DB에서 적은 양의 데이터를 조회하는 것은 아무런 문제가 없다. 그러나 데이터의 양이 많아질 수록 프로그램 전체의 속도가 감소하는데 이를 처리하는 방식은 다양하다. 그 중에 가장 많이 쓰이는 방식을 시도해 볼 것이다.
Trigger vs Procedure(DB에서 사용하는 기능)
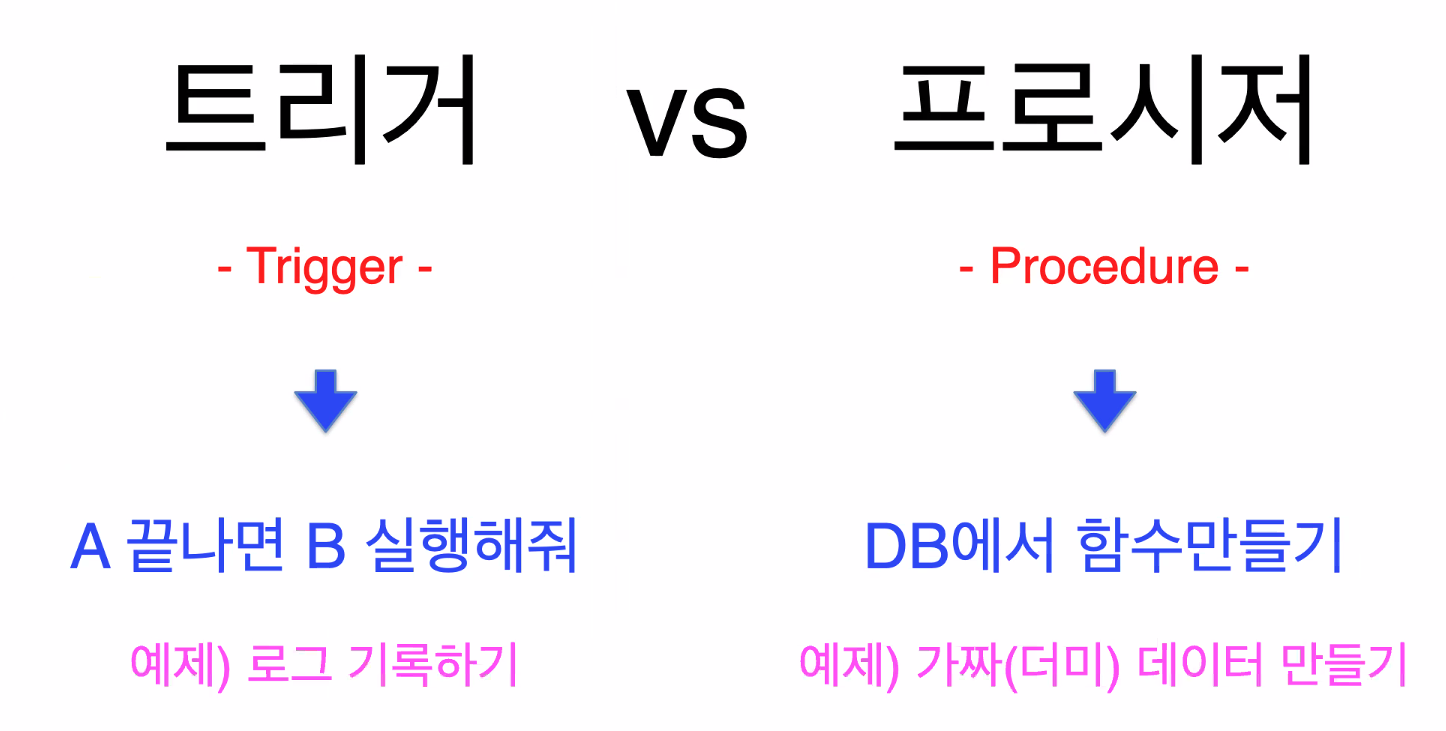
트리거는 a가 끝나면 b를 실행한다. 예를 들어 상품테이블에 상품을 등록했을 때 그 상품의 정보가 담긴 로그를 찍는 함수를 만들 수 있는 것이다.
프로시져는 DB에서 함수를 만들 수 있게 해준다.
요즘엔 DB에서 함수를 만드는 것을 선호하지 않는다. DB만을 따로 관리하는 전문가가 존재하므로 그들에게 맞기는 것이 요즘 추세이다.
trigger를 만들어보자.
