서론
해당 글은 일프로 님의 인프런 강의 쿠버네티스 어나더 클래스 (지상편) - Sprint 1, 2의 내용을 정리한 글입니다.
해당 글에 사용된 내용, 사진 및 그림은 모두 강의와 강의 자료에 포함된 내용입니다.
PV/PVC (local, hostPath)
- 용도
- 파드가 여러 이유로 인해 종료될 경우에 대비해 보존해야 할 데이터를 관리하기 위함
- PV/PVC를 활용해 파드가 죽어 컨테이너가 종료된다고 하더라도, 쿠버네티스가 재생성한 파드를 다시 PV/PVC와 연결해 데이터 조회 가능
- 의미
- 파드와 볼륨의 결합도를 낮추기 위함
- 파드는 개발자가 관리하며, PV는 인프라 담당자가 관리하기 때문
- 파드-PV 중간에 PVC가 있는 이유는 PV 관련 다양한 솔루션에 종속되지 않도록 인터페이스 역할을 수행하기 위함
- 파드와 볼륨의 결합도를 낮추기 위함
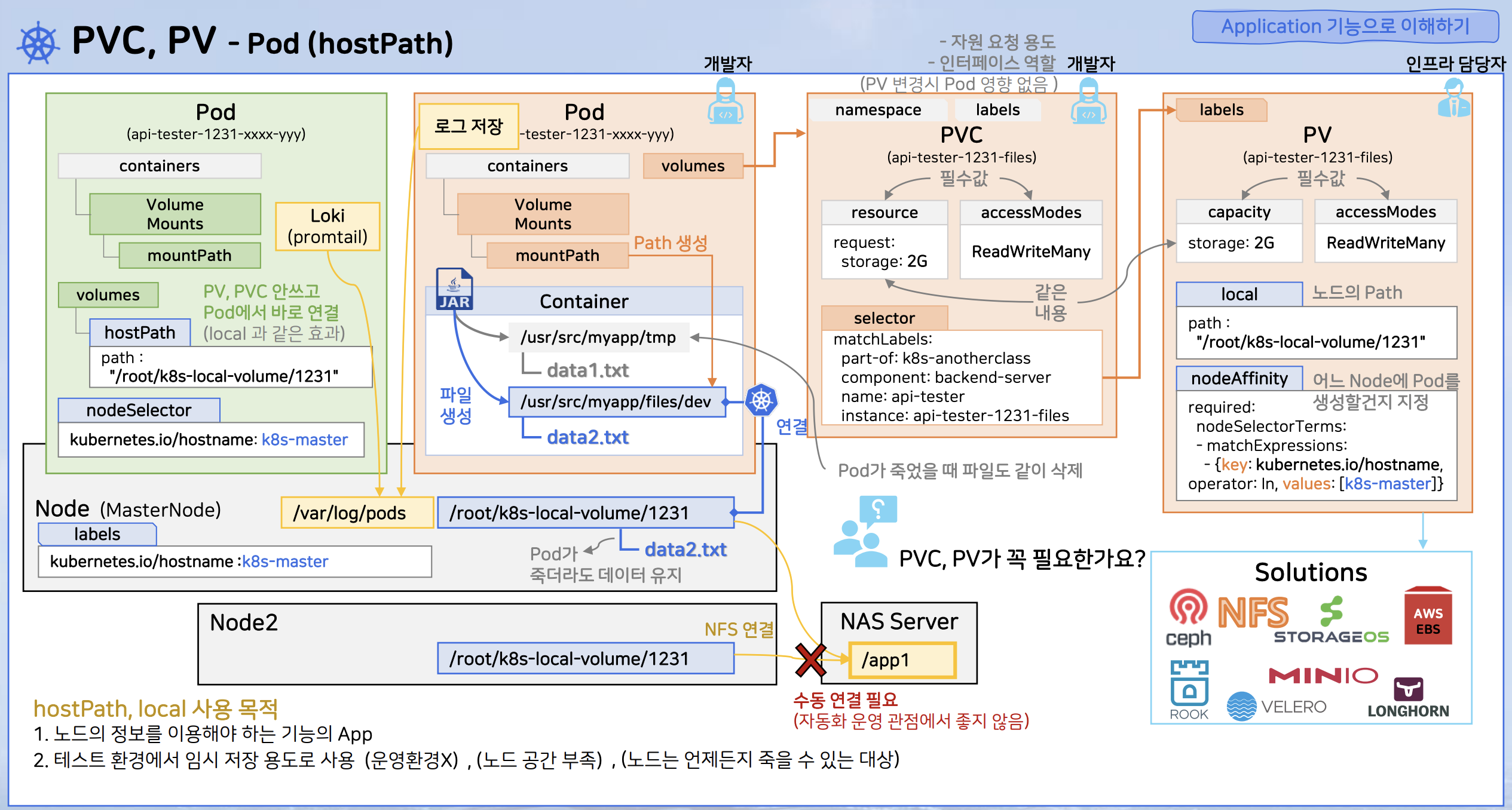
local, hostPath
- local
- PV(Persistent Volume)이 노드에 마운트된 로컬 스토리지 디바이스
- nodeAffinity를 통해 어떤 노드에 파드를 생성(스케줄링)할지 지정
- nodeAffinity 속성이 있는 PV와 연결된 파드는 그림에서 Master Node에 생성
- Master Node의 path와 파드 내의컨테이너 디렉토리를 매핑
- hostPath
- 노드의 파일시스템에 있는 파일이나 디렉터리를 파드에 마운트
- 노드에 있는 정보를 애플리케이션에서 조회하는 용도로 사용
- Promtail이 Loki가 수집하는 로그를 hostPath를 활용해 특정 디렉토리에 저장하기 때문에 모든 파드의 로그를 Loki를 통해 확인 가능
- 사용의 편리함으로 인해 테스트 환경에서 임시 저장 용도로도 사용되기는 함
- 노드 공간이 부족해질 수 있기 때문에 운영환경에서는 사용 금지
- 우회 방법이 있기는 하지만(그림에서는 NAS 서버를 활용) 자동화가 힘들기 때문에 지양할 것
- 노드에 있는 정보를 애플리케이션에서 조회하는 용도로 사용
- PV/PVC local 속성과 유사한 기능을 제공하나, 더욱 간단하게 사용 가능
- 쿠버네티스 공식 문서에서 사용하지 않는걸 권장하고 있음
- 노드의 파일시스템에 있는 파일이나 디렉터리를 파드에 마운트
실습
- 실습 순서
- 파일 생성 API 호출
- 생성된 파일 확인
- 파드 삭제
- 기존 생성된 파일 다시 확인
local
# 1. 파일 생성 API 호출
http://192.168.56.30:31231/create-file-pod
http://192.168.56.30:31231/create-file-pv
# 2. 생성된 파일 확인
## 컨테이너 내 임시 저장 파일
kubectl exec -n anotherclass-123 -it api-tester-1231-75dd57f8cb-x5rdl -- ls /usr/src/myapp/tmp
## 마운트된 컨테이너 내 영구 저장 파일
kubectl exec -n anotherclass-123 -it api-tester-1231-75dd57f8cb-x5rdl -- ls /usr/src/myapp/files/dev
## 컨테이너와 마운트된 노드 파일
ls /root/k8s-local-volume/1231
# 3. 파드 삭제
kubectl delete -n anotherclass-123 pod api-tester-1231-75dd57f8cb-hg54z
# 4. 기존 생성된 파일 다시 확인
http://192.168.56.30:31231/list-file-pod
http://192.168.56.30:31231/list-file-pv

- 파일 생성

- 파일 확인

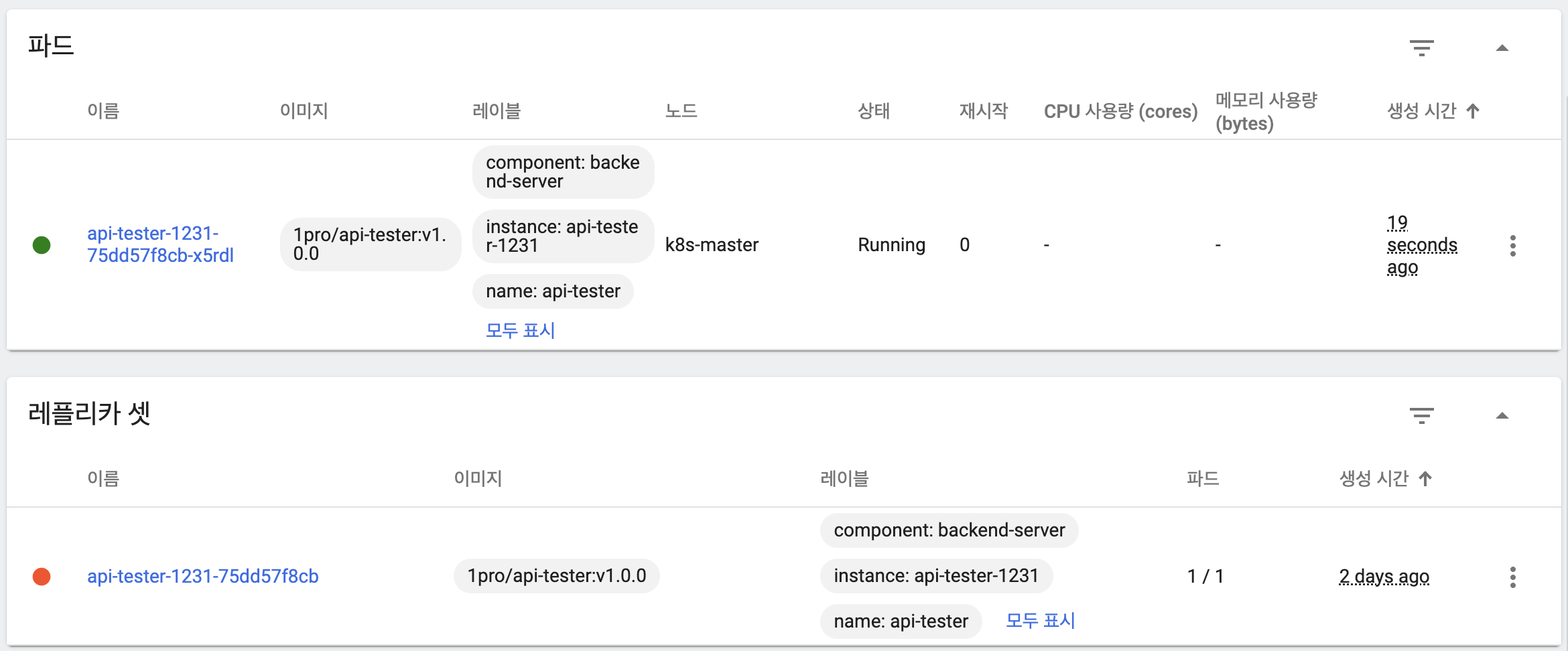
- 파드 삭제 후 쿠버네티스 내부적으로 재생성



- 임시 저장 파일은 삭제되었고 영구 저장 파일은 파드 삭제 후 재생성 시에도 파드 & 노드 양쪽에서 확인할 수 있음
hostPath
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: anotherclass-123
name: api-tester-1231
spec:
template:
spec:
nodeSelector:
kubernetes.io/hostname: k8s-master
containers:
- name: api-tester-1231
volumeMounts:
- name: files
mountPath: /usr/src/myapp/files/dev
- name: secret-datasource
mountPath: /usr/src/myapp/datasource
volumes:
- name: files
hostPath:
path: /root/k8s-local-volume/1231
- name: secret-datasource
secret:
secretName: api-tester-1231-postgresql- Deployment에서 파드 정의 사항 변경
# 1. 파일 생성 API 호출
http://192.168.56.30:31231/create-file-pod
http://192.168.56.30:31231/create-file-pv
# 2. 생성된 파일 확인
## 컨테이너 내 임시 저장 파일
kubectl exec -n anotherclass-123 -it api-tester-1231-5f488b45b4-wh6dt -- ls /usr/src/myapp/tmp
## 마운트된 컨테이너 내 영구 저장 파일
kubectl exec -n anotherclass-123 -it api-tester-1231-5f488b45b4-wh6dt -- ls /usr/src/myapp/files/dev
## 컨테이너와 마운트된 노드 파일
ls /root/k8s-local-volume/1231
# 3. 파드 삭제
kubectl delete -n anotherclass-123 pod api-tester-1231-5f488b45b4-85czr
# 4. 기존 생성된 파일 다시 확인
http://192.168.56.30:31231/list-file-pod
http://192.168.56.30:31231/list-file-pv

