Vanila JS로 SPA를 구현해보자.
최근 넘블이라는 IT직무 관련 챌린지 플랫폼(?) 에서 진행한 바닐라 JS로 SPA 만들기 챌린지에 참가했다.
📌 왜 참가했나?
사실 프론트엔드를 기초부터 쌓았다기보단 회사에 필요한 리액트부터 먼저 머릿속에 때려박고, 리액트를 어떻게 하면 더 잘 쓸수있을까에 고민을 했지 그 기반이 되는 JS, DOM 등에 대한 기초가 부족하다고 생각하고 있었다.
그러던 차에 이 챌린지를 발견하게 되었고, 상위 5명안에 들면 네카라쿠배 개발자한테서 코드리뷰도 받을수 있다고 하니 그동안 사수없이 개발해오던 나에게는 이보다 좋은 기회가 없다고 생각했다. (물론 TOP5에 선정되어야 하지만...🙏)
게다가 NCP 크레딧도 받을수 있다고 하니, 이번에 학교 복학하면서 왠지 NCP같은거 많이 쓸것 같다는 생각이 들어서 일석이조라고 생각했다.
📌 챌린지 요구사항
단도직입적으로 결과 페이지부터 보여주자면 아래와 같이 CRUD를 할 수 있는 블로그형 서비스를 만들어야 했다.
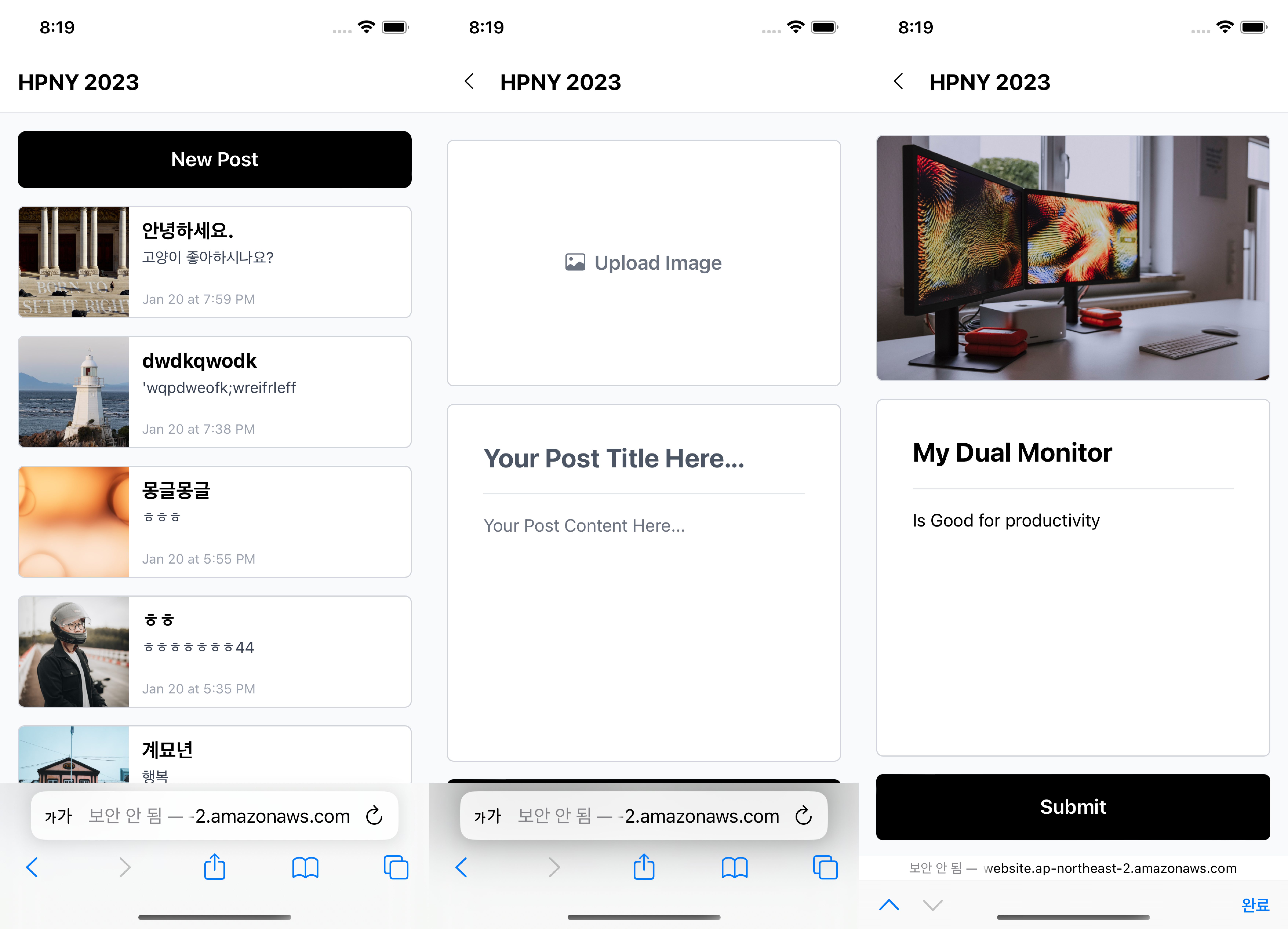
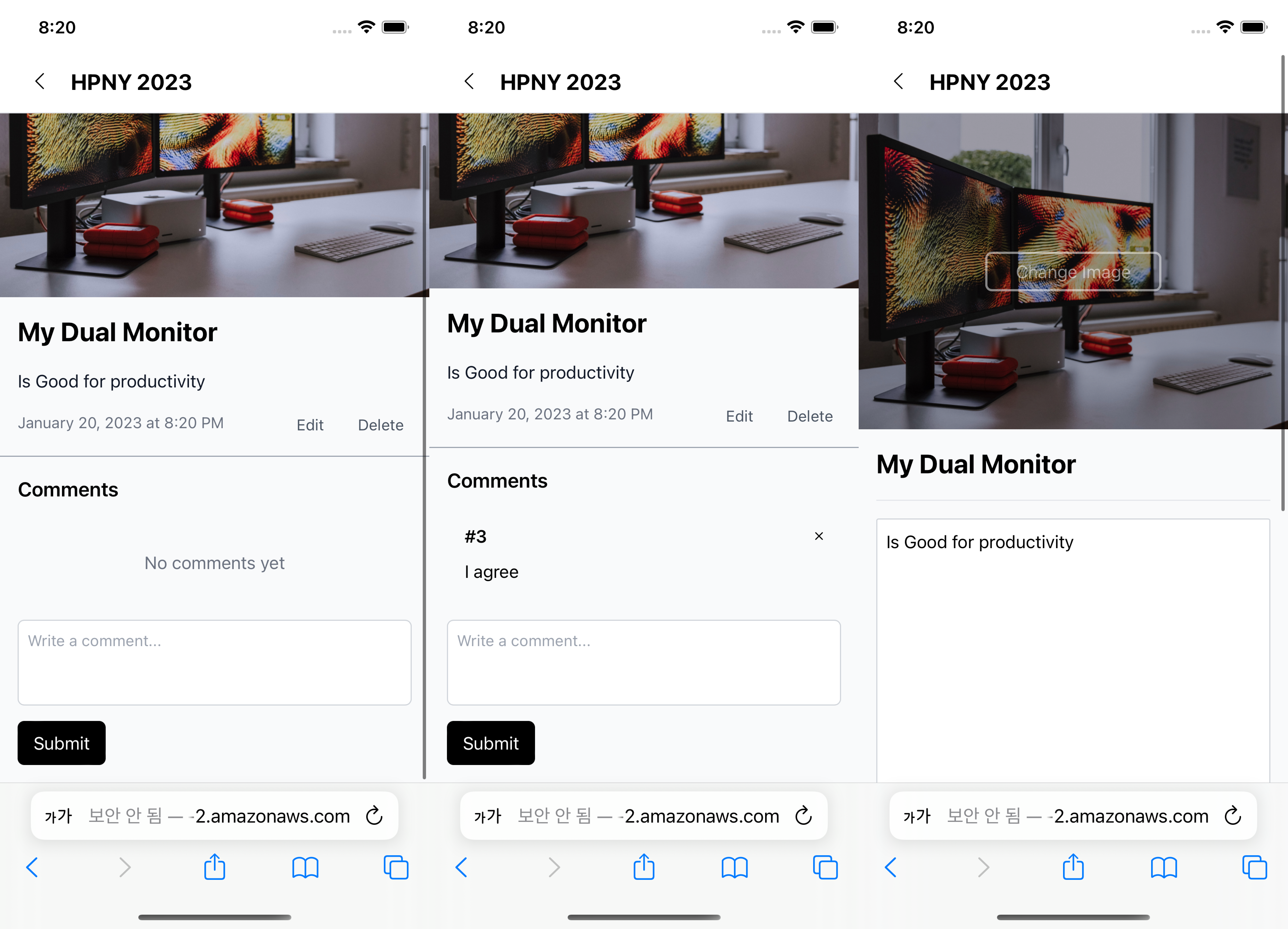
API의 경우에는 챌린지 호스트님이 준비를 해 주셨고, 챌린저들은 2주동안 bundler 및 CSS 전처리기, axios 를 제외하고는 모두 vanila를 이용해서 위 기능들을 갖춘 SPA를 만들어야 했다.