트리거는 중요한 내용에는 사용 X,
결제 테이블에 결제 시, 유저 테이블의 돈 올려준다고 가정했을 때
트리거를 통해 결제 하면서 돈을 올려줄 수 있다.
근데 다른 사람들과의 협업 시 다른 사람들이 트리거를 생각하지
않고 코드를 수정하면 큰 오류가 발생할 수 있다.
비지니스에 타격이 크지 않고 귀찮은 것들을 트리거로
적용하는 것이 낫다.
보통 로그나 통계에 적용!
Index(책갈피)
프로시저를 사용해서 더미데이터를 만들고 나면
이런 식으로 데이터들이 생성된다.
이때 우리는 여러 타이틀 중 원하는 데이터를 빠르게 찾는 것이다. 수 없이 많은 데이터(약 1000만) 중에서

이 데이터를 찾는데 얼마나 걸릴까
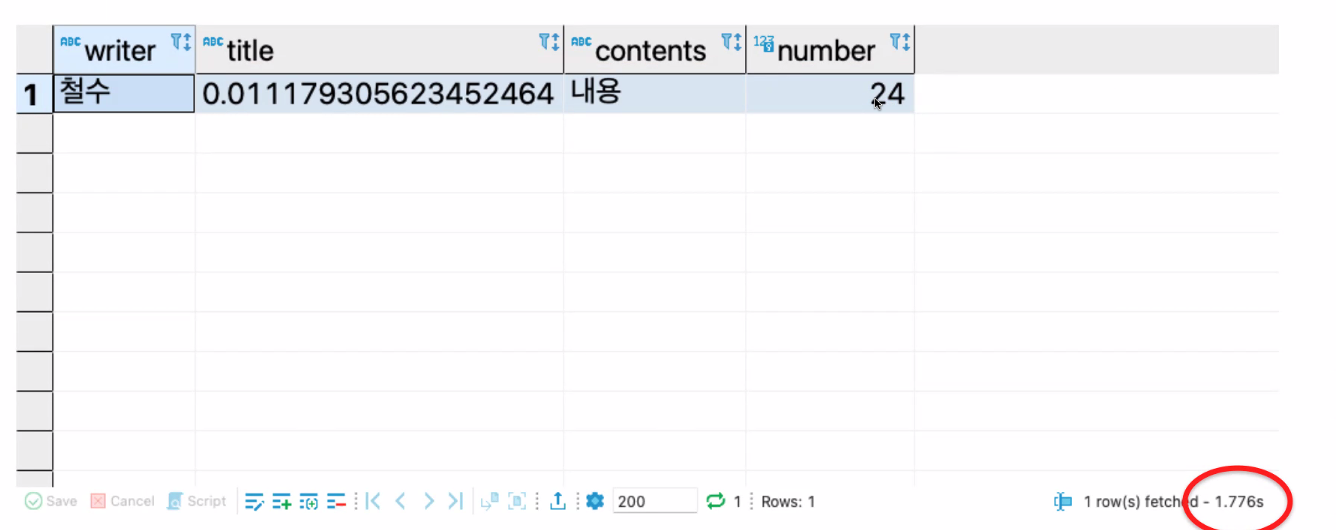
약 2초 정도 걸린다. 1명의 기준에선 빠른 것처럼 느껴진다. 그러나 100명의 사용자가 요청을 보내면 100번째 사람은 200초 가까이 기다려야 할 것이다.
아까는 타이틀로 찾았었지만 이번엔 number로 찾아보자. 그러면 0.006초가 나온다.
왜 이런 결과가 나올까?
Explain명령어로 옵티마이저의 실행계획을 분석하면 이해할 수 있다.
옵티마이저란?
DB에서 검색을 효율적으로 해주는 DB내장 기능
실행계획?
?옵티마이저가 어떻게 하면 데이터를 효율적으로 찾을 지 계획을 뽑아내는 것
ex) 1번부터 찾을지 마지막부터 찾을지?
Explain?
옵티마이저가 결정한 실행 계획을 확인하는 명령어이다.
