실시간 채팅을 구현해야하는 프로젝트를 진행하면서
골격이 완성되고 서버에 배포하기전 artillery 와 Jmeter를 이용한 부하테스트에서 수많은 문제폭탄을 마주치며 여러 노력들을 해본 결과
초당 1000건 이상의 요청을 지속적으로 쏟아부어도 socket의 응답속도는 평균 0.5ms로 목표치에 근사하게 서버가 구축이되었다.
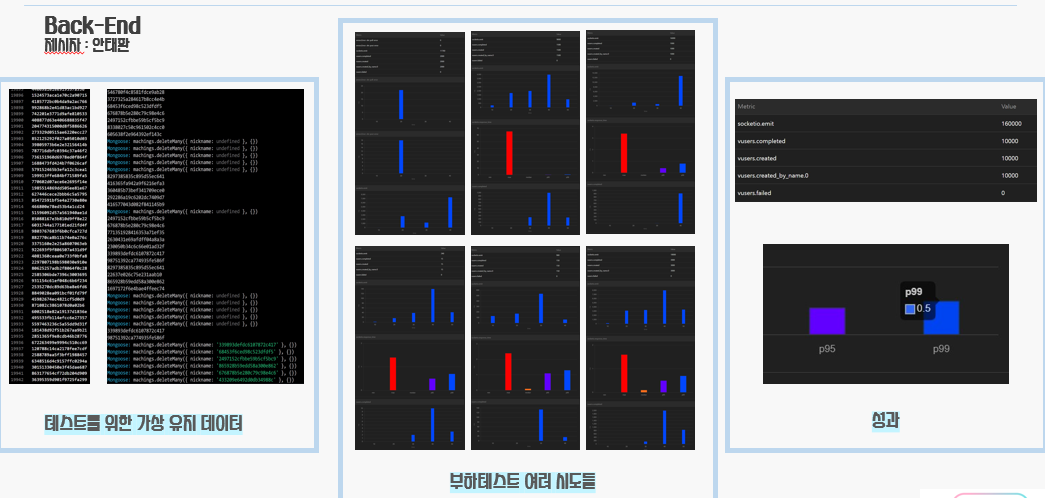
그런데 런칭 하루 전 배포를 하고 나서 진행한 테스트에서 점진적으로 요청건수를 늘려가던 와중에 초당 50건 이상의 부하를 주는 중 접속하여 서비스를 이용해보니 경과시간에 비례하여 레이턴시가 점점 비약적으로 증가하기시작하고 급기야 응답속도는 최대 10초가 넘어가는 상황이 발생하였다.
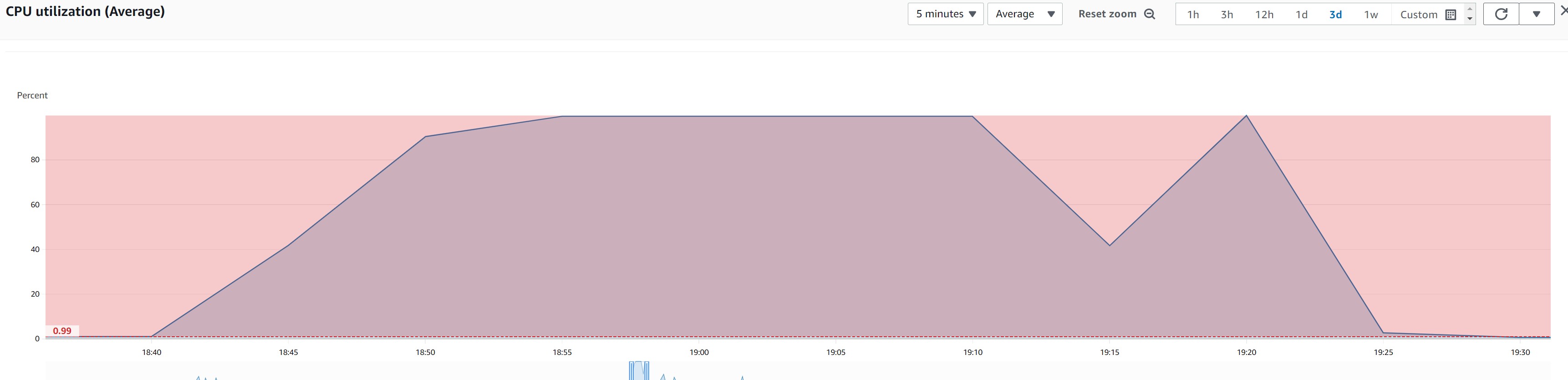
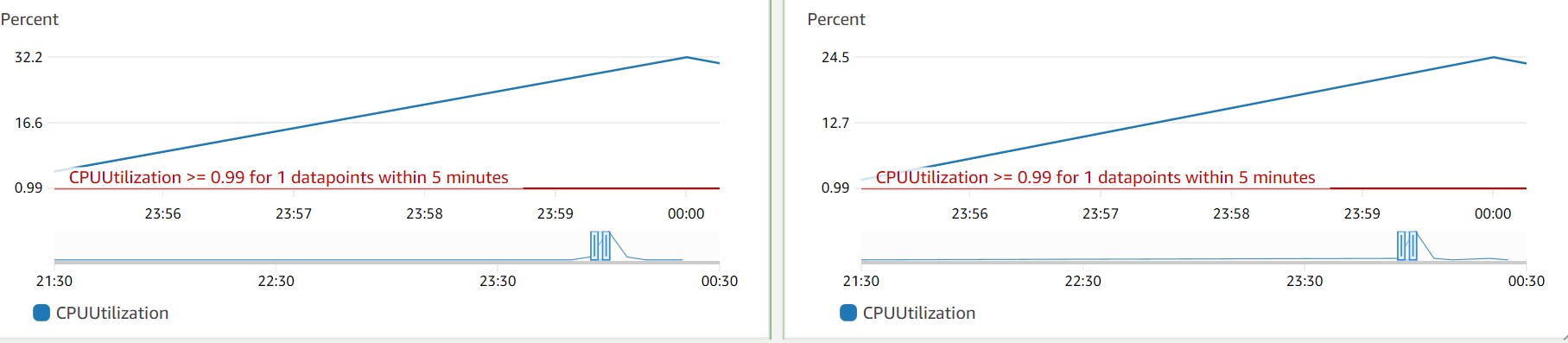
