서론
팀 프로젝트에서는 다음과 같은 쿼리가 존재합니다.

해당 쿼리는 bid - auction은 다대일 관계이며, 특정 auction과 관계 있는 bid 중 PK가 가장 큰 값(= 가장 최근에 업데이트된 bid)를 반환하는 쿼리입니다.
실행되는 쿼리는 다음과 같습니다.
SELECT b.*
FROM bid b
WHERE b.auction_id = 1
ORDER BY b.id DESC
LIMIT 1;여기서 다음과 같은 의문점이 들었습니다.
굳이 LIMIT를 사용해야 할까?
의문점
쿼리에서는 가장 최근에 업데이트된 bid를 찾아야 하므로 PK가 가장 큰 값을 찾고 있습니다.
그를 위해 ORDER BY를 활용해 PK의 역순으로 정렬한 뒤 LIMIT를 활용해 단 하나의 레코드만 조회하고 있습니다.

물론 ORDER BY와 LIMIT를 사용할 경우, 지정한 레코드 수를 찾으면 즉시 쿼리를 종료하는 최적화를 진행해줍니다.
하지만 PK의 최대 값을 찾는다면 JOIN을 활용해 처리할 수 있다고 생각해 한 번 테스트해보고자 합니다.
테스트 준비
bid 테이블은 다음과 같이 정의되어 있습니다.
쿼리에서 사용되는 auction_id는 외래 키입니다.
mysql> desc bid;
+--------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+----------------+
| price | int | YES | | NULL | |
| auction_id | bigint | YES | MUL | NULL | |
| bidder_id | bigint | YES | MUL | NULL | |
| created_time | datetime(6) | NO | | NULL | |
| id | bigint | NO | PRI | NULL | auto_increment |
+--------------+-------------+------+-----+---------+----------------+성능을 테스트하기 위해 다음과 같이 약 2백만 개의 데이터를 추가했습니다.
select count(*) from bid;
+----------+
| count(*) |
+----------+
| 2276625 |
+----------+이 때, auction_id가 1인 데이터는 약 10만 개를 추가했습니다.
쿼리 분석
기존 쿼리
explain SELECT b.*
FROM bid b
WHERE b.auction_id = 1
ORDER BY b.id DESC
LIMIT 1;
+----+-------------+-------+------------+------+----------------+----------------+---------+-------+--------+----------+---------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+----------------+---------+-------+--------+----------+---------------------+
| 1 | SIMPLE | b | NULL | ref | fk_bid_auction | fk_bid_auction | 9 | const | 211336 | 100.00 | Backward index scan |
+----+-------------+-------+------------+------+----------------+----------------+---------+-------+--------+----------+---------------------+WHERE절을 통해 필터링을 수행했으므로, 사용된 key(= index)는 fk_bid_auction 외래 키임을 확인할 수 있습니다.
type이 ref인 것을 통해 효율적인 쿼리인 것은 확인할 수 있습니다.
다만 ORDER BY 절을 통해 PK를 기준으로 내림차순 정렬했기 때문에 Extra가 Backward index scan임을 확인할 수 있습니다.
이는 descending index보다는 효율이 떨어지지만, descending index를 별도로 정의하더라도 논-클러스터링 인덱스가 되어 버리기 때문에 별도로 인덱스를 추가한다고 하더라도 옵티마이저가 이를 선택하지는 않습니다.