- 파일 생성

- 파일 확인


- 파드 삭제 후 쿠버네티스 내부적으로 재생성



- 임시 저장 파일은 삭제되었고 영구 저장 파일은 파드 삭제 후 재생성 시에도 파드 & 노드 양쪽에서 확인할 수 있음
Deployment

strategy
- strategy
- 파드 업데이트 시 사용되는 전략
- 타입
- Recreate
- RollingUpdate
- template
- 해당 속성에 포함된 모든 하위 속성에 변경이 발생하면 업데이트
- 동작 방식
- label, 버전 마이그레이션 등이 변경되면 파드 업데이트
1-1. 변경된 template 기반의 새로운 ReplicaSet 생성 - ReplicaSet에서 지정된 개수만큼 파드 생성
- 새로운 버전의 ReplicaSet이 파드를 생성했다면 이전 버전의 파드 삭제
3-1. 이전 버전의 ReplicaSet은 롤백에 사용
- label, 버전 마이그레이션 등이 변경되면 파드 업데이트
- Recreate
- 기존 파드를 삭제시킴과 동시에 새로운 ReplicaSet이 파드를 모두 생성
- 처리되는 속도에 따라 기동 시간이 달라짐
- 기동되기 전까지 트래픽을 감당할 수 없으므로 서비스 중단
- RollingUpdate
- 새 버전의 파드 생성
- 기동이 완료되면 이전 버전 파드 삭제
- 반복
- 업데이트 중 서비스 중단이 발생하지 않음
- 대신 업데이트 중 자원 사용량이 150%으로 증가
- 업데이트 중 두 버전이 동시에 호출될 수 있음
- 블루/그린 방식을 통해 해결할 수 있지만 별도 배포 솔루션이 필요하며, 자원 사용량이 200%으로 증가
- RollingUpdate 속성
- maxUnavailable
- 업데이트 동안 최대 몇 개의 파드를 서비스 상태로 유지할 지에 대한 비율
- 비활성화한 파드의 비율
- 업데이트 동안 최대 몇 개의 파드를 서비스 상태로 유지할 지에 대한 비율
- maxSurge
- 새 버전의 파드를 최대 몇 개까지 동시에 만들지에 대한 비율
- 예시
- maxUnavailable: 100%, maxSurge: 100%
- maxUnavailable로 인해 이전 버전의 모든 파드 중단
- maxSurge로 인해 새 버전의 파드를 replicas 만큼 즉시 생성
- Recreate와 동일한 효과
- maxUnavailable: 0%, maxSurge: 100%
- maxSurge로 인해 새 버전의 파드를 replicas 만큼 즉시 생성
- maxUnavailable로 인해 업데이트 도중 기동 중인 파드를 replicas 만큼 유지
- 애플리케이션마다 기동 시간이 다르므로 새 버전의 파드가 정상적으로 기동하면 이전의 파드 삭제
- 업데이트 도중에도 파드 개수를 replicas를 유지하겠다는 의미