이정도 워크로드로는 DB문제는 아니겠거니 하며 혹시나 하는마음에 서버 cpu로드율을 보니 아래와 같은 상태를 지속하고있었다.

cpu는 풀로드 되고있었고,인스턴스 cpu를 재확인해보니 아래와같이 트래픽을 감당하지 못하고있었다. 프로덕션환경의 실제 서버 스팩을 고려하지않아 생긴 문제다.
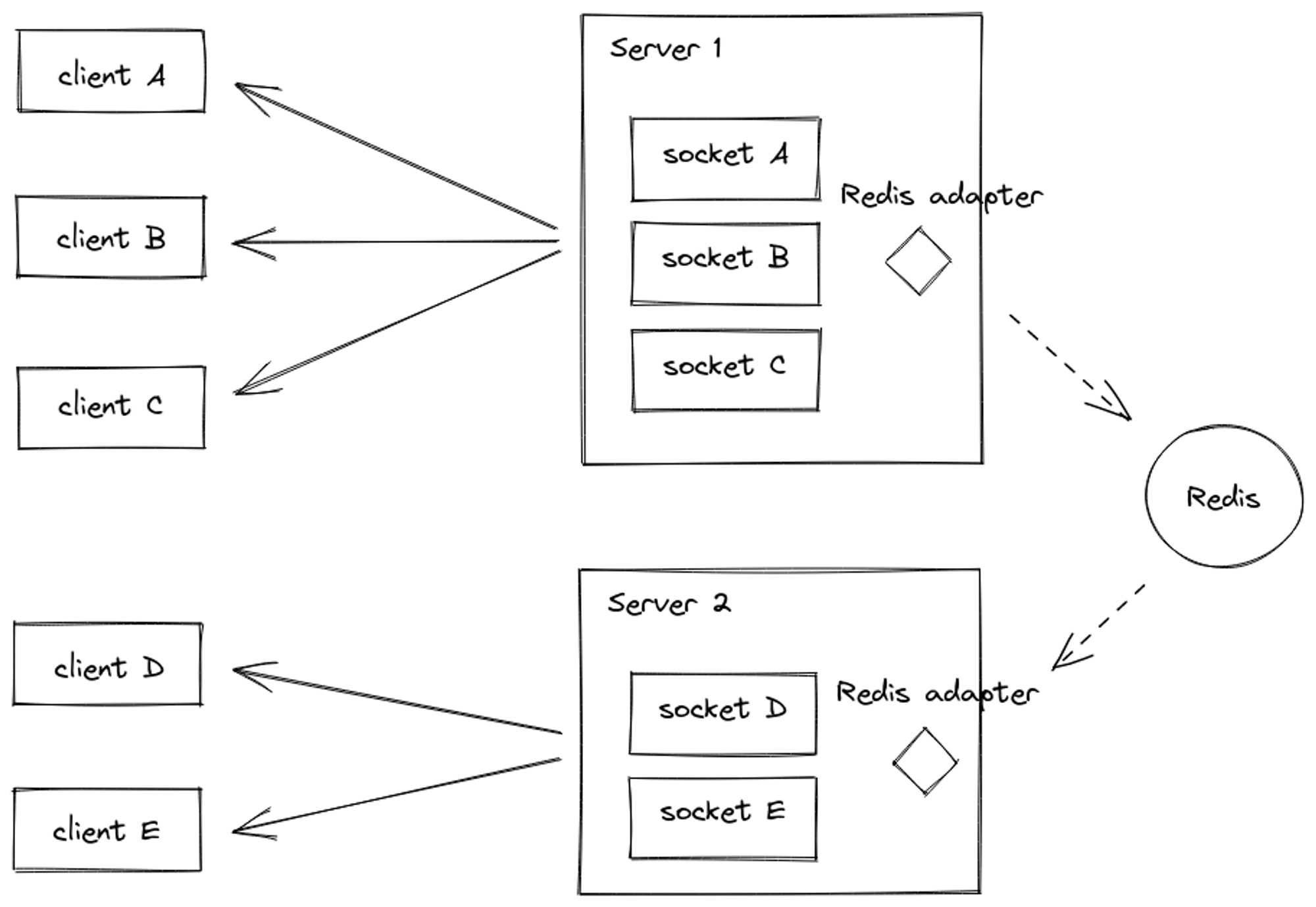
하루밖에 남지 않은 상황이라 빠르게 해결하고자 즉시 서버를 분산시켜 로드밸런싱을 하였는데 이로인해 서버간 socket 통신에 문제가 생기기 시작했다.

위와 같이 다른 서버의 클라이언트와는 통신이 불가능하다는..
당연한 문제였으나 아무생각없이 트래픽 분산에만 신경을 쓰다보니 막상 닥치고나서야 문제를 인지하였고 빠르게 해결해야만 했기에 해결방안을 모색하였다.
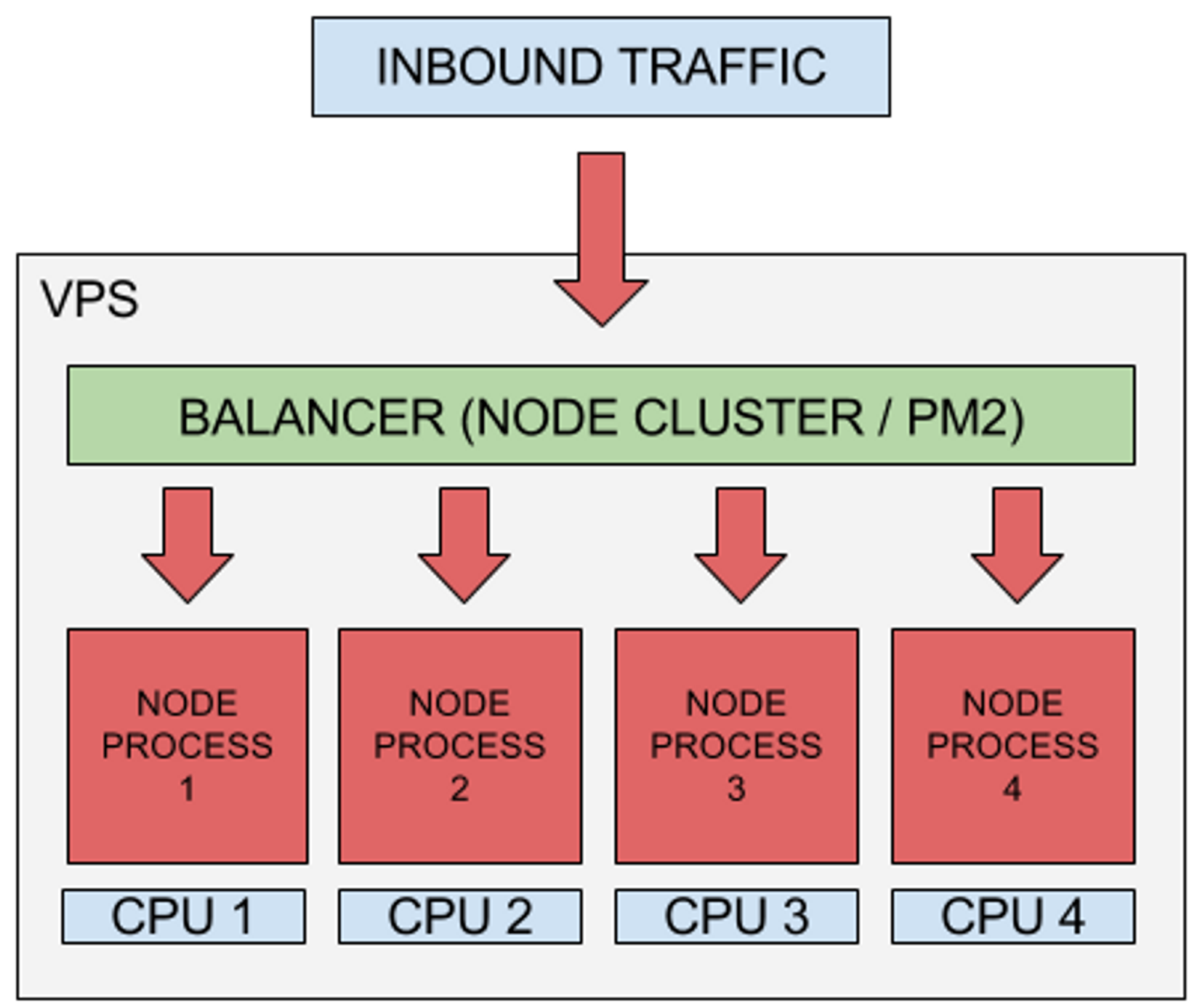
- 스케일업
1-1. 클러스터링을 하고난 이후에
