에서 직접 해당 Task를 수행하는 정책입니다.
사실 지금 환경에서는 maxPoolSize가 기본 값이므로 Integer.MAX_VALUE이기 때문에, 해당 RejectedExecutionHandler가 동작할 일은 없습니다.
동작 방식

작성된 코드를 확인해보면 이유는 알 수 없지만, 별도로 corePoolSize를 지정하지 않은 상태입니다.

그러므로 queueCapacity를 제외한다면 모두 기본 값인 상황입니다.
공통

corePoolSize = 1이기 때문에 스레드 풀에는 기본적으로 하나의 스레드가 동작합니다.
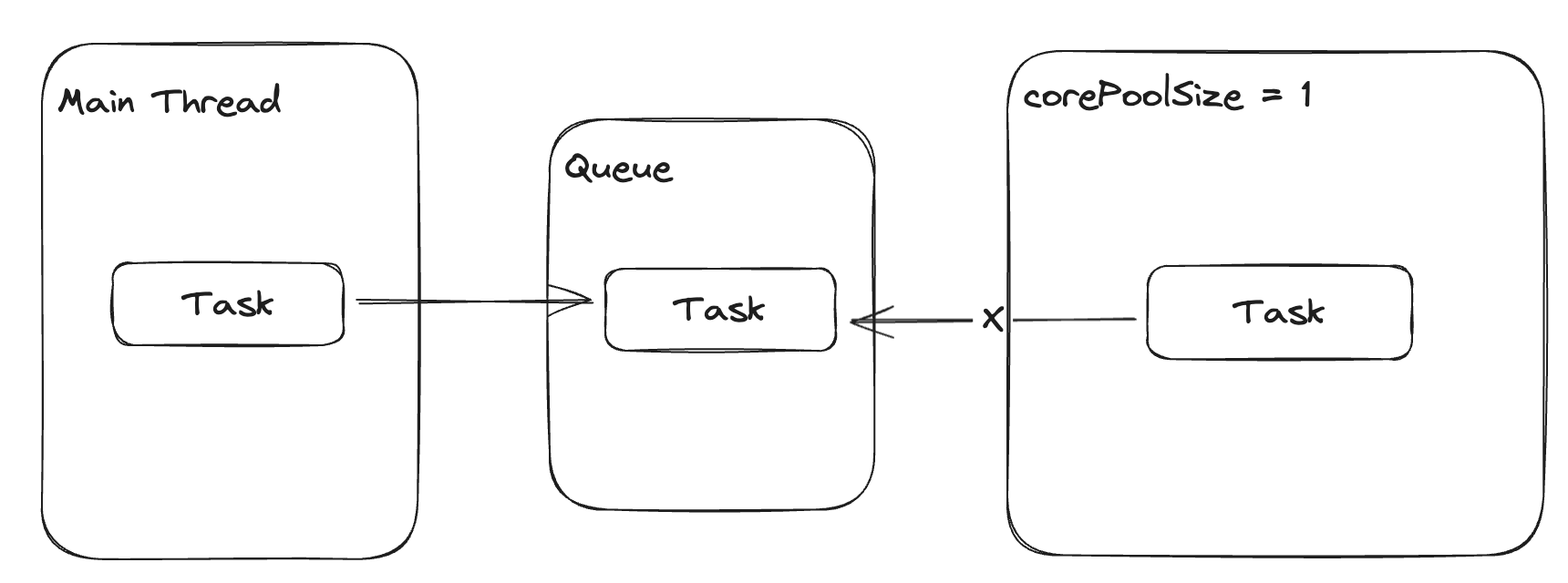
이 상태에서는 큐가 다 차기 전까지 스레드 풀은 큐에 저장된 Task를 조회할 수 없습니다.
Unbounded Queue
기본 값이기 때문에, Queue Capacity는 Integer.MAX_VALUE 입니다.