- 자원을 200% 사용하지만 업데이트 시간 단축 및 Blue/Green에 가까운 효과가 발생
- maxUnavailable: 25%, maxSurge: 25%, 이전 버전 파드가 5개 있을 때
- 새 버전으로 업데이트 하기 위해서 25%의 제한에 맞춰 파드 1개 삭제
- 이는 서비스를 제공할 수 있는 파드가 5개에서 4개로 줄어든 것을 의미
- 정상 상태일때보다 트래픽 처리량이 줄어듦
- 이러한 파드의 수가 커지면 커질수록 극대화
- maxUnavailable: 100%, maxSurge: 100%
- maxUnavailable
실습
RollingUpdate 동작 & 롤백 확인
# 1) HPA minReplica 2로 바꾸기 (이전 강의에서 minReplicas를 1로 바꿔놨었음)
kubectl patch -n anotherclass-123 hpa api-tester-1231-default -p '{"spec":{"minReplicas":2}}'
# 1) 그외 Deployment scale 명령
kubectl scale -n anotherclass-123 deployment api-tester-1231 --replicas=2
# 2) 지속적으로 Version호출 하기 (업데이트 동안 리턴값 관찰)
while true; do curl http://192.168.56.30:31231/version; sleep 2; echo ''; done;
# 3) 별도의 원격 콘솔창을 열어서 업데이트 실행
kubectl set image -n anotherclass-123 deployment/api-tester-1231 api-tester-1231=1pro/api-tester:v2.0.0
# 4) 이미지 롤백
kubectl rollout undo -n anotherclass-123 deployment/api-tester-1231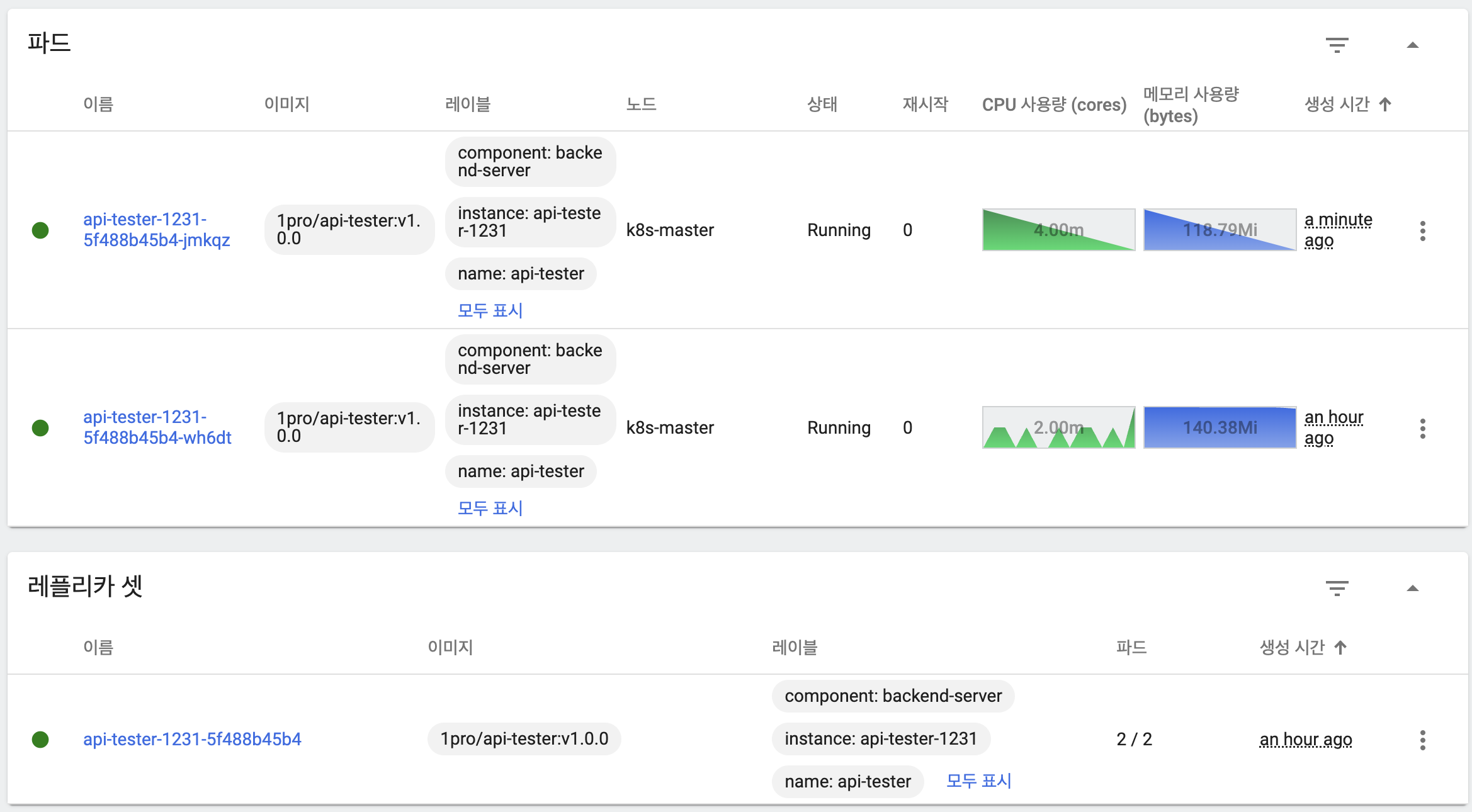
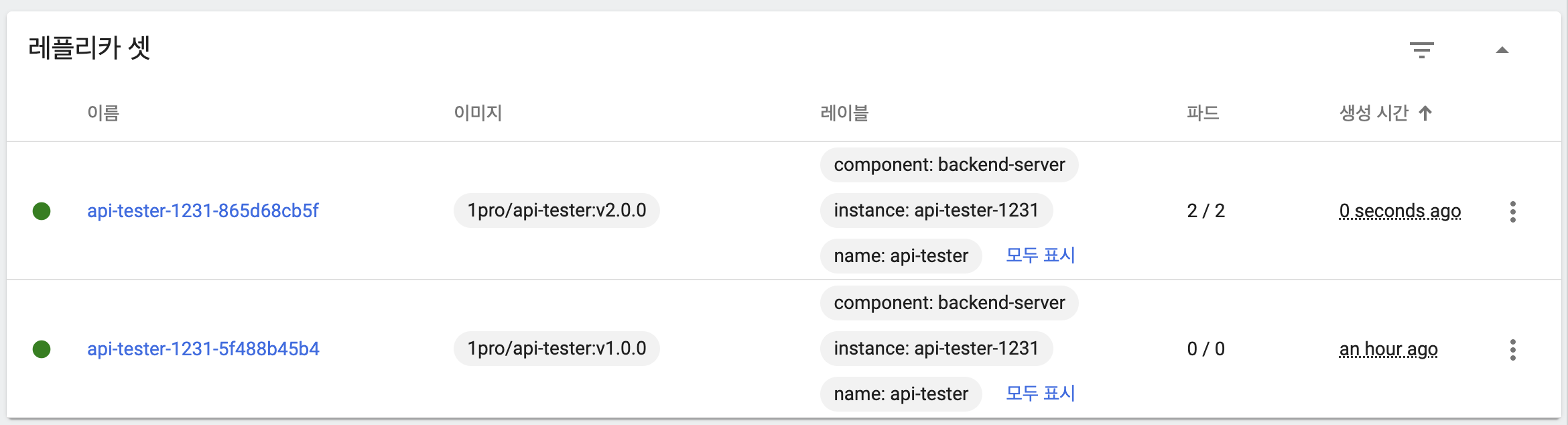
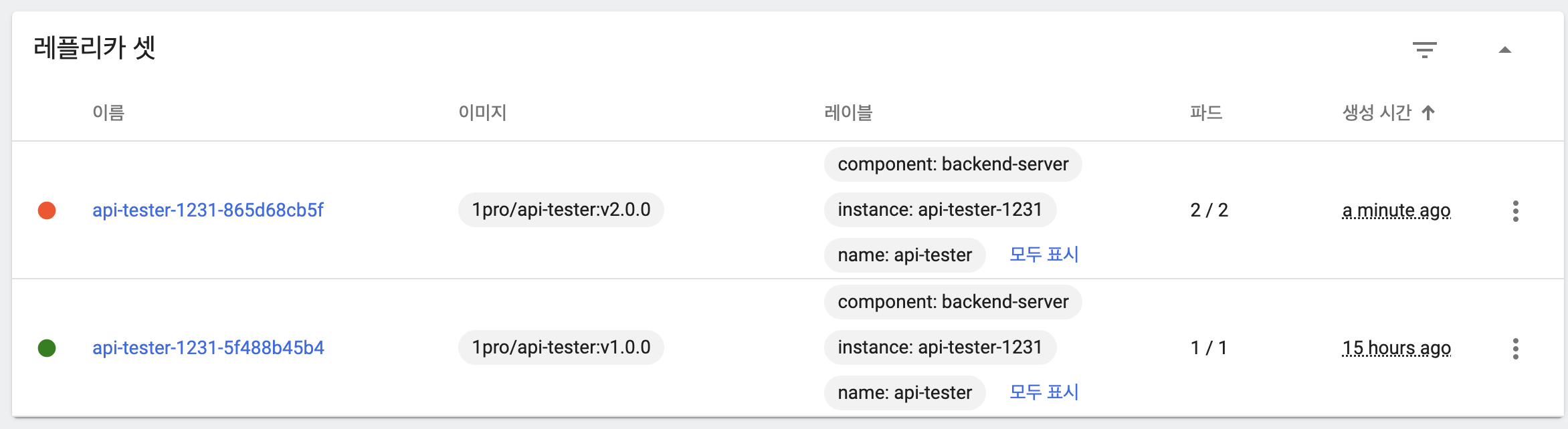
- 기존 파드, ReplicaSet 상태
- maxUnavailable: 25%, maxSurge: 25%
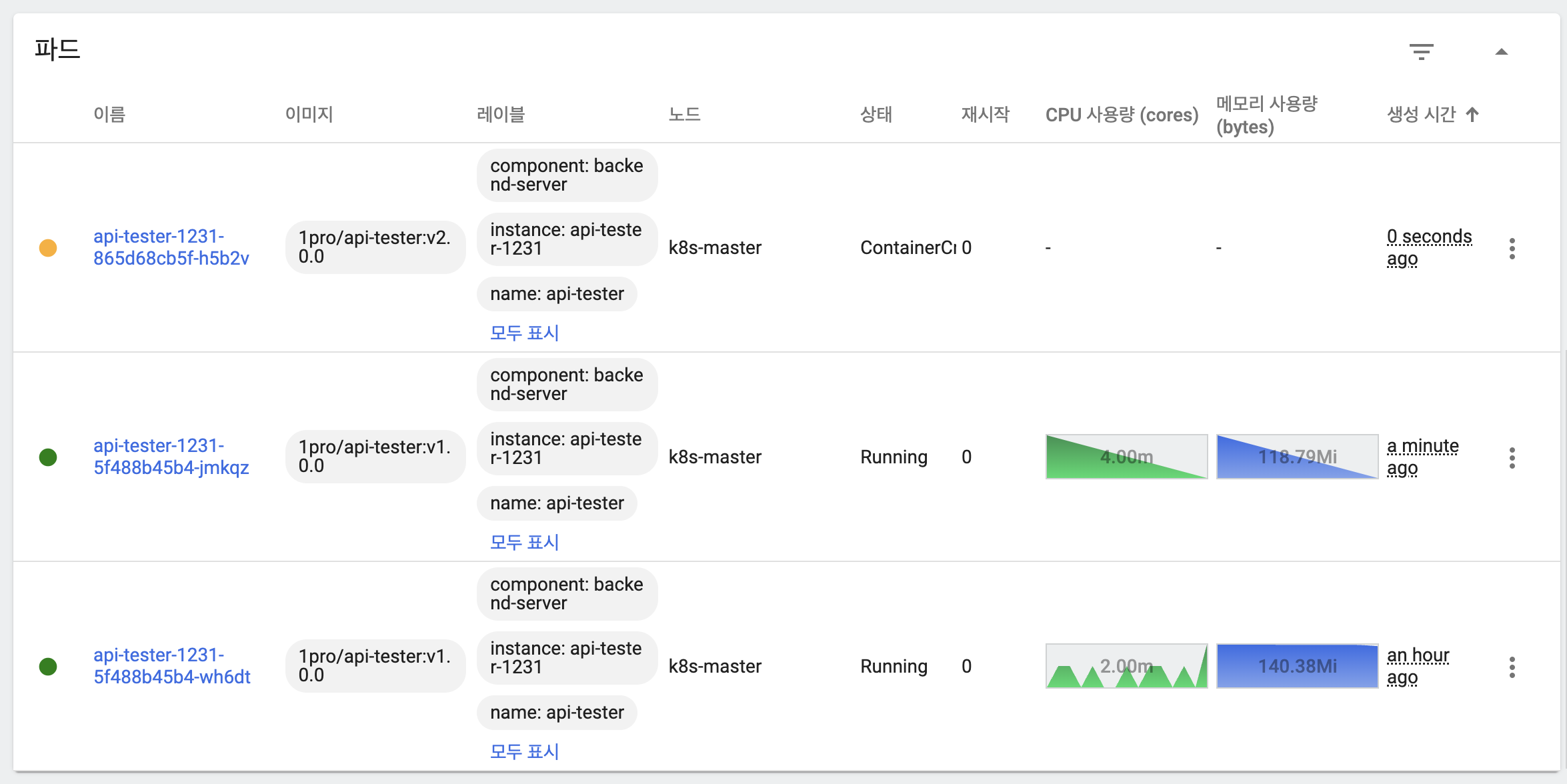
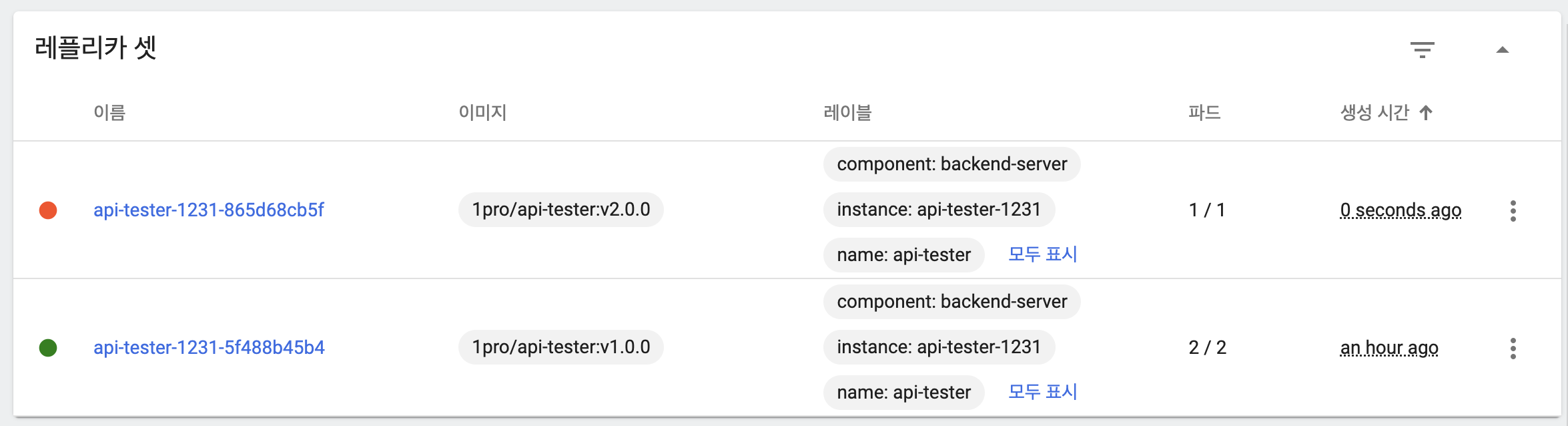
- 이미지 업데이트 시 maxSurge에 의해 새 버전의 파드 하나 생성
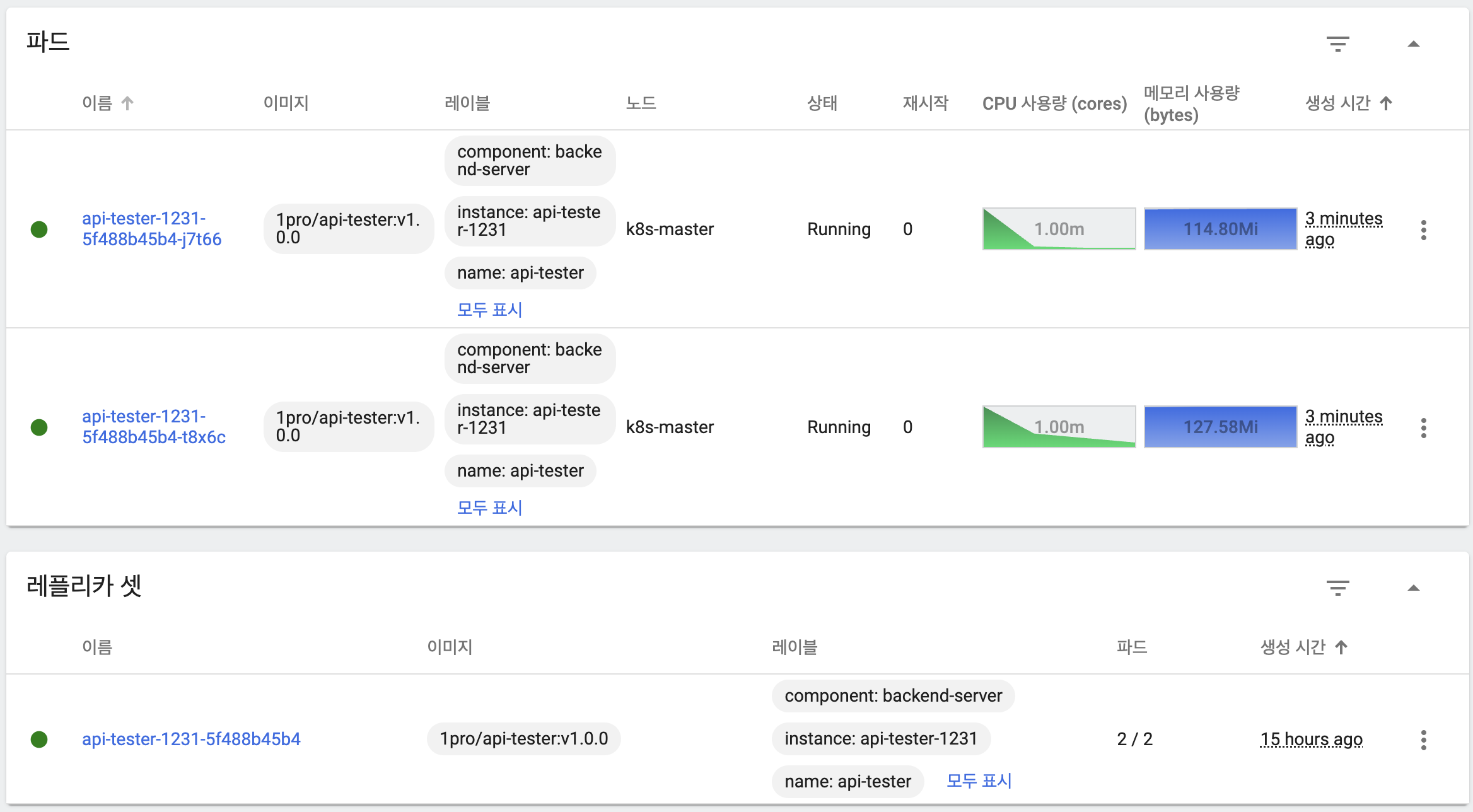
- 새 버전의 파드는 아직 기동되지 않은 상태
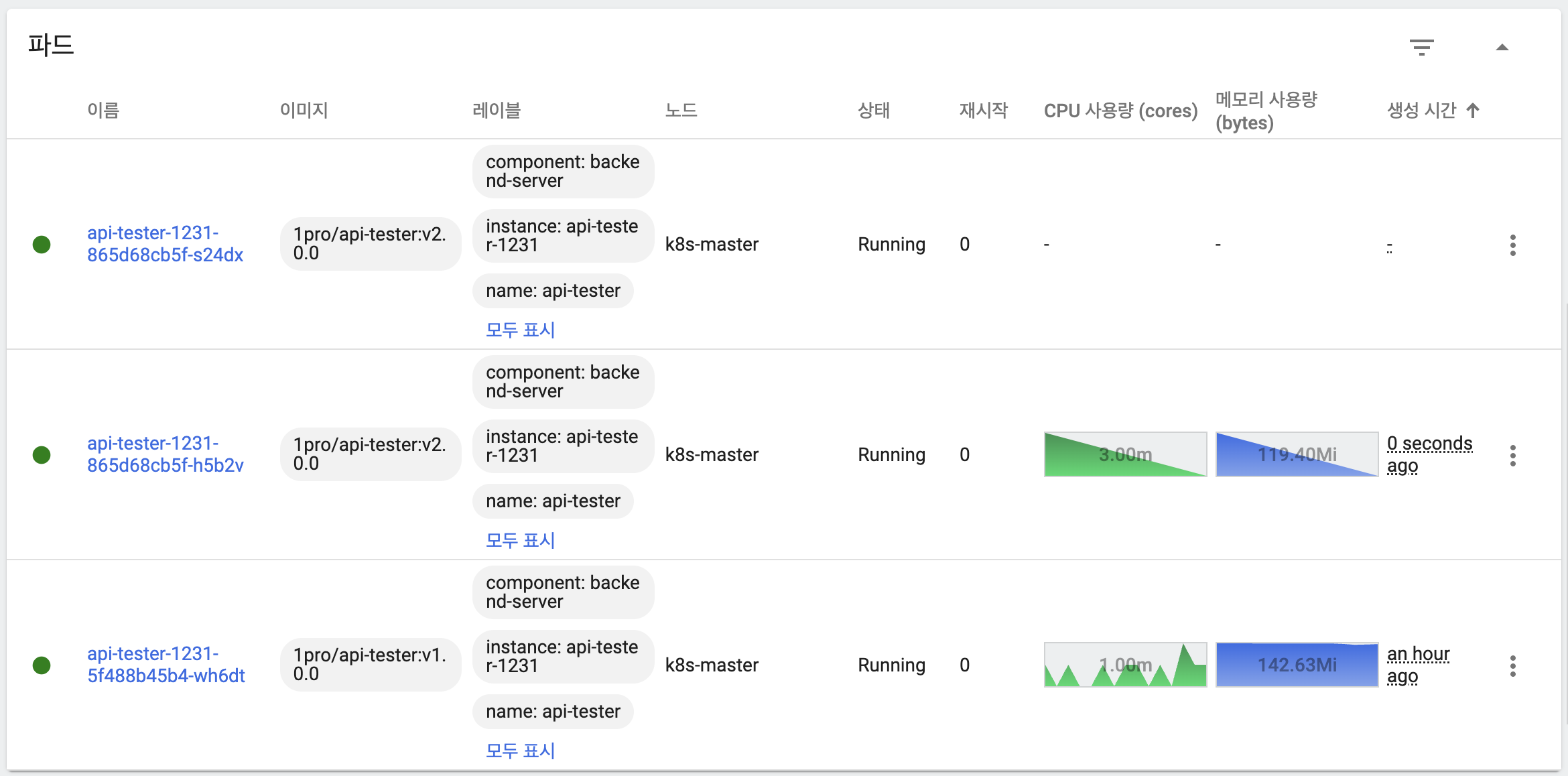