📌 얻어간 경험
Web Components API 이용
내가 과연 Vanila로 리액트와 같은 사용성을 가진 SPA를 만들수 있을까? 하는 생각이 들었다.
그러던 와중 예전에 Web Components 라는 것에 대해 들어봤던 기억이 나서 찾아봤다.
Web Components는 2010년대 초반에 재사용 가능한 컴포넌트 등을 지원하기 위해서 브라우저에서 네이티브로 지원하는 커스텀 엘레먼트를 만들수 있게 해준 기능이다.
사실상 리액트에서 <Header/> 라는 커스텀 컴포넌트를 만드는것을 브라우저 단에서 바로 만들수 있게 해준것.
그래서 나는 실험적으로 header 컴포넌트에 이를 적용해 봤다.
class Header extends HTMLElement {
constructor() {
super();
}
static get observedAttributes() {
return ["type"];
}
mainTemlate = `
<header class="flex fixed z-20 bg-white top-0 items-center justify-start w-full gap-2 px-4 border-b border-gray-200 h-14 max-w-[640px]">
<h1 role="link" tabindex="0" class="font-bold text-xl">HPNY 2023</h1>
<div class="flex-1"></div>
</header>
`;
subTemplate = `
<header class="flex fixed z-20 bg-white top-0 items-center justify-start w-full gap-2 px-4 border-b border-gray-200 h-14 max-w-[640px]">
<button id="back-button" class="w-10 h-10">
<i class="bi bi-chevron-left text-lg"></i>
</button>
<h1 role="link" tabindex="0" class="font-bold text-xl">HPNY 2023</h1>
<div class="flex-1"></div>
</header>
`;
placeholderTemplate = `
<div class="h-14 w-full bg-gray-50"></div>
`;
render(el) {
const headerType = el.getAttribute("type");
const $fragment = document.createDocumentFragment();
switch (headerType) {
case "main": {
const $header = parseElementFromString(this.mainTemlate);
...
$fragment.append($header);
break;
}
case "sub": {
const $header = parseElementFromString(this.subTemplate);
...
$fragment.append($header);
break;
}
}
$fragment.append(parseElementFromString(this.placeholderTemplate));
el.append($fragment);
}
/**
* 이 컴포넌트의 속성이 변경될 때 호출됩니다.
* @param {*} name
* @param {*} oldValue
* @param {*} newValue
*/
attributeChangedCallback(name, oldValue, newValue) {
this.render(this);
}
}
export default Header;많은 부분이 생략되었는데, 이런 느낌으로 짜면 <app-header></app-header/> 이라는 커스텀 태그로 사용할 수 있고, <app-header type="main"></app-header/> 와 같이 리액트에서 쓰듯이 prop도 넘길 수 있었다.
그럼에도 불구하고 웹 컴포넌트는 헤더 컴포넌트에서만 사용했는데, 그 이유는 뭔가 생각보다 많이 불편했던 것이다.
리액트에서 쓰듯이 함수도 prop으로 넘기고 싶었지만 아무래도 html tag로 등록해서 쓰는것이다보니 그런 기능은 지원하지 않았다.
또 <app-header> 라는 커스텀 엘리먼트는 스타일링이 안되는데 display:block으로 해석되어서 내부 엘리먼트들의 스타일링에도 제약이 있었다.