큐에는 크기 제한이 사실상 무한대이기 때문에, 스레드 풀에서 Task를 처리하는 동안 메인 스레드는 계속 큐에 Task를 전달합니다.
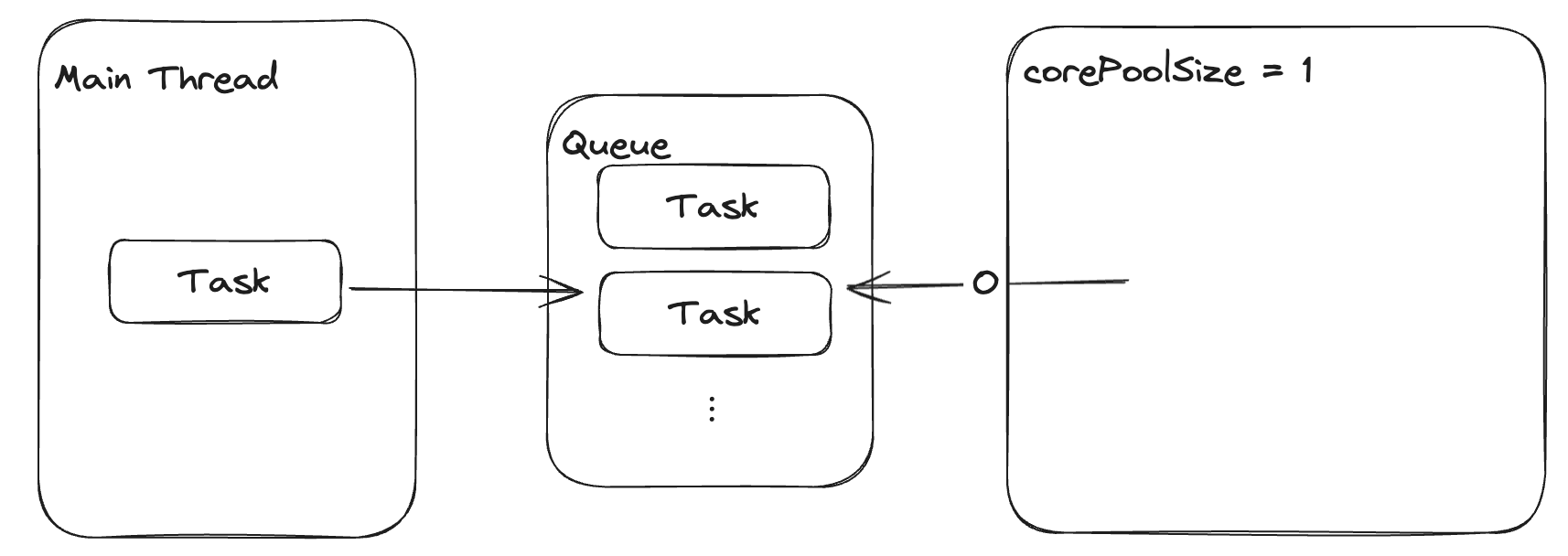
스레드 풀에서는 Task를 모두 수행한 이후, 큐에서 Task를 가져와서 다시 수행합니다.
Bounded Queue
예시에서는 Queue Capacity를 1000으로 준 상태입니다.
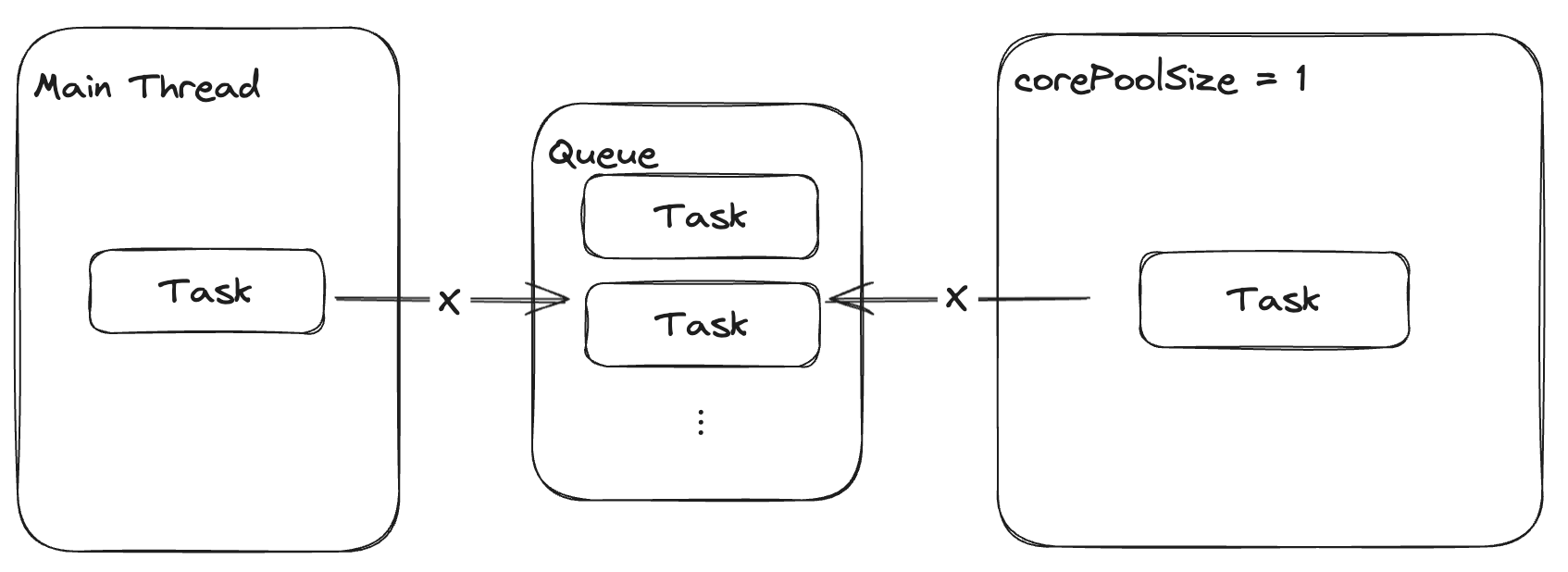
작업을 수행하다보면, 스레드 풀에서도 처리하고 있는 Task가 존재하면서 큐가 다 찬 경우가 발생하게 됩니다.

이런 상황에서 스레드 풀은 새로운 스레드를 생성합니다.