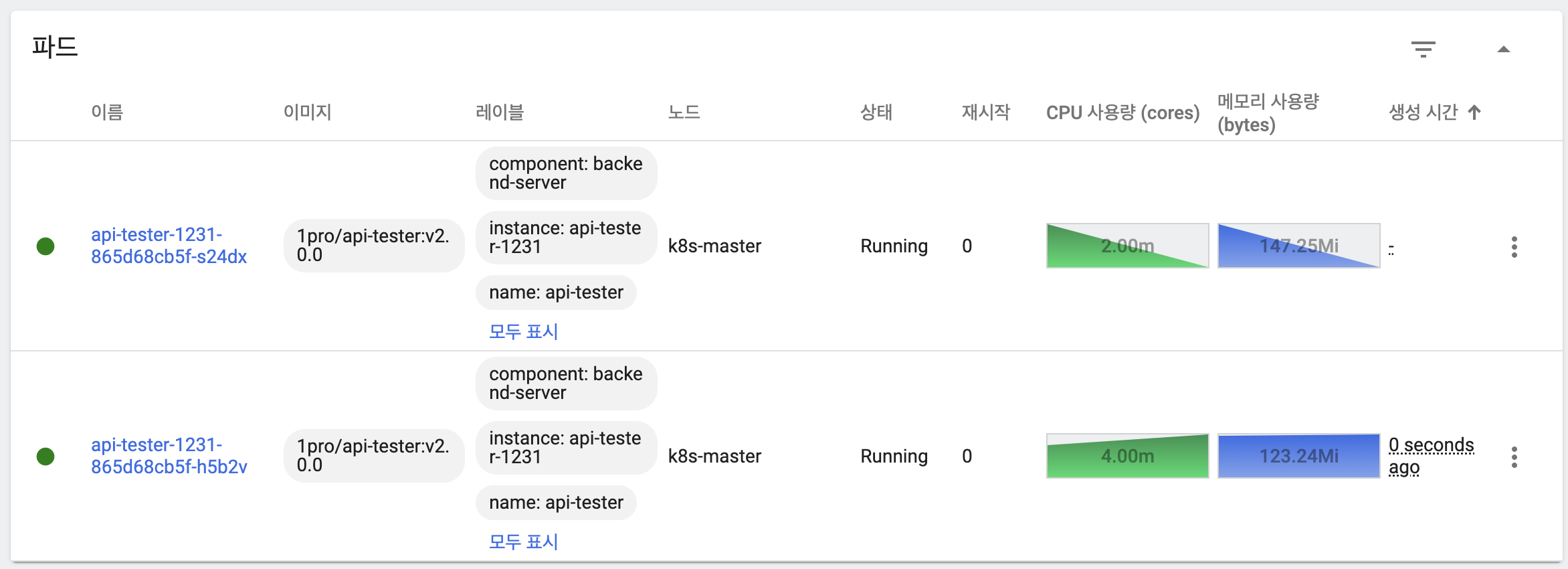
- 새 버전의 파드 하나가 기동
- 새 버전 파드 하나 추가 생성
- 이전 버전 파드 하나 삭제
- 응답을 통해 트래픽을 이전 버전과 새 버전 파드 모두가 처리하고 있음을 확인
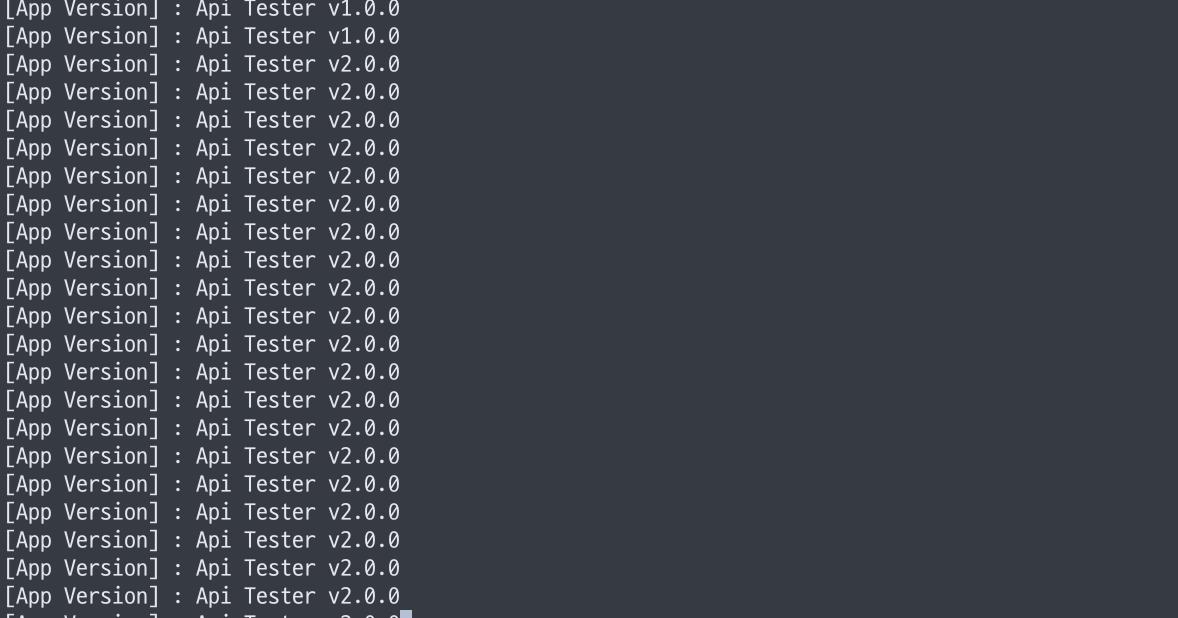
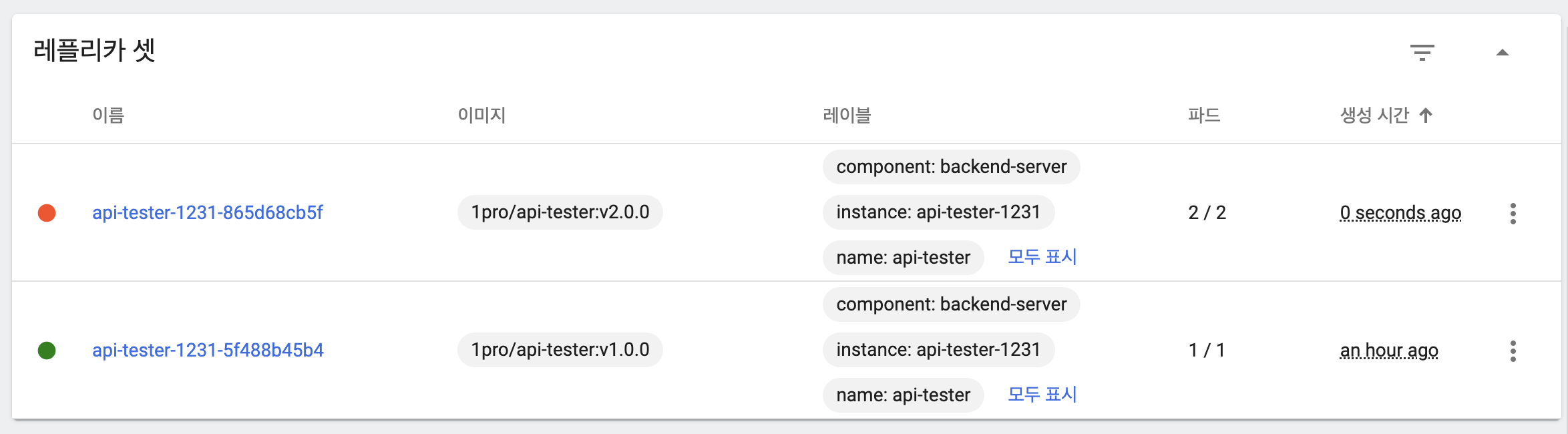
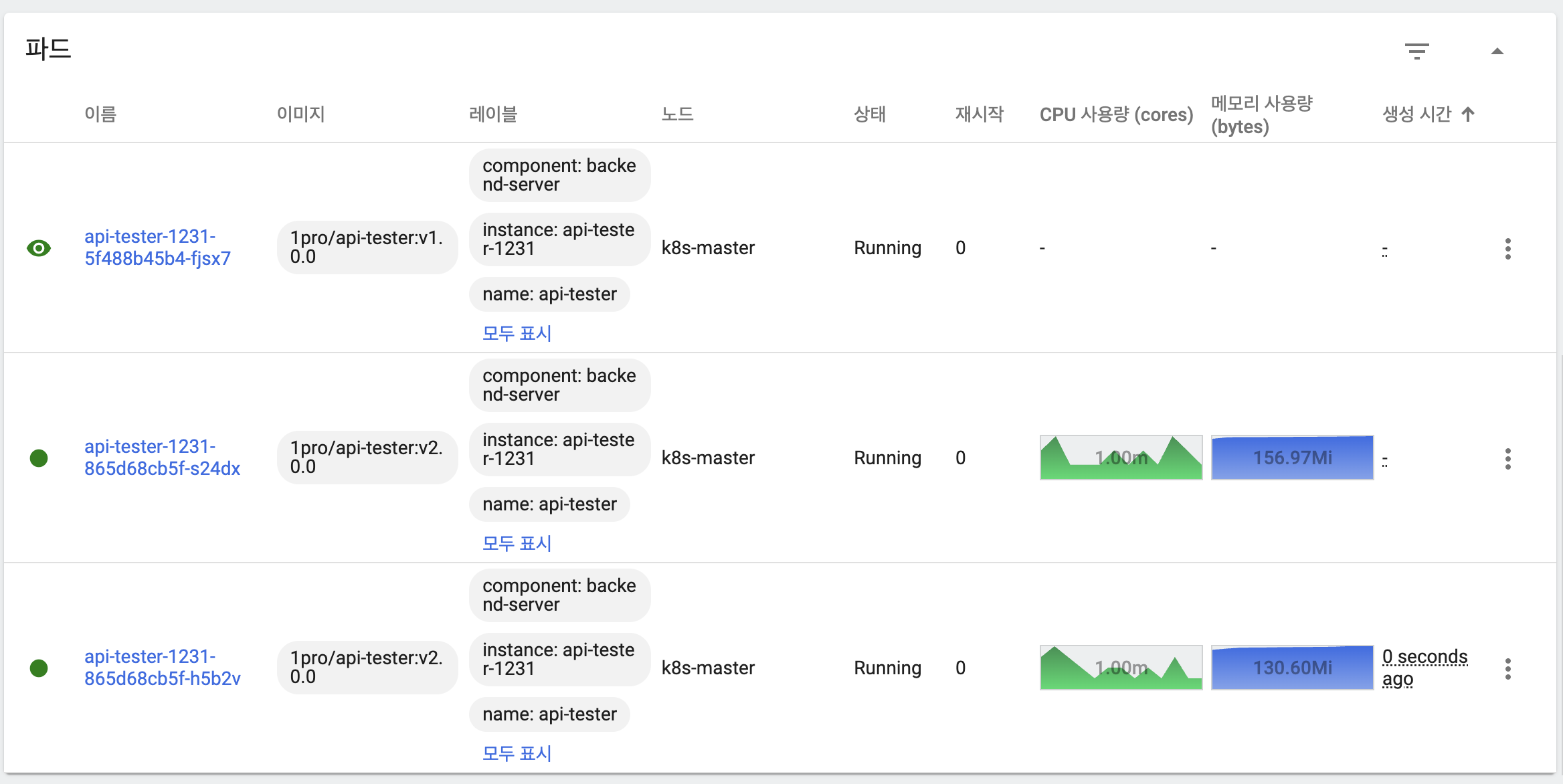
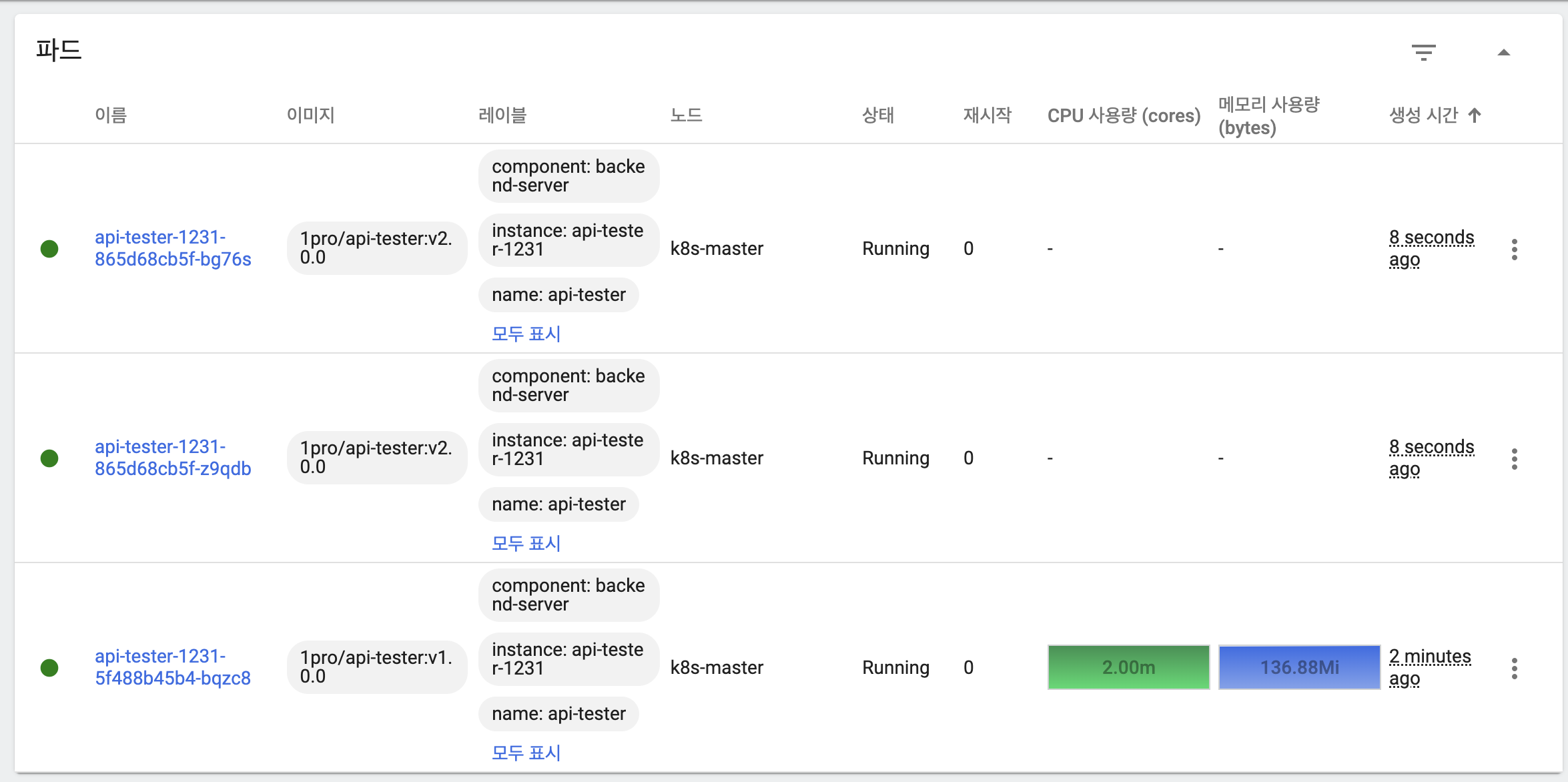
- 새 버전의 파드가 replicas 수만큼 생성되고 기동
- 이전 버전 파드 모두 삭제
- 롤백을 위해 이전 버전 replicaSet은 유지
- 응답을 통해 트래픽이 모두 새 버전 파드가 처리하고 있음을 확인
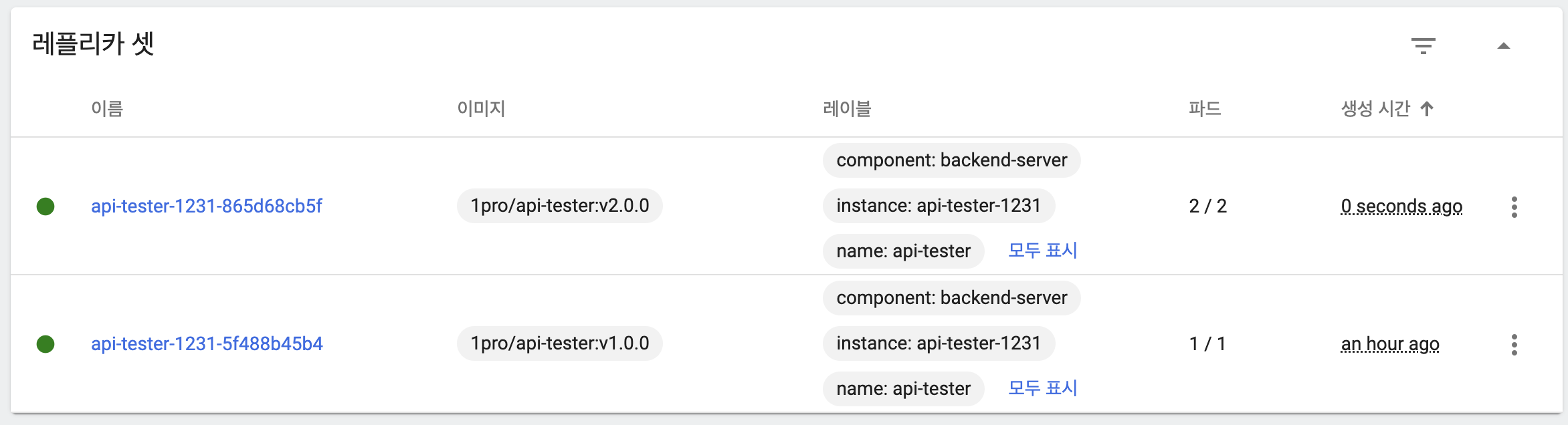
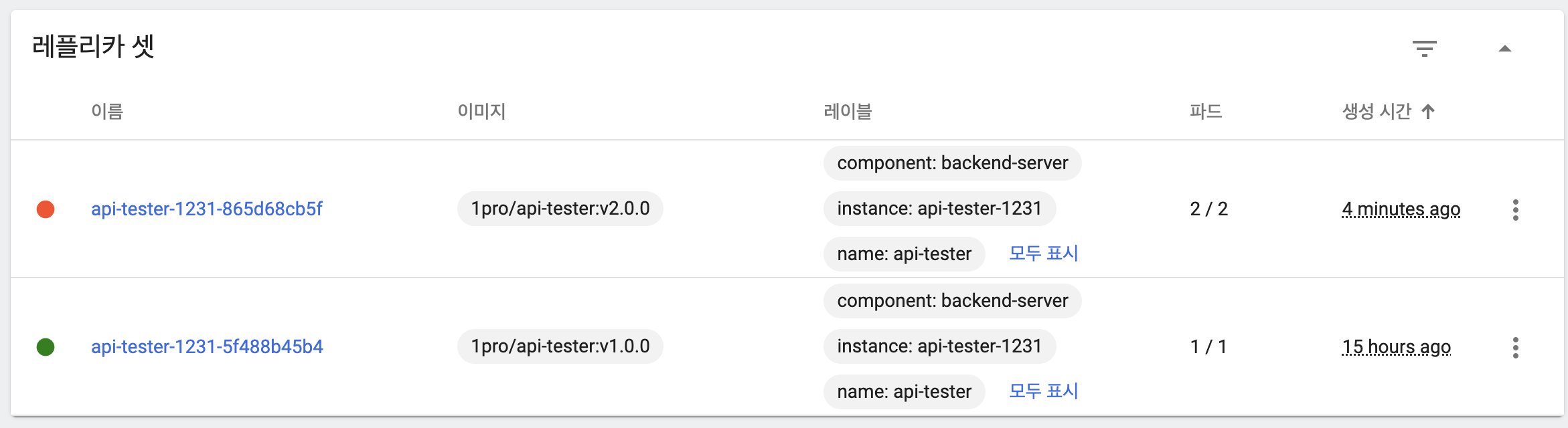
- 이전 버전 ReplicaSet을 활용해 maxUnavailable, maxSurge의 설정값을 토대로 롤백
- 이전 버전 파드 하나 추가
- 이전 버전 파드는 아직 기동되지 않음
- 새 버전 파드 하나 삭제