이러한 이유로 웹 컴포넌트는 헤더에만 실험적으로 사용하게 되었다.
Client-side Router의 원리 이해
SPA를 밑바닥부터 구현하라니. 뭔가 하나도 감이 안와서 막막했다. 예전에 프로그래머스 고양이 사진첩 챌린지에서 처참하게 당했던 기억이 살아났달까..!
하지만 이번엔 나에겐 강력한 동료, ChatGPT가 있었다. ChatGPT에게 물어봤다.
"웹 컴포넌트와 자바스크립트로 SPA를 어떻게 만들어야 할까?"
그러자 아래와 같은 라우터 코드를 알려줬다.
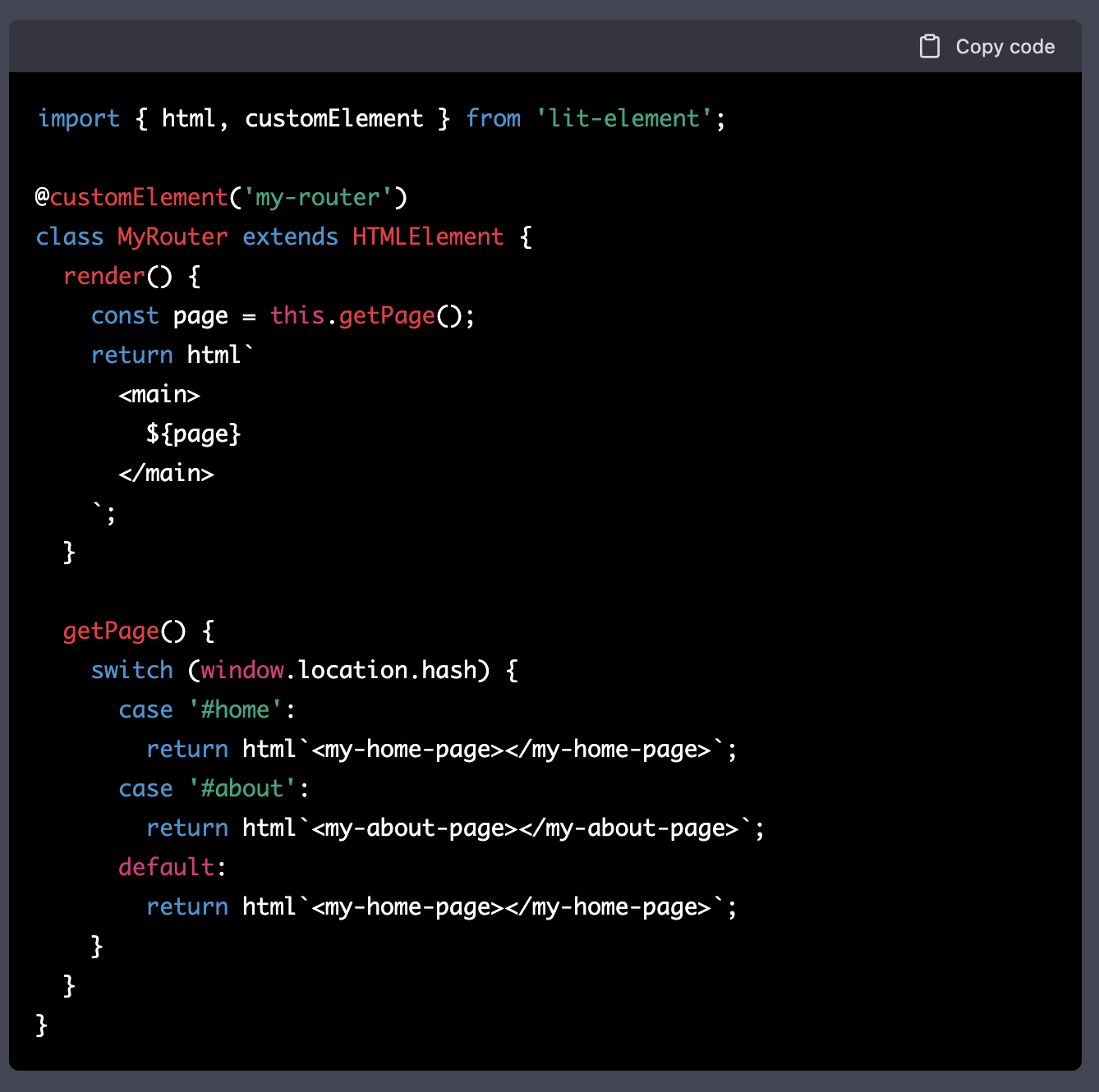
이 예시가 웹 컴포넌트 예시라서 생소할 수 있지만, 라우터 구현부터 시작해야 하구나 라는걸 알 수 있었다.