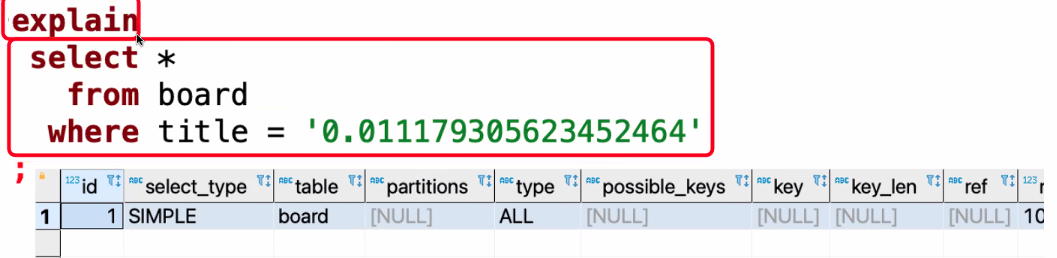
첫 번째 쿼리에 explain을 넣고 결과를 잘 살펴보면 type에 all이라고 명시되어있다. 이는 전체 다 뒤져서 찾아낸다는 의미인데 수많은 데이터를 전부다 뒤져서 찾아낸다니 이 얼마나 좋지 못한 방법인가..

두 번째 쿼리에 explain을 넣고 결과를 살펴보자

두 개의 rows를 비교해보면 천만과 1이다. 두 번째 방식으로 찾아내면 1번 만에 찾을 수 있다는 의미이다.
explain의 결과 중 type의 의미들

그럼 왜 두 쿼리가 차이가 날까?
PK, FK, UNIQUE는 자동으로 인덱스(책갈피)가 생성이 되기 때문이다.

PK, FK, UNIQUE말고도 다른 컬럼에 인덱스를 적용할 수 있다.
CREATE INDEX idx_title ON board(title); //board테이블에서 title을 idx_title이라는 이름으로 인덱스를 등록해준다.
모든 데이터에 인덱스를 적용하면 검색은 빨라지지만 데이터 등록과 수정 시 인덱스를 적용하기 위한 재정렬 과정이 매번 발생하여 많은 시간을 요하게 된다.
즉, 인덱스는 등록보단 검색에 초점이 잡혀있는 것이다!
필요한 부분에서 적절히 사용하는 것이 좋아보인다.
쿼리문
SHOW PROCEDURE status;
CREATE PROCEDURE mydummydata()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 5000000 do
INSERT INTO board(writer, title, contents) VALUES('철수', RAND(),'내용');
SET i = i + 1;
END WHILE;
END; //500만 개의 더미 데이터 생성하는 함수
SHOW PROCEDURE status; //PROCEDURE확인
CALL mydummydata();// 더미 데이터 생성 함수 호출
SELECT count(*) FROM board; //데이터가 얼마나 있는 지 확인
SELECT * FROM board WHERE title='0.4305621007742007'; //찾는데 걸리는 시간
SELECT * FROM board WHERE number = 6;
EXPLAIN
SELECT * FROM board WHERE title='0.4305621007742007';//어떤 방식으로 데이터를 찾는 지 확인
EXPLAIN
SELECT * FROM board WHERE number = 6;
SHOW INDEX FROM board; //인덱스가 지정된 데이터 확인
CREATE INDEX idx_title ON board(title); //인덱스 생성!
SHOW INDEX FROM board;
EXPLAIN
SELECT * FROM board WHERE title='0.4305621007742007';
SELECT * FROM board WHERE title='0.4305621007742007';BigQuery
무작위로 발생하는 로그 데이터를 저장하는 데이터베이스? 엄청나게 많은 데이터를 저장할 수 있고 빠른 속도로 조회할 수 있는데 충분히 사용할 만한 비용이라 대중적으로 사용된다!
Redis(속도가 빠른 DB)
메모리 기반(임시저장: 캐싱, TTL(TIME TO LIVE)) DB으로 기존 다른 DB들은 하드디스크에 저장하여 비휘발성으로 컴퓨터를 종료해도 데이터가 남아있는데 보통 메모리기반 DB는 메모리에 데이터를 저장하여 빠른 속도를 자랑하지만 컴퓨터 종료시 데이터가 사라지는 휘발성이라는 성질을 갖고 있다. 레디스는 특별하게 데이터가 날라가지 않게도 설정이 가능하다! 하지만 영구적으로 저장하는 DB로는 사용하진 않는다.