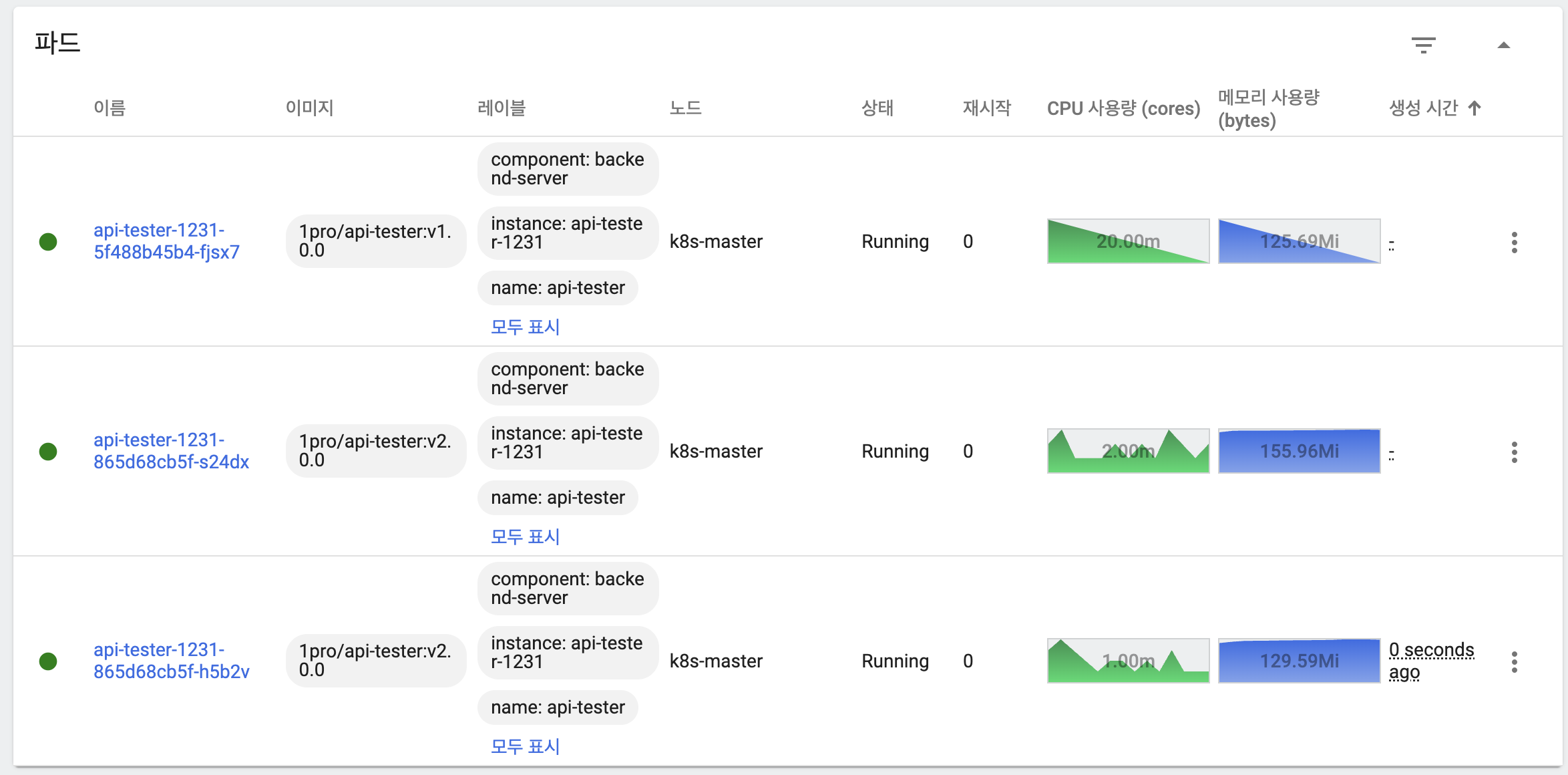

- 이전 버전 파드 하나 기동
- 새 버전 파드 하나 삭제
- 이전 버전 파드 하나 추가적으로 생성
- 응답을 통해 트래픽을 이전 버전과 새 버전 파드 모두가 처리하고 있음을 확인
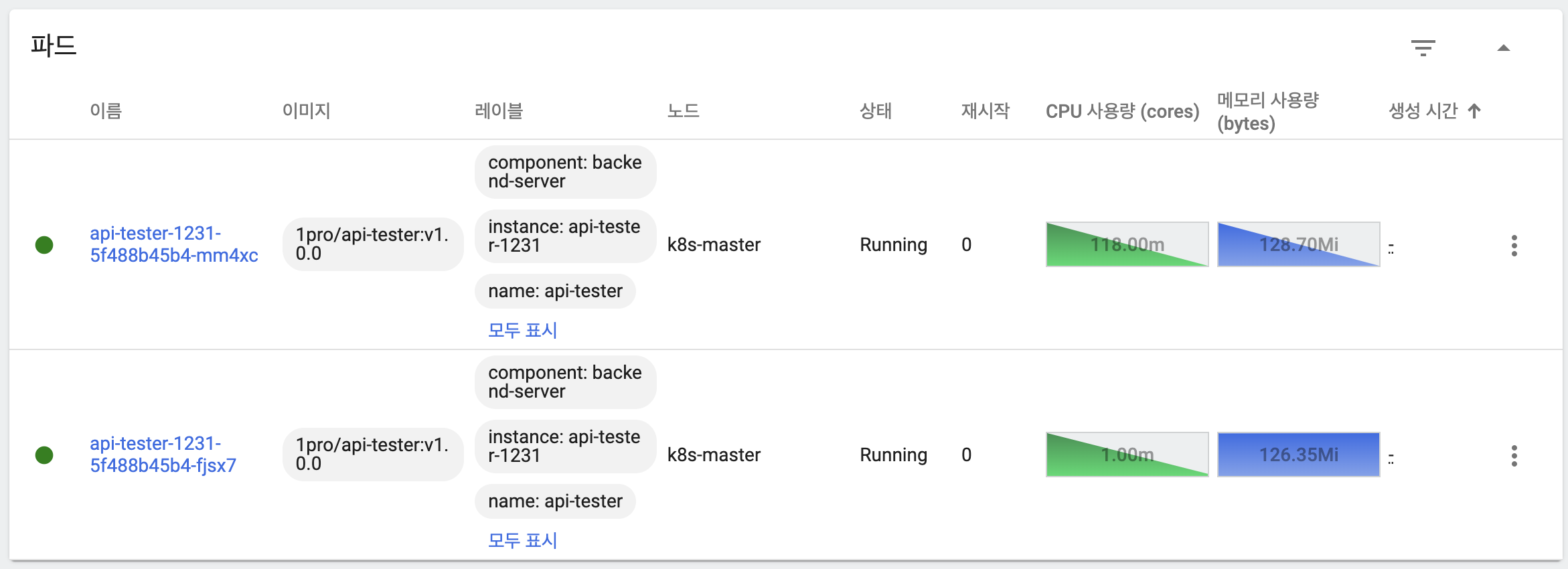


- 이전 버전의 파드가 replicas 수 만큼 생성되고 기동
- 새 버전 파드 모두 삭제
- 새 버전 ReplicaSet 유지
- 응답을 통해 트래픽을 이전 버전의 파드가 모두 처리하고 있음을 확인
maxUnavailable, maxSurge 변경
maxUnavailable: 50%, maxSurge: 50%

- 기본 상태

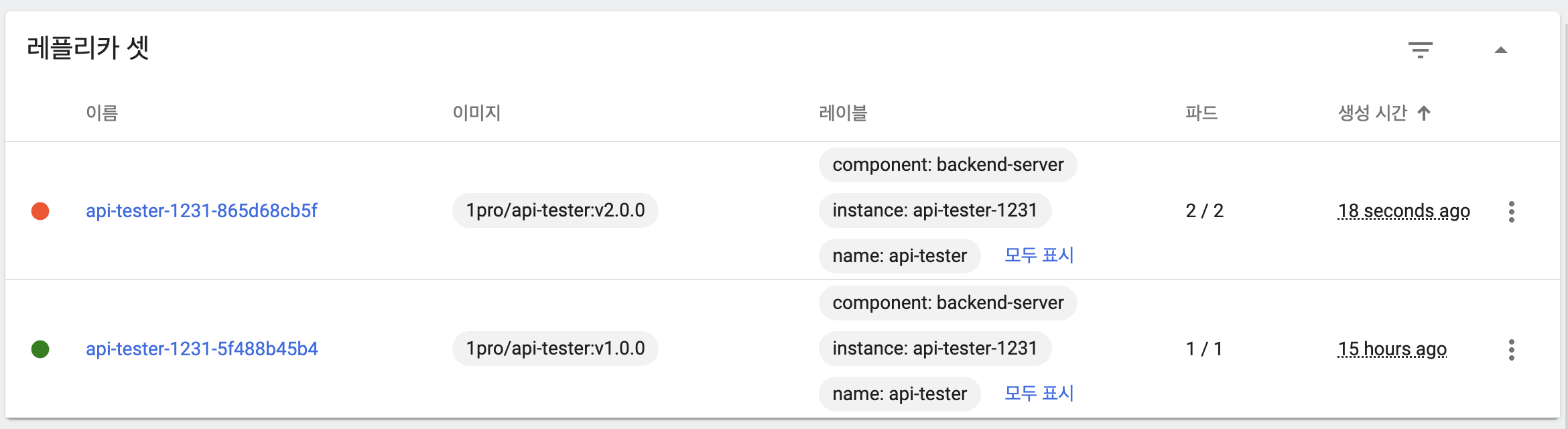
- 이전 버전 파드 하나 유지
- 새 버전 파드 두 개 생성
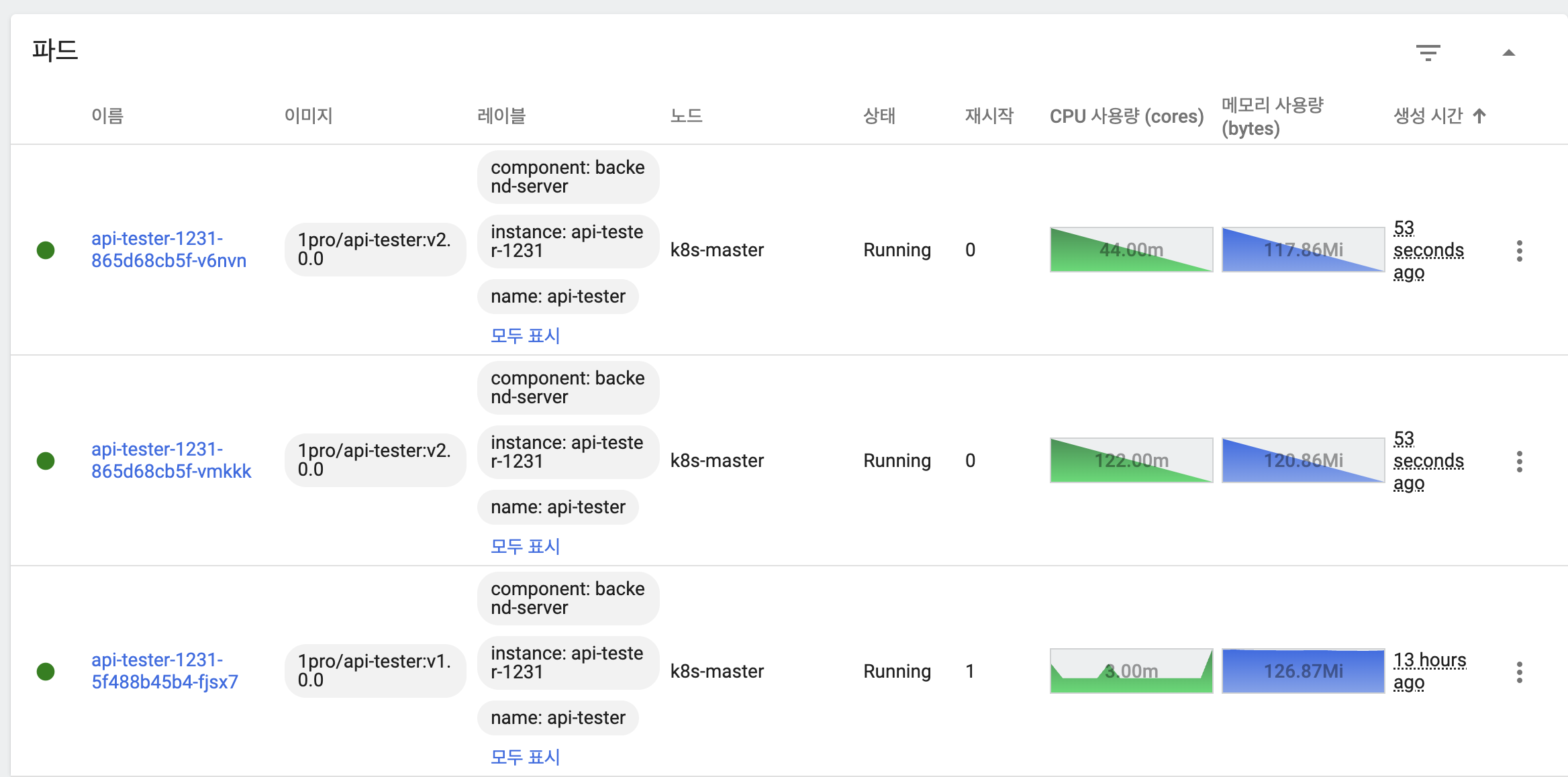
- 일시적으로 모든 파드가 트래픽을 처리하고 있음


- 이전 버전 파드 삭제
maxUnavailable: 50%, maxSurge: 49%
- 기본 상태
- 이전 버전 파드 하나 유지
- 새 버전 파드 두 개 생성
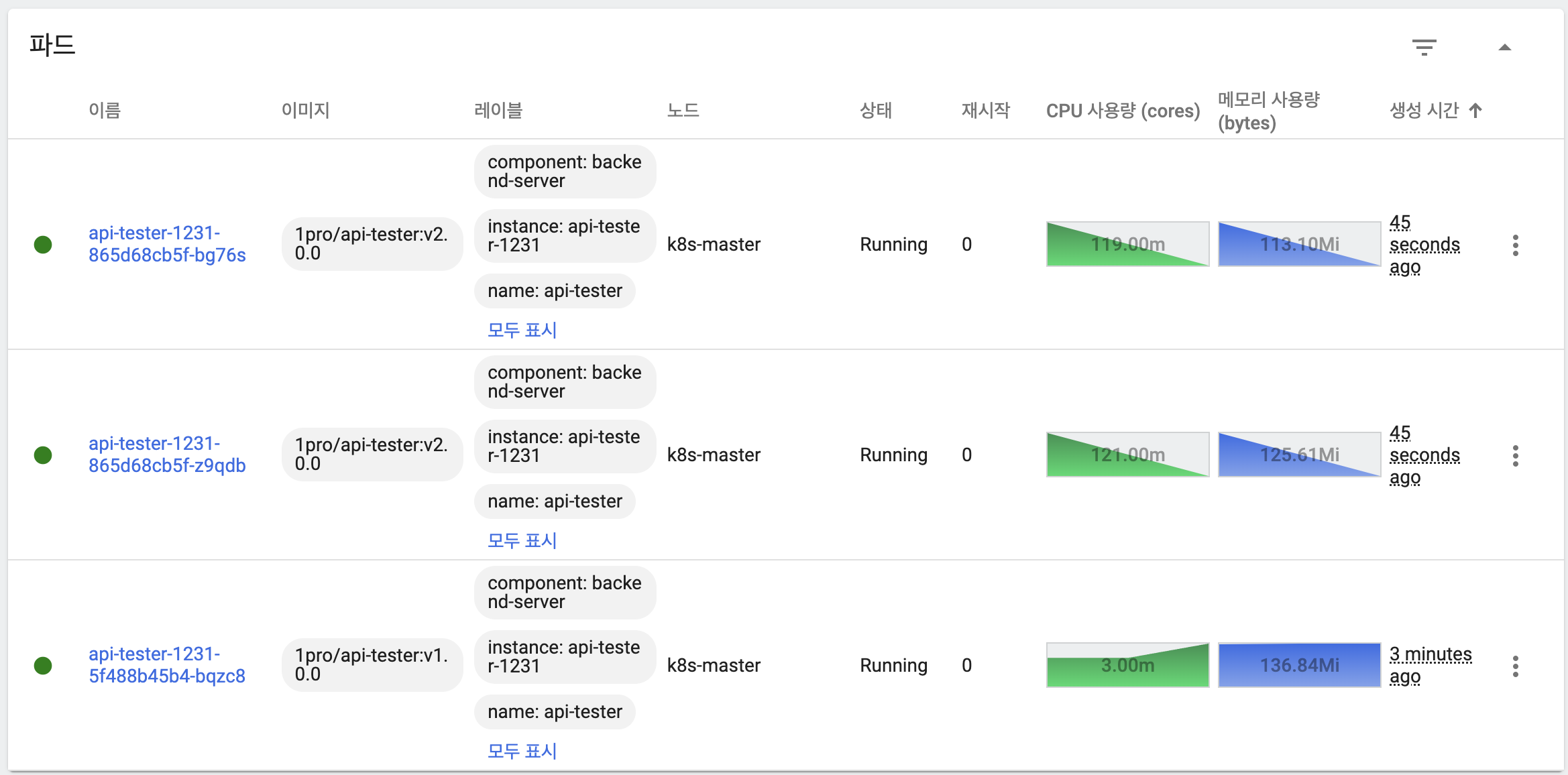