기존에 SPA 구현은 Client-side 라우팅을 사용해야 한다는 것은 알고 있었는데, 실제로 어떻게 해야 할지 감이 좀 안와서 poeimaweb의 SPA 관련 글을 찾아보았다.
여기에 모든 라우팅 방식이 너무 잘 정리되어 있어서, 여기를 참고해서 pjax 방식으로 구현했다.
세부 인터페이스는 리액트 쓰면서 너무 잘 썼던 react-router의 인터페이스를 따랐는데,
react-router의 컨셉 문서가 너무 잘 정리되어 있어서 보면서 라우터 구현에 대해 깊이있게 알 수 있었다.
XSS 문제 발견
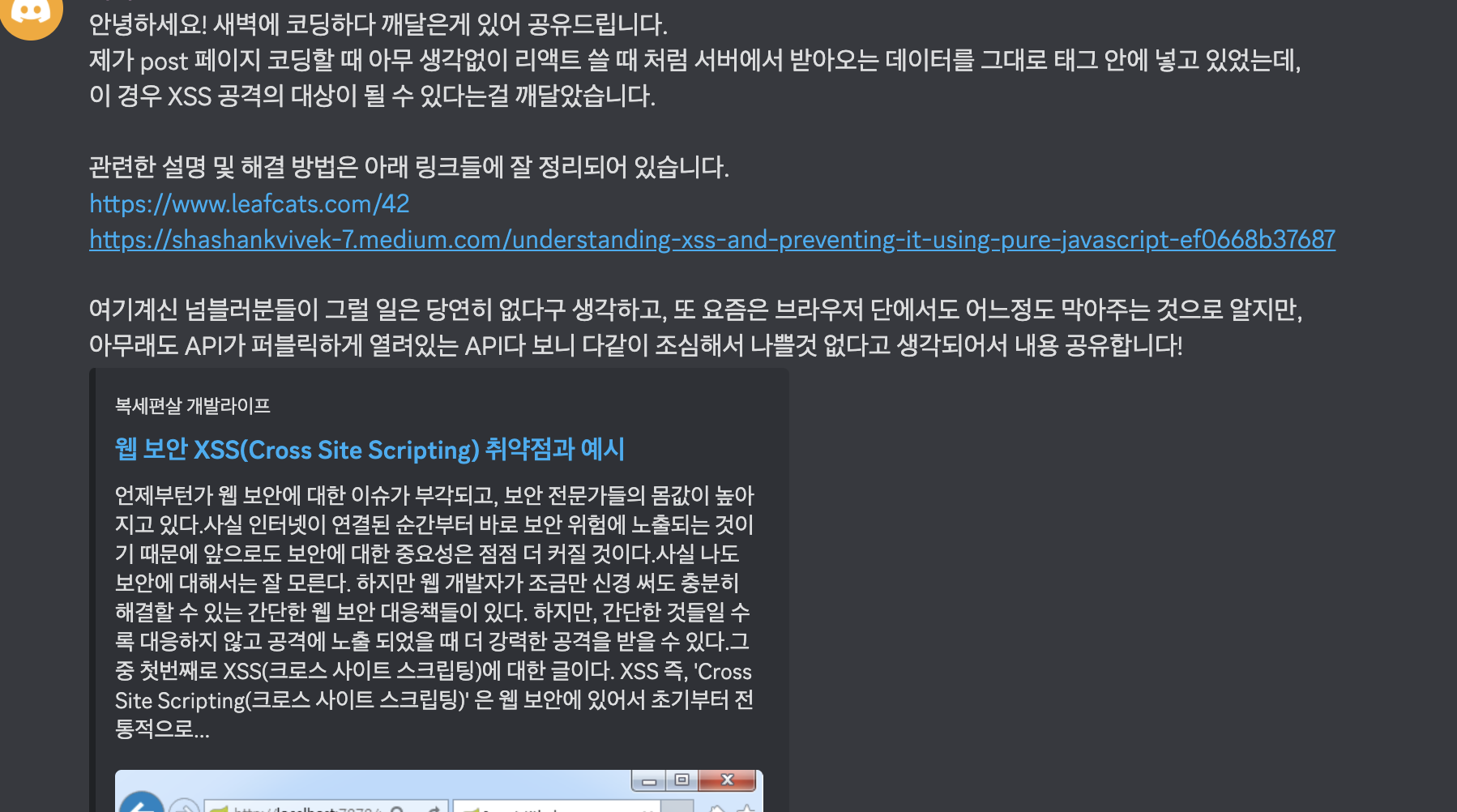
챌린지를 진행하면서 많은 사람들이 innerHTML을 많이 사용했던 것 같은데, 중간에 엄청난 사실을 깨달았다.