Non-Unique Key Lookup을 통해 WHERE 절을 인덱스(= 외래 키)로 수행한 뒤, ORDER 작업을 수행하고 있음을 확인할 수 있습니다.
이를 통해 쿼리 코스트가 약 3만 정도임을 확인할 수 있습니다.
개선 쿼리
ORDER BY 절을 통해 PK를 기준으로 내림차순 한 뒤, LIMIT를 통해 가장 첫 번째 요소를 조회한다는 것은 결국 가장 큰 PK를 조회하는 것과 같습니다.
즉, WHERE 절로 거른 PK의 최댓값을 조회하는 것이므로, 기존 쿼리를 JOIN과 MAX()를 통해 개선할 수 있다고 생각했습니다.
explain SELECT b.*
FROM bid b
JOIN (
SELECT MAX(id) as max_id
FROM bid
WHERE auction_id = 1
) join_bid
ON b.id = join_bid.max_id;
+----+-------------+------------+------------+--------+-------------------------+---------+---------+-------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-------------------------+---------+---------+-------+------+----------+------------------------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | PRIMARY | b | NULL | const | PRIMARY,idx_bid_id_desc | PRIMARY | 8 | const | 1 | 100.00 | NULL |
| 2 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+------------+------------+--------+-------------------------+---------+---------+-------+------+----------+------------------------------+JOIN 내부의 서브 쿼리는 WHERE 절로 필터링 이후 바로 MAX()를 사용할 수 있으므로 Select tables optimized away로 최적화가 가능합니다.
드라이빙 테이블과 드리븐 테이블(= 서브 쿼리)끼리 값을 비교해야 하기 때문에 <derived2>이라는 이름의 임시 테이블이 생성되었습니다.
서브 쿼리의 결과는 단 하나의 레코드이기 때문에 type은 system인 것을 확인할 수 있습니다.
마지막으로 드라이빙 테이블에 JOIN을 수행합니다.
서브 쿼리의 결과는 하나의 레코드였고, PK를 기준으로 세팅하기 때문에 type이 const임을 확인할 수 있습니다.

왼쪽의 JOIN 절에 사용된 서브 쿼리의 경우 Select tables optimized away로 단 하나의 레코드만 조회했기 때문에 system constant임을 확인할 수 있습니다.
오른 쪽의 드라이빙 테이블의 경우 PK 기준으로 WHERE 절에 동등 비교를 수행하므로 constant임을 확인할 수 있습니다.
두 개의 결과 모두 레코드가 단일이기 때문에 nested loop에서 단 한 번만 반복됩니다.
이를 통해 쿼리 코스트가 1인 것을 확인할 수 있습니다.
쿼리 실행 시간
쿼리 실행 계획을 통해 LIMIT를 사용하는 개선 전 코드보다는 JOIN 절과 서브 쿼리를 활용한 방식이 더 효율적인 것을 확인할 수 있었습니다.
그럼 실제 쿼리 실행 시간도 다이나믹하게 차이가 발생할까요?
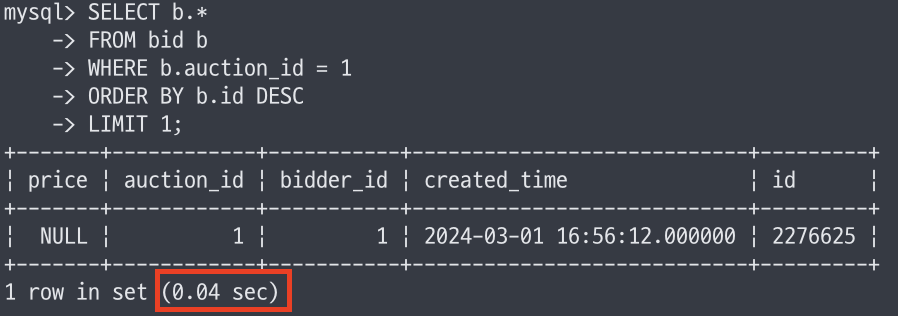

코스트는 이전 쿼리와 개선한 쿼리 각각 30028, 1이었지만 실행 결과는 매우 미세한 것을 확인할 수 있습니다.
더미 데이터가 약 2백만 개인 상황에서 이 정도 차이지만, 그래도 수치상으로 보면 25%를 개선한 것이기 때문에
결론
쿼리 변경
SELECT b.*
FROM bid b
JOIN (
SELECT MAX(id) as max_id
FROM bid
WHERE auction_id = 1
) join_bid
ON b.id = join_bid.max_id;다음과 같이 JOIN 절과 서브 쿼리를 활용하도록 쿼리를 변경했습니다.
학습 내용
- 쿼리 실행 계획을 통해서 파악하는 코스트는 쿼리를 실행하는데 필요한 비용을 추측한 것이기 때문에, 오차가 발생할 수 있습니다.
- LIMIT와 ORDER BY 절을 함께 사용하는 경우, MySQL 옵티마이저가 최적화를 수행합니다.
- 경우에 따라 ORDER BY 절을 JOIN 절로 최적화할 수 있습니다.