- 일시적으로 모든 파드가 트래픽을 처리하고 있음

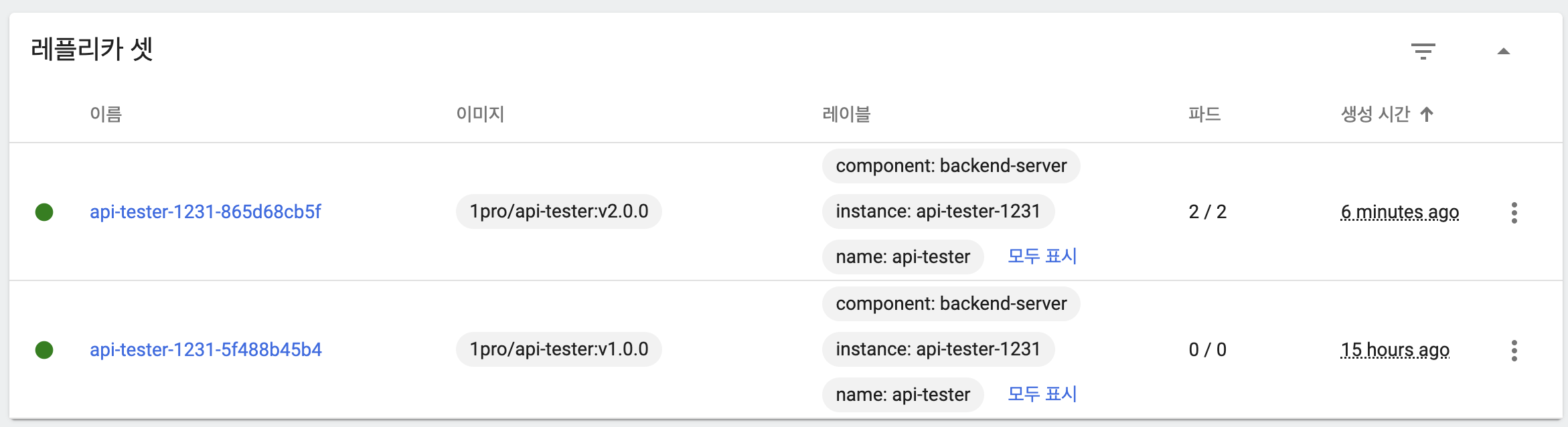
- 이전 버전 파드 삭제
maxUnavailable: 50%, maxSurge: 26%

- 기본 상태
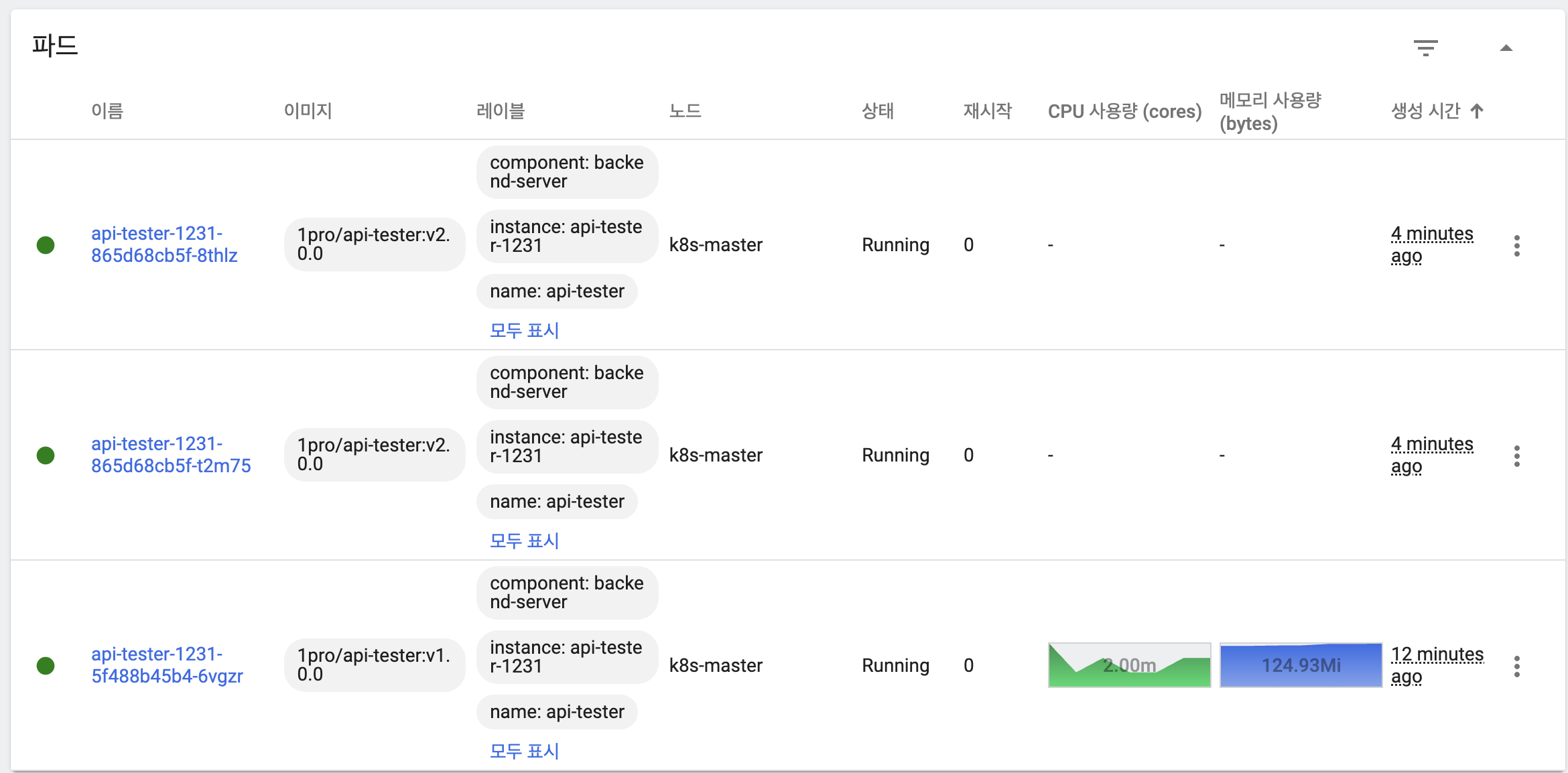
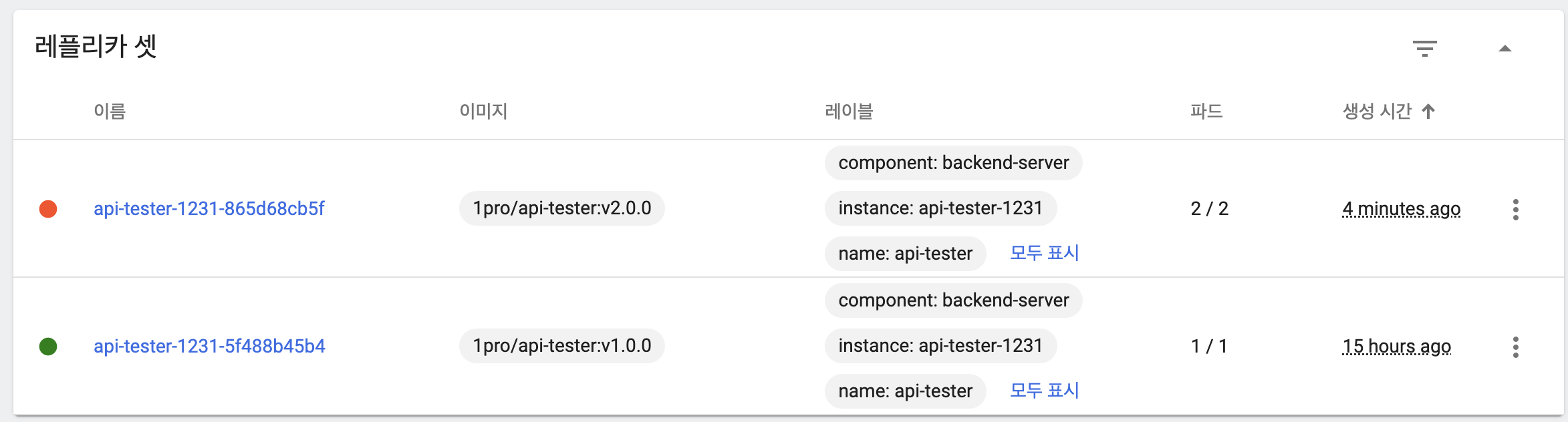
- 이전 버전 파드 하나 유지
- 새 버전 파드 두 개 생성

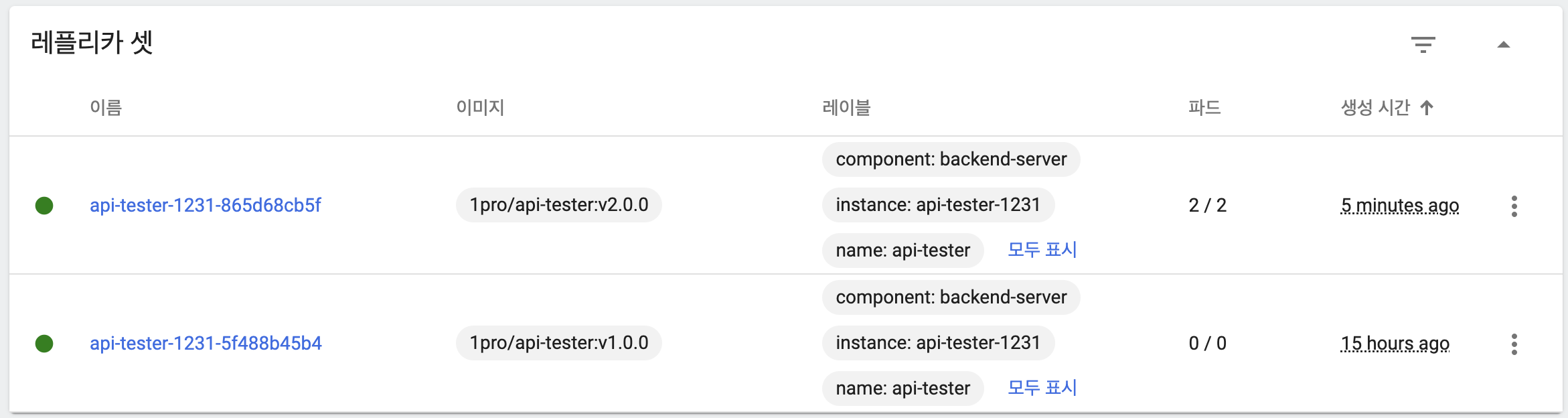
- 이전 버전 파드 삭제
maxUnavailable: 0%, maxSurge: 100%
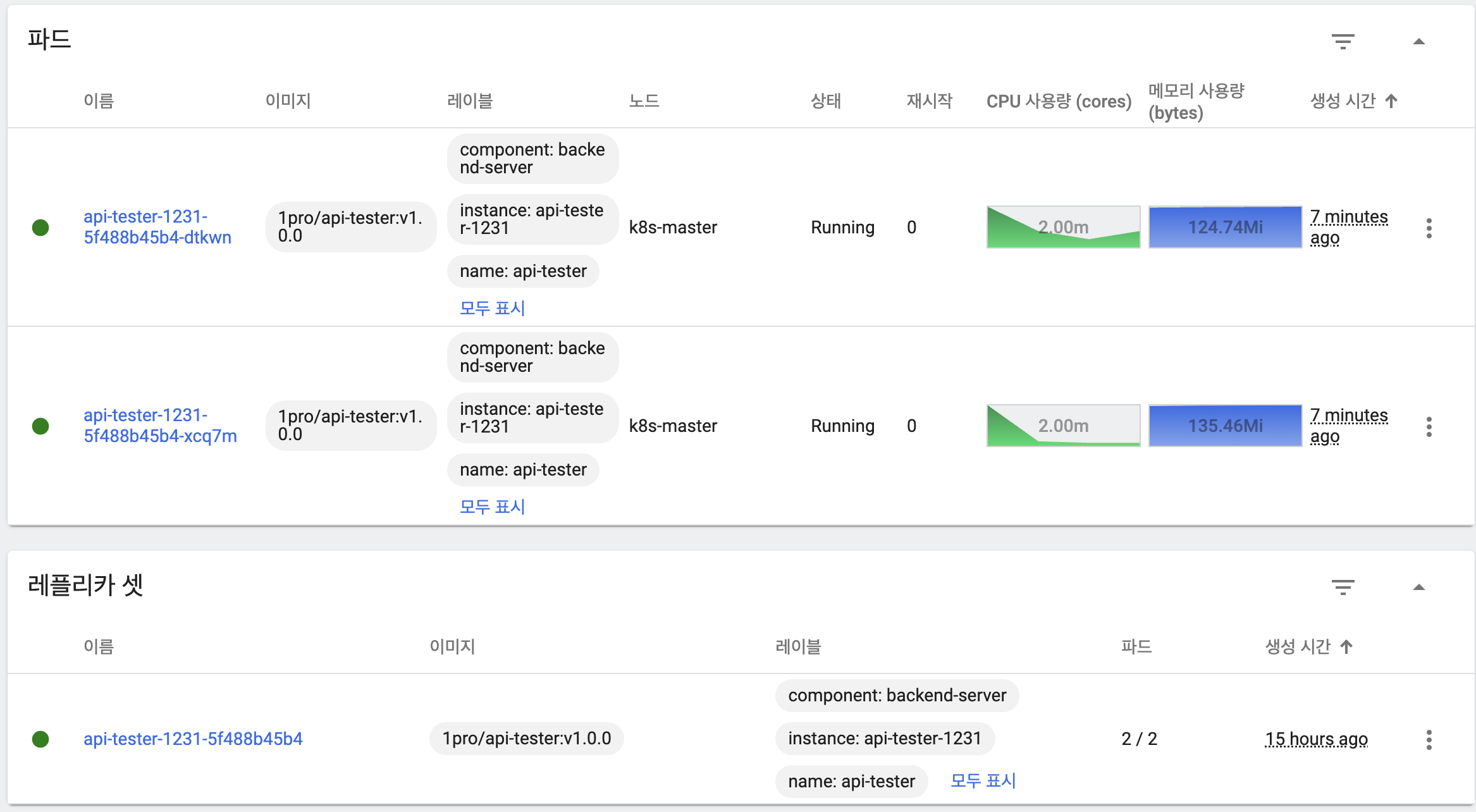
- 기본 상태