발단은 API 엔드포인트를 동일한 엔드포인트를 쓰다 보니 다른 사람이 작성한 글이 내 화면에도 보이는데, 화면 레이아웃이 깨지는 것이었다.
분명히 나는 레이아웃을 신경을 썼는데, 왜 깨지나 하고 봤더니 다른 사람이 자기 글 텍스트에 <p>이것도 되나</p> 이렇게 작성한 것이었다.
여기서 심장이 철렁했다. 예전에 지나가다 배운 XSS 공격이 멀리 있지 않고 여기 있었구나. 누군가 한명이라도 나쁜 마음을 먹었다면 이미 내 PC는 해킹당했겠구나 생각했다.
그래서 바로 XSS를 막기 위한 방법들을 찾았고, 나의 경우는 String Prototype에 태그 관련 문자열을 HTML 특수문자로 변환해주는 String.prototype.escape() 함수를 정의하는 것이었다.
아무 생각없이 리액트만 썼다면 언젠가 겪었을지도 모를 문제를 미리 겪어보고, 해결해볼 수 있어서 좋았었던 것 같다.
Webpack 구성
이번 챌린지를 하면서 목표로 삼았던 것 중에 하나가 기존에 바쁘다는 핑계로 대충 넘어갔던 번들러에 대한 지식을 쌓는 것이었다.
그래서 일부러 vite 대신 많은 부분을 직접 해야하는 webpack으로 프로젝트를 번들링 설정했다.
dev-server, postcss, dotenv-webpack 등 다양한 plugin들을 필요에 따라 직접 webpack에 설치해서 사용해 보면서 좀 더 번들러의 역할에 대해서 이해하게 되었고, 또 내가 짠 코드가 어떻게 번들링되는지 직접 비교해 보면서 번들러의 번들링 결과에 대해서 훨씬 자세히 이해할 수 있어서 좋았다.
렌더링 최적화를 어느 정도 이해한 것
Vanila JS로 렌더링을 시키려면 직접 DOM을 조작해야 하는데, DOM을 조작하는 다양한 함수 중 어떤 것을 어떻게 사용해야 하는지 막막했다.
처음엔 편하다는 목적으로 innerHTML만 썼는데, 과연 이게 맞는 방법인지에 대한 의구심이 들었다. appendChild, insertAdjacentHTML 이랑 어떤 차이가 있는거지?
이런 부분에 대해서 주말에 있었던 위클리 스크럼에서 팀원들과 이 방법에 대해서 같이 고민을 해 볼 수 있어서 좋았던 것 같다.