Redis의 사용 패턴
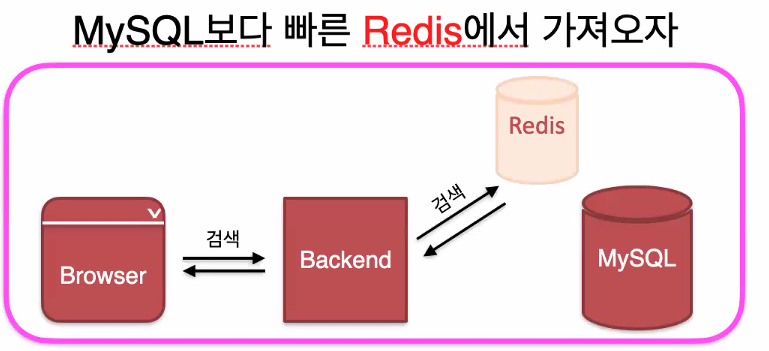
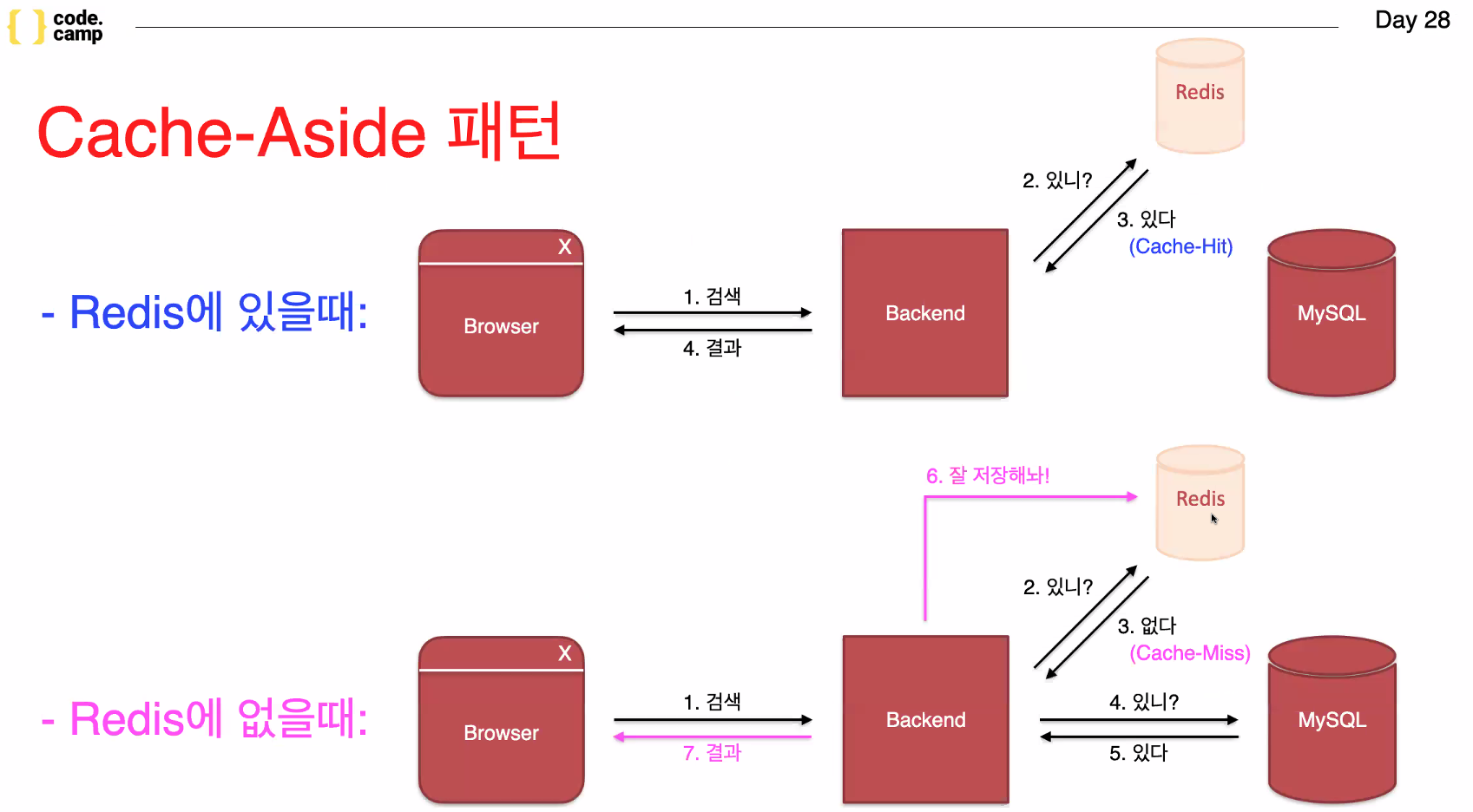
빠른 검색용 -Cache-Aside 패턴-
검색 시 데이터가 레디스에 있으면 데이터를 리턴해주고, 없으면 mysql에서 찾아서 데이터를 리턴해주고 레디스에 캐싱한다. 즉, 똑같은 데이터에 대한 두 번째 검색은 빠른 속도로 진행할 수 있다.