haproxy 나 nginx를 이용하여 loadbalancing을 해준다.
동시에 스펙업을 통해 물리적 사양또한 증가시킨다.
redis adapter를 사용해 통신연결 시킨다.
- 스케일아웃
2-1. autoscaling 과 ELB를 이용해 지속적으로 인스턴스의 상태를 체크하고 과도한 트래픽이 감지되었을때 자동으로 확장함으로써 트래픽을 자동으로 분산시킨다.
동시에 서버간 통신은 elasticache를 이용하여 서버간 어댑터를 바인딩시킨다.
일단 위와같이 큰 틀을 두고 무엇이 더 효율적일지를 비교해보았다.
1-1 에 대한 의견
클러스터를 써서 코어를 분산시키려고해봤자 서버스펙 업그레이드 안하면 의미가 없다.
이건 결국 그냥 스케일업이다.
스케일업을 할 경우에는 추후 지속적으로 트래픽이 증가할때마다 스케일업을 해줘야하는데
그렇다면 비용이 한번 스케일업이 이루어질때마다 배로 뛰기 시작한다.
(실제로 ec2를 스펙업 하고자 확인해보면 매 단계별로 업그레이드 될때마다 2배씩 뛴다.)
2-1 에 대한 의견
스케일아웃을 할 경우에는 추후 지속적으로 트래픽이 증가할때마다 오토스케일링을 통해 자동으로
서버를 확장시킬수있고 , 줄일수도있어 필요에의해서 확장 , 축소가 가능하여 비용적인 이득이 월등하다.
또한 로드밸런서를 이용하여 트래픽분산을 시키기에도 용이하다.
2안 결정
서버비는 제한되어있고 필요에의해서만 확장 되어야하고 축소가 용이하여야한다.
지속적인 트래픽 증가시에 스펙업을 고집할경우 단계별로 비용도 2배씩 뛰는것을 확인하였고
그것보다는 스케일아웃이 더 비용측면에서 , 또한 확장 축소 측면에서도 효율적이라고 판단하여 2안으로 선택하였다.
결과적으로 각 서버마다 elasticache에 연결시켜 확장시 발생하였던 서버간 통신 불가 문제를 해결하였고 이전에 발생하던 과도한 트래픽으로인한 레이턴시증가현상은 더이상 발생하지 않게 되었다.
아싸 성공했다.