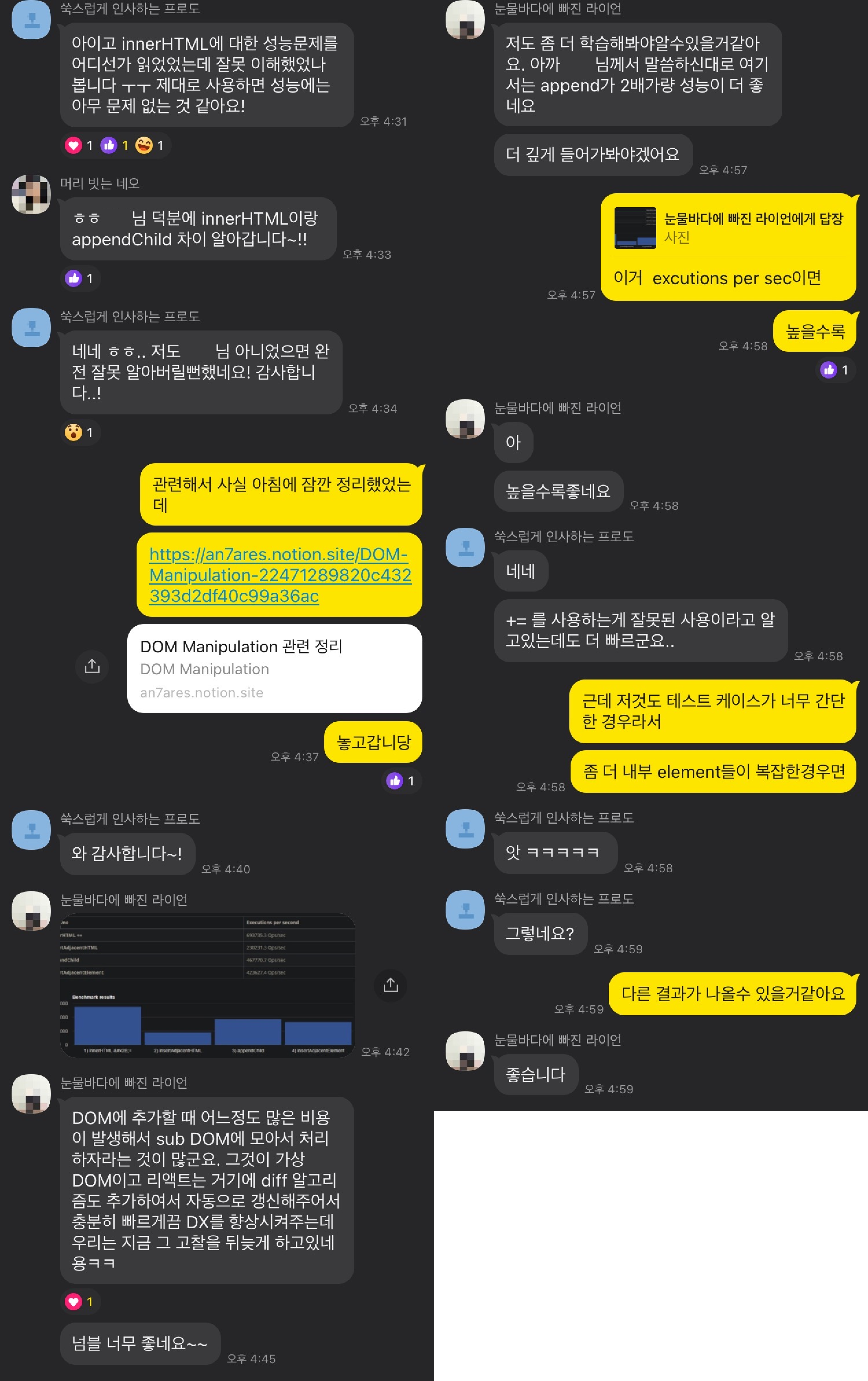
물론 지금 보면 약간 잘못된 고찰 (virtual DOM 에 대한 부분) 도 있는 것 같지만 이런 의견들을 서로 나눌수 있는 팀원들이 있었다는게 참 좋았다.
결론적으로 나는 DOM 파싱 시간보다 Reflow, Repaint 횟수를 줄이는 것에 집중했고,
이를 위해 DOMParser나 DocumentFragment 등을 적극적으로 활용해서 Reflow, Repaint횟수를 최소화시키는 방향으로 코드를 작성했다.
lexical Environment, Browser의 GC에 대한 이해
많은 분들이 이번 챌린지를 진행하면서 class를 이용해서 코드를 작성하신 것을 보았다.
아마 황준일 개발자님의 블로그 영향이 아닐까 싶은데,
그걸 보고 내 힙스터병이 발동해버렸다.
남들이 다 class로 짜니깐 나는 함수형으로 짤래!