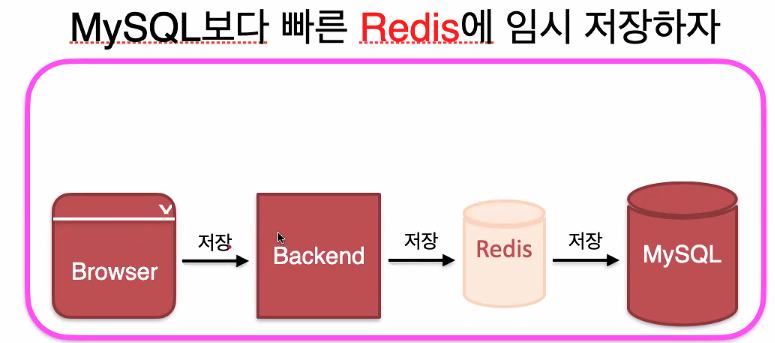
임시 저장용 -Write-Back 패턴-
보통 디스크에 바로 저장하면 느린 속도로 저장이 된다. 너무 많은 데이터가 한 번에 디스크에 저장되면 디스크i/o가 발생하는 데 이를 해결하기 위해 데이터를 레디스에 먼저 저장하고, 레디스를 통해 mysql에 천천히 저장하는 방식이다.
레디스 실습!
우선은 레디스를 사용해보도록 하자! 우리는 board를 찾을 때 Redis에 먼저 있는지 확인하고, 없다면 MySQL에서 찾아와 Redis에 저장하는 방식으로 구현할 것 이다.
Redis는 KEY와 VALUE형식으로 값을 저장한다는 걸 기억하자!
import { Args, Mutation, Query, Resolver } from '@nestjs/graphql';
import { BoardService } from './boards.service';
import { CreateBoardInput } from './dto/createBoard.input';
import { Board } from './entities/board.entity';
import {Cache} from 'cache-manager'
import { CACHE_MANAGER, Inject } from '@nestjs/common';
@Resolver()
export class BoardResolver {
constructor(
private readonly boardService: BoardService,
// Redis사용을 위해 CACHE_MANAGER를 주입하자
@Inject(CACHE_MANAGER)
private readonly cacheManager: Cache
) {}
@Query(() => [Board])
async fetchBoard(
@Args('search') search: string,
) {
//레디스에 정보가 있다면 레디스에서 가져와 리턴
const res = await this.cacheManager.get(search)
if(res) return res
// 없다면 mysql에서 가져와 레디스에 저장하고 리턴!
const Mysql = await this.boardService.findOne({search})
await this.cacheManager.set(search, Mysql)
return Mysql
}
//레디스에 바로 저장할 때!
@Mutation(() => String)
async createBoard(
@Args('writer') writer: string,
@Args('title') title: string,
@Args('contents') contents: string,
@Args('createBoardInput') createBoardInput: CreateBoardInput,
) {
// await this.cacheManager.set("aaa", writer)//key value형태로 저장
await this.cacheManager.set("bbb", createBoardInput,
{
ttl: 0, //저장하는 시간!
})//객체도 그냥 저장 가능!!
const mycache = await this.cacheManager.get('bbb') ///aaa에 있는 값 가져오기
console.log(mycache)
return '캐시 테스트 중!!!'
}
}간단한 레디스 명령어들!
레디스 접속
redis cli
docker exec -it containerid redis-cli
//만약 한글이 깨지는 경우?
docker exec -it containerid redis-cli --raw
키 찾기
keys *
키 추가
set aaa apple
내용 확인
get aaa
만료시간 주기
expire aaa 50
만료시간 확인
ttl aaa
전체 삭제
FLUSHALL마치며
레디스에 대해 조금은 알았따!