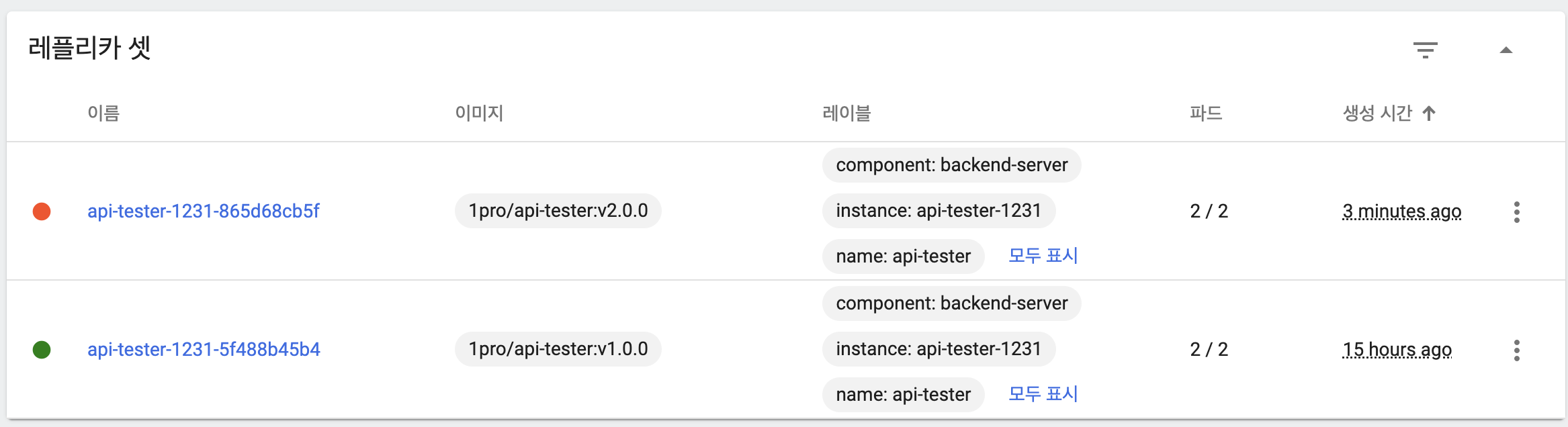
- maxSurge로 인해 새 버전 파드 2개 생성
- maxUnavailable로 인해 이전 버전 파드를 아무것도 삭제하지 않음

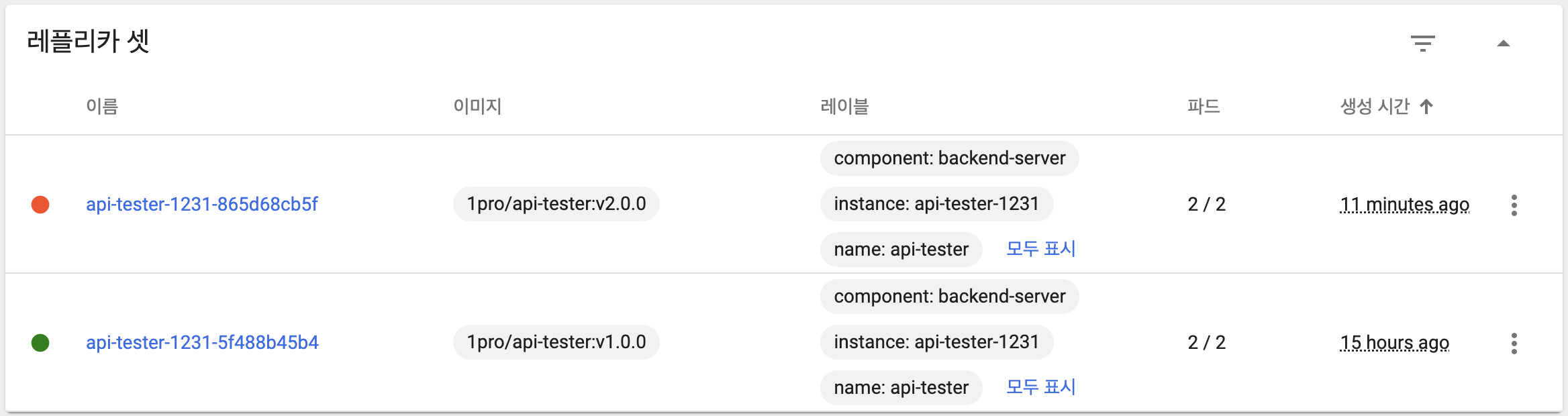
- 일시적으로 모든 파드가 트래픽을 처리하고 있음


- 이전 버전 파드 삭제
Recreate 동작 확인

- 기본 상태
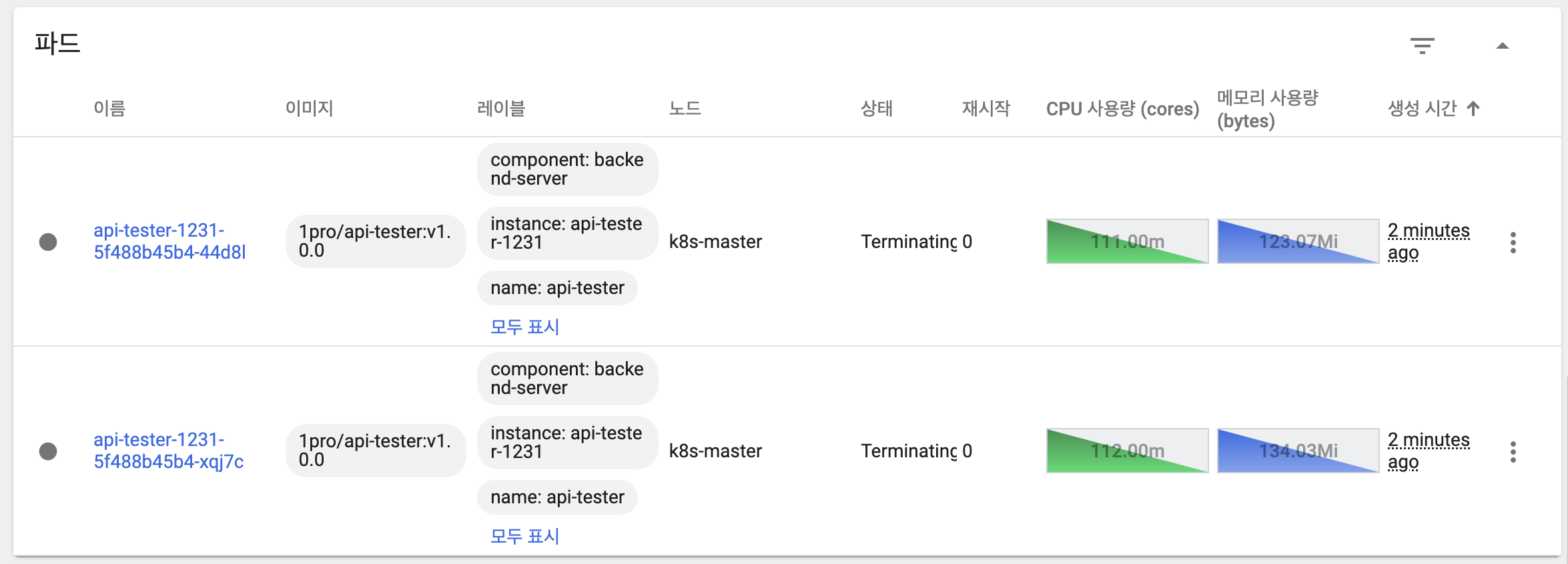

- 이전 버전 파드 삭제(Terminating)
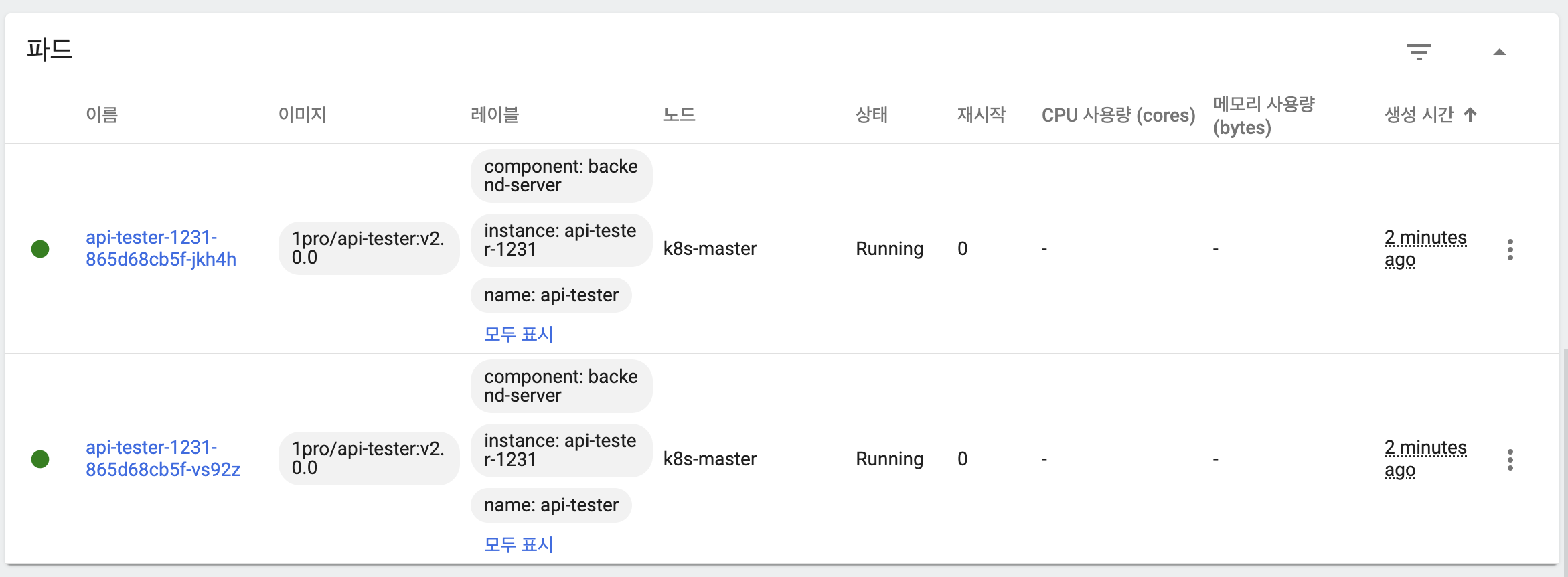
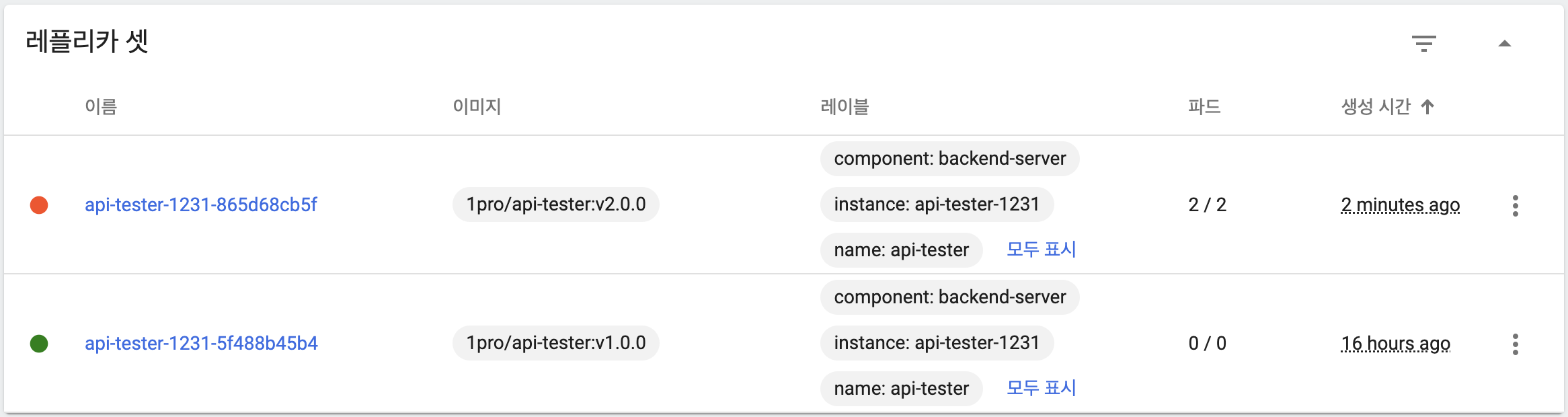
- 새 버전 파드 2개 생성