최근에 테오님이 쓴 함수형 프로그래밍에 관한 글을 보고 나서 함수형 뽕이 들어차버렸기 때문에, 누구도 날 말릴 수 없었다.
하지만 한가지 걱정이 들었다.
컴포넌트를 함수형으로 작성했다고 치자. 컴포넌트의 내부 상태는 함수 내부에 정의된 state에 의존하고 있을 텐데, 그러면 함수가 실행되어서 컴포넌트가 렌더링 된 이후에 함수 내부에 정의된 state가 GC되어서 파괴되면 어떡하지?
그래서 브라우저에서는 어떻게 메모리를 관리하는지에 대해서 찾아봤다.
해당 문서에서 보면 현대 브라우저는 Mark-and-Sweep 알고리즘을 이용해 root 객체에서 닿을수 없는 객체들에 대해서만 가비지 콜렉션을 수행한다고 한다. 따라서 우리의 state가 root에서 닿을수 있는지 여부만 확인하면 된다.
생각을 해 보면, 페이지나 컴포넌트들에 등록해둔 eventListner들이 state를 참조하고 있기 때문에 해당 state들은 삭제되지 않을 것 같았다.
이를 좀 더 명확한 개념으로 이해하고 싶어서 오랜만에 Javascript Deep Dive를 폈고, 거기에서
함수가 실행될 때의 실행 컨텍스트 는 사라질 수 있어도 함수의 결과로 나온 값들이 함수 내부의 변수들을 참조하고 있다면 그 렉시컬 환경은 참조되고 있으므로 사라지지 않는다(GC되지 않는다) 라는 걸 알 수 있었다.
그렇게 해서 함수로 코드를 작성해도 문제가 없겠다 라는 판단 하에 안정적인 마음으로 코드를 짤 수 있었다!
📌 아쉬웠던 점
팀원 동기부여 및 코드리뷰
생각보다 2주란 시간이 짧아서(특히 이것만 집중하는게 아니라 다른 것까지 병행하니..) 모든 팀원들이 플젝을 마무리하지 못한 점이 아쉬웠다. 뭔가 으쌰으쌰하면서 서로 코드리뷰도 하고 그랬으면 좋았겠다 싶은데 그러지 못한점이 마음에 걸린다.
상태 관리 및 Data Caching
상태 관리를 페이지 컴포넌트에서만 대충 state를 구현해두는 식으로 썼는데, 뭔가 더 깔끔하게 상태를 구독하고, 그 상태에 따라서 render가 일어나도록 하고 싶었는데 그걸 못한게 아쉽다.
또 서버 측 데이터를 캐싱하는 것도 구현하면 좋았을 것 같은데 시도하지 못해본게 아쉽다.
NCP 활용
원래는 이미지 업로드 방면에서 NCP를 이용하려 했다. 하지만 생각해 보니 NCP를 이용하려면 SECRET KEY가 있어야 하는데 이게 브라우저 환경이면 어쩔수 없이 노출될 것 같아서 문제의 소지가 있어 활용하지 못했다.
AWS는 incognito를 이용해서 어떻게 브라우저에서 S3로 올릴수 있는 것 같던데 거기까지는 하지 못했다.
하지만 이번 기회로 NCP를 이것 저것 찾아봤는데, 꽤 쓸만한 기능들이 많더라. 예를 들어 Object Storage → Image Optimizer → CDN+ 도 생각보다 쉽게쉽게 할 수 있도록 다 되어 있었다.
또 aws-sdk의 엔드포인트를 Object Storage로 지정하면 S3 쓰듯이 사용할 수 있도록 인터페이스를 통일해준 점 등이 좋은 것 같다. 보통 스타트업들 보면 초반에는 아무래도 AWS 크레딧을 많이 주다보니 AWS를 많이 이용하는데, 나중에 데이터 국외 이전 등의 이슈로 NCP로 이전하는 과정에서 이런 배려 하나하나가 도움이 되지 않을까 싶다.
📌총평
생각보다 1월이 바빠서 많은 시간을 투자하진 못했지만, 그럼에도 굉장히 많은 걸 배울 수 있던 기회였다고 생각한다. 좀 더 내가 살아가는 생태계의 기반에 대해서 이해할 수 있는 시간이었다.
설엔 좀 쉬어야겠다!