새로운 스레드가 큐에서 Task를 꺼내 수행합니다.

이후 큐의 공간이 비었으니, 메인 스레드가 다시 Task를 큐에 넣게 됩니다.
이렇게 추가한 스레드는 keepAliveSeconds 동안 아무 작업도 수행하지 않으면 삭제됩니다.
차이점
차이점은 큐가 가득차면서 스레드 풀에 새로운 스레드가 생성되는지 여부입니다.
Bounded Queue의 경우 크기가 1000으로, 테스트 시 주어지는 Task의 1/10이었습니다.
maximumPoolSize가 Integer.MAX_VALUE이므로 RejectedExecutionHandler 조차 동작하지 않아, 큐가 가득 찬 이후 스레드 풀에 계속 스레드가 생성됩니다.
Unbounded Queue일 때 작업이 22ms가 걸렸으므로 Task의 실행 시간은 이보다는 적겠지만, 전달해주신 사진을 봤을 때 JUnit 환경에서 만 개의 Task를 한 번에 전달하는 방식이라고 추측했습니다.
그렇다면 Task 처리 속도보다 메인 스레드가 큐에 Task를 전달하는 시간이 훨씬 빠를 것입니다.
이로 인해 일정 시점이 지난 후에는 스레드 풀에 스레드가 계속 생성되었을 것입니다.
테스트에 사용된 만 개의 Task와 Queue Capacity가 1000이었음을 고려하면 상당히 많은 스레드가 생성되었을 것 같습니다.
적어도 CPU 코어 개수보다는 많은 스레드가 생성되었을 것이기 때문에 컨텍스트 스위칭이 많이 발생할 것입니다.
이후 또 특정 시점이 지나면 수 많은 스레드들이 keepAliveSeconds 동안 아무 Task도 수행하지 못할 것이고, 종료시킬텐데 이 때에도 비용이 소모됩니다.
그렇기 때문에 결국 다음과 같이 정리할 수 있습니다.
- Unbounded Queue
- 스레드 풀에서 사용하는 큐의 용량이 무한이기 때문에 스레드 풀은 추가적으로 스레드를 생성하지 않고 corePoolSize 수만큼의 스레드만 사용
- Bounded Queue
- 스레드 풀에서 사용하는 큐의 용량이 주어지는 Task보다 현저히 작기 때문에 계속 스레드 생성
- 특정 시점 이후에 폭발적으로 늘어난 스레드로 인해 컨텍스트 스위치 발생
- 특정 시점 이후에 사용하지 않는 수 많은 스레드 종료
결론
이제 처음에 적은 답변을 하나씩 살펴보겠습니다.
1-1. 큐의 용량이 작을 경우, 대기열 오버플로우로 인해 새로운 작업의 추가가 거부되어 응답 시간이 증가하거나, 스레드의 빈번한 생성 및 종료로 인한 오버헤드가 발생하여 성능이 저하될 수 있습니다.
1-2. 스레드 수가 많을 경우, 컨텍스트 스위칭에 따른 오버헤드 증가, 자원 경합으로 인한 성능 저하, 데드락 발생 가능성 증가, 그리고 과도한 시스템 자원 사용으로 인한 응답속도 저하 등의 부작용이 발생할 수 있습니다.
2. 큐가 가득차면 새로운 풀을 만들어야 하기 때문에 느릴 수 있습니다.
1-1번의 경우 일반적으로 옳은 내용입니다.
다만 현재 ThreadPoolTaskExecutor의 설정은 maxPoolSize가 기본 값인 Integer.MAX_VALUE이기 때문에 새로운 작업의 추가가 거부된다기보다는 큐가 가득 찼을 때 지연된다는 것이 자연스럽다고 생각합니다.
1-2번 또한 옳은 내용입니다.
다만 테스트 할 때 사용한 Task에 대해 알 수 없다보니 경쟁 조건이 발생하는지, 데드락이 발생하는지는 알 수 없다고 생각합니다.
2번의 경우 틀린 내용입니다.
일단 풀이 의미하는 바가 큐인지, 아니면 스레드 풀 그 자체인지 알 수는 없지만 큐가 가득찰 경우 생성되는 것은 스레드 뿐입니다.
- unbounded queue를 사용 시, 빠른 이유
- corepoolSize가 넘어도 계속 스레드를 생성하면서 처리하는게 아닌 메모리에 올려두고 처리
- bounded queue를 사용 시, 느린 이유
- 비싼 쓰레드 생성 비용을 지불하여 많은 쓰레드를 생성 및 처리하기에, 시간이 오래 걸림
unbounded queue를 사용 시, 빠른 이유의 내용은 틀렸습니다.
CPU를 할당받은 스레드는 메모리 영역에서 동작하기 때문입니다.
그러므로 스레드가 메모리에 실행되는 것은 Unbounded Queue가 빠른 이유가 되지 않습니다.
Unbounded Queue가 빠른 이유는 스레드 생성 / 컨텍스트 스위칭 / 스레드 삭제에 드는 비용이 없기 때문입니다.
bounded queue를 사용 시, 느린 이유의 내용은 옳다고 생각합니다.