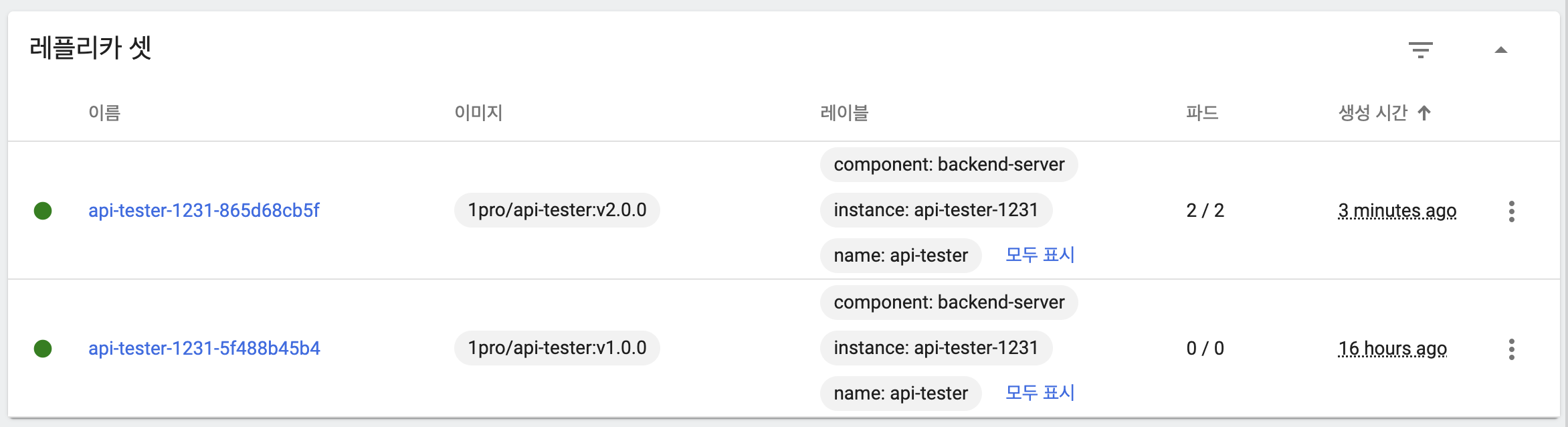
- 새 버전 파드 기동 완료
Service

- 역할
- 서비스 퍼블리싱
- 외부 트래픽을 매핑된 파드로 전달하는 기능 제공
- 내부 컨테이너 포트와 외부 포트 매핑 가능
- type : NodePort
- 외부 트래픽을 매핑된 파드로 전달하는 기능 제공
- 서비스 디스커버리
- 쿠버네티스가 내부 DNS를 통해 서비스의 이름을 API로 호출하는 기능 제공
- 파드 삭제 시 ip가 변경되므로 DNS 사용
- type : ClusterIP
- 파드 삭제 시 ip가 변경되므로 DNS 사용
- 쿠버네티스가 내부 DNS를 통해 서비스의 이름을 API로 호출하는 기능 제공
- 서비스 레지스트리
- 파드가 삭제되고 생성될 때 쿠버네티스가 서비스에 호출되는 IP를 제거하고 등록
- 파드에 서비스를 연결하면 ip 설정과 관련해 직접 처리할 필요가 없음
- 파드가 삭제되고 생성될 때 쿠버네티스가 서비스에 호출되는 IP를 제거하고 등록
- 로드밸런싱
- 서비스가 트래픽을 여러 파드에 분산
- 서비스 퍼블리싱
- 자주 사용되는 패턴
- 애플리케이션의 포트 변경에 서비스가 영향을 받지 않도록 하는 방법
- 파드 컨테이너 정보성 속성인 ports.name / ports.containerPort 사용
- 서비스의 targetPort에 ports.name을 지정해 매핑
HPA
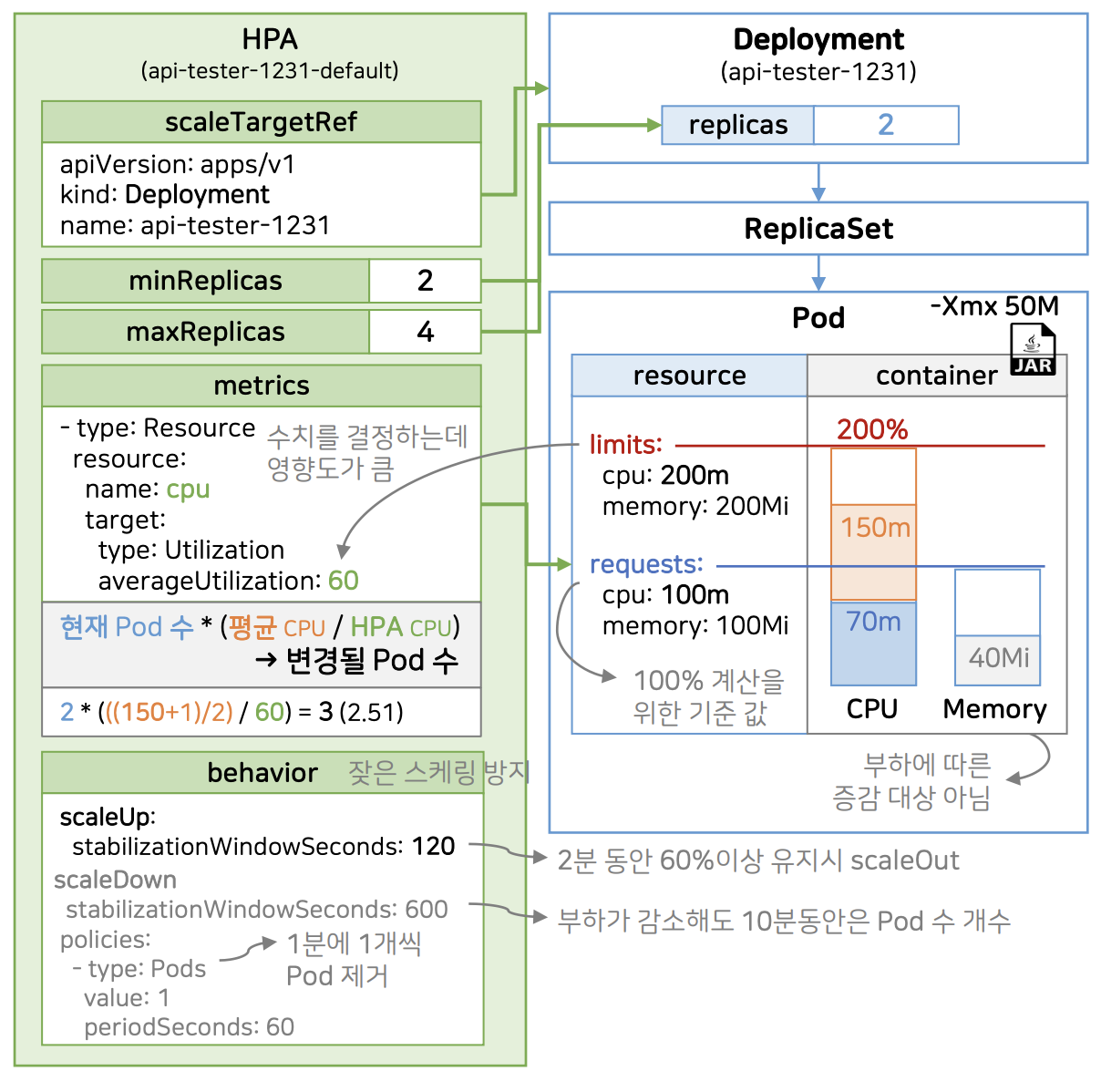
- 속성
- sacleTargetRef : Deployment 지정
- minReplicas : 최소 복제본 개수
- maxReplicas : 최대 복제본 개수
- 해당 파드는 minReplicas와 maxReplicas 범위 내의 개수가 생성될 수 있음
- metrics : 스케일링 조건
- metrics
- requests : 계산을 위한 100% 기준 값
- 컨테이너 내부에 CPU를 70m 사용하고 있다고 가정
- 파드 두개 중 하마나 70m이므로 평균 35% 사용
- 컨테이너 내부에 CPU를 220m(70m + 150m) 사용하고 있다고 가정
- 평균 60%을 넘어 스케일 아웃 발생
- 계산 공식
- 변경될 파드 수 = 현재 파드 수 * (평균 CPU /HPA CPU)
- limits
- 하나의 파드에서 CPU를 사용할 수 있는 비율 제한
- 평균 임계치를 결정하는데 큰 영향을 끼침
- memory
- 애플리케이션 사용 상황에 따라서 변하는 값이지 부하에 따른 변하는 값이 아니므로 거의 사용하지 않는 옵션
- CPU만만으로는 모든 애플리케이션에 대한 부하 상태를 판단하기 어려움
- 큐, DB 커넥션, 스레드 등 애플리케이션에 따라 부하가 가해지고 있는 상태라고 판단하는 기준이 다르기 때문
- 다양한 부하를 체크할 수 있는 별도의 솔루션 사용
- CPU만으로 판단할 수 있다면 HPA만 사용해도 무방
- behavior
- 잦은 스케일링을 방지하기 위함
- 순간적으로 CPU 사용량이 폭증하는 경우를 대비하기 위함
- scaleUp.stabilizationWindowSeconds : 지정한 시간동안 CPU 사용량을 유지할 경우 스케일 아웃 적용
- scaleDown.stabilizationWindowSeconds : 부하가 감소해도 지정한 시간동안 파드 수 유지
- policies.value : 부하가 감소했을 때 파드를 한 번에 삭제하는 것이 아닌 지정한 값만큼만 삭제

- 이상적인 스케일링
- 평균 부하가 꾸준히 증가하다가 임계치를 넘으면 스케일 아웃 적용
- 평균 부하 감소
- 트래픽이 감소하면서 평균 부하 감소
- 평균 부하가 감소했으므로 스케일 인 적용
- 평균 부하 증가
- 평균 부하가 꾸준히 증가하다가 임계치를 넘으면 스케일 아웃 적용
- 현실적인 스케일링
- 평균 부하가 급격하게 증가
- 모든 파드가 Error 발생
- CPU가 임계치를 넘겼으므로 스케일 아웃 적용
- 파드 2개 생성
- 쿠버네티스 self healing에 의해 Error가 발생한 파드 재시작
- 파드 2개 재시작
- 재시작 또는 스케일 아웃이 적용된 파드가 기동이 완료될 때 까지 서비스 중단
- 서비스 안정화
- 평균 부하가 감소했으므로 스케일 인 적용
- 평균 부하 증가
- 평균 부하가 급격하게 증가
- 문제
- 미리 예상하지 못한 트래픽이 올 경우 스케일링만으로는 대응이 어려움
- 해결 방안
- 서비스마다 피크 시간을 분석해 미리 자원을 증설
- 대기열 아키텍처 적용
실습
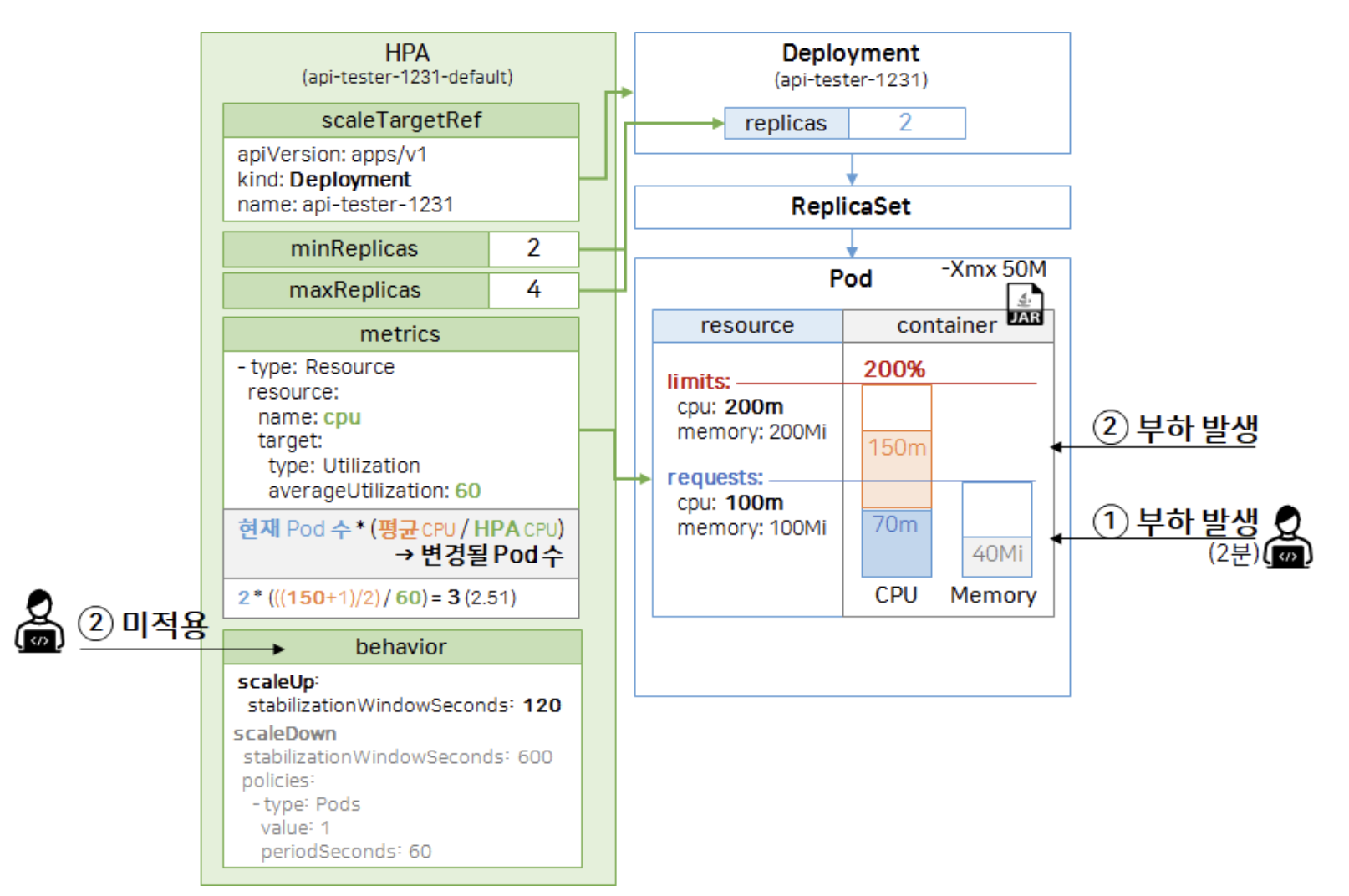
curl http://192.168.56.30:31231/cpu-load?min=3&thread=5- 부하 발생 요청
kubectl top -n anotherclass-123 pods
kubectl get hpa -n anotherclass-123- 파드 및 HPA 정보 확인
scaleUp.stabilizationWindowSeconds 적용 시

- 15:02:09 요청
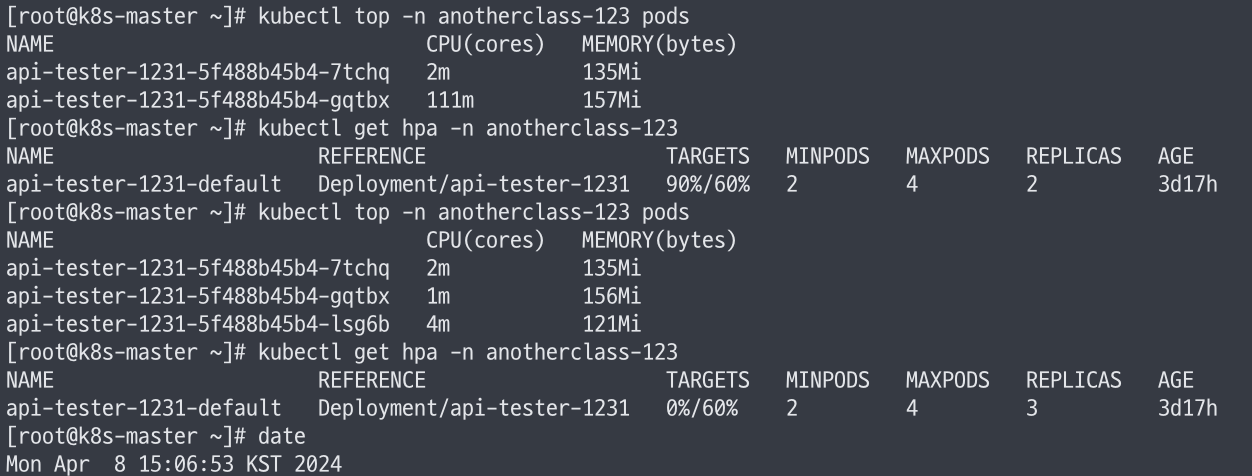
- 15:06:53에 복제본 수 3으로 증가
scaleUp.stabilizationWindowSeconds 미적용 시

- 15:27:35 요청
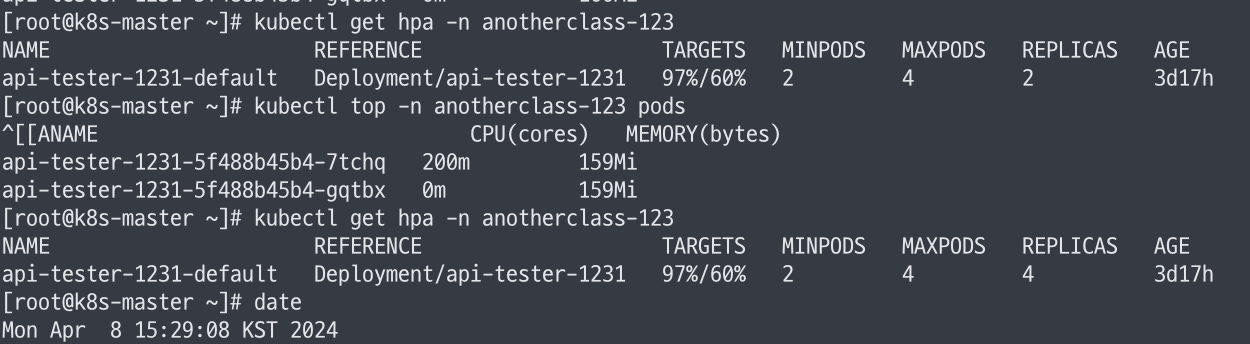
- 15:29:08 복제본 수 4로 증가

안녕하세요