복습
- CREATE DATABASE
CREATE DATABASE database명; - CREATE TABLE
CREATE TABLE table명 (column명1 자료형1, ..., column명n 자료형n); - INSERT INTO ... VALUES
INSERT INTO table명 VALUES(data1, ..., datan); - SELECT ... FROM ... (ORDER BY ... 조건)
SELECT column명n FROM table명 ORDER BY column명n 조건;
SELECT * FROM table명 ORDER BY column명n ASC;
ASC DESC , ORDER BY column명1, column명2
SELECT date, name FROM develop_book
ORDER BY 1,2;
SELECT date, name FROM develop_book
ORDER BY 2,1;- AS
SELECT orig column명 AS new column명 table명 - database 백업 AS
CREATE TABLE develop_book_2 AS
SELECT*FROM develop_book
ORDER BY book_id ASC;
데이터 베이스를 백업하였다.- DROP
DROP TABLE table명 - RENAME
ALTER TABLE develop_book_2
RENAME TO develop_book;
develop_book_2를 develop_book으로 수정한다.
데이터 테이블 까지 확인해본다.- DELETE
DELETE FROM 테이블명 WHERE 컬럼명 = 삭제할 데이터의 컬럼 값;
DELETE FROM developbook WHERE book_id = 6;
※ 삭제할 데이터의 컬럼 값을 안넣으면!! 모두 지워진다.
DELETE FROM 테이블명; 으로 끝내면 테이블에 있는 모든 데이터가 삭제된다.
실습위해 다시한번 백업을 만들고 develop_book_2를 지워보았다.- CAST 자료형 변환
data 타입을 변환해준다.(자료형 변환)
SELECT CAST('3000' AS INTEGER); == SELECT '3000'::INTEGER; // 등호를 기준으로 양쪽 문법은 동일한 기능을 가진다.- LIKE
조회할 컬럼명 LIKE '패턴';
특정 값 LIKE '패턴';
패턴?
% -> 모든 문자열
_ -> 문자열 하나
WHERE phone LIKE 'iphone';
'pink' LIKE '_in_, _에 a~z까지 조회후 -> true로 리턴
'pink' LIKE 'p%k', %에 a~z까지의 문자열 조합 조회후 -> true로 리턴
'pink' LIKE 'p__' 글자수가 안맞네 -> false로 리턴DATA TYPE
숫자형
INTEGER
나타낼 수 있는 수의 법위와 저장용량 사이의 밸런스가 적절함 일반적으로 많이 씀, 숫자 길이 제한 불가.
NUMERIC(p,q)
소수점 자리 표시 가능, p=전체 자릿수, q=소수점 자릿수
예) numeric(6) 면 6자리 숫자만 입력 가능 100,000
FLOAT
부동소수점을 사용, REAL 또는 DOUBLE PRECISION으로 인식
SERIAL
INTEGER기본 값으로 1씩 추가되며
문자형
VARCHAR(n)
CHAR(n)
TEXT
날짜 및 시간
TIMESTAMP
2020-01-09 19:00:00.000
TIMESTAMPTZ(TZ : TIME ZONE)
2020-01-09 19:00:00.000(GMT +9)
DATE
2020-01-09
TIME
19:00:00
TIME WITH TIME ZONE
19:00:00.000(GMT +9)
불리언형(bool,boolen)
TRUE
true, yes, on, 1
FALSE
false, no, off, 0
Null
알 수 없는 정보 또는 일부 불확실
2021-12-02 연산자 이어서 복습
CASE 함수 p.162
SQL에서 사용하는 가장 기본적인 조건문 함수로, 이 함수를 사용하여 컬럼에 특정한 조건을 부여할 수 있다. 특히 다른 프로그래밍 언어에서 IF-ELSE문과 대응되는 것으로, 우선 그 구조를 살펴보면 CASE로 시작하여 END로 끝나는 다음과 같은 형태를 갖는다.
SELECT * FROM student_score;
CASE
WHEN <조건문1> THEN <결과문1
WHEN <조건문1> THEN <결과문2
ELSE <결과문3>
END
SELECT id, name, score,
CASE
WHEN score <= 100 AND score >= 90 THEN 'A'
WHEN score <= 89 AND score >= 80 THEN 'B'
WHEN score <= 79 AND score >= 70 THEN 'C'
WHEN score < 70 THEN 'F'
END grade
FROM student_score;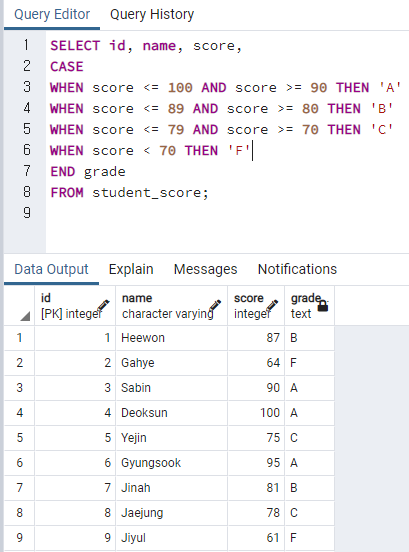
수업
연산자
배열 연산
p.172
SELECT ARRAY[5.1,1.6,3]::INTEGER[] = ARRAY[5,2,3] AS result;
SELECT ARRAY[5,3,3] > ARRAY[5,2,4] AS result;
포함관계, 겹침관계를 확인후 boolen으로 리턴.
배열끼리 병합, 2차원 배열로 병합, 원소 배열 병합
JSON 연산
p.175
'{"키 값1": "밸류 값1", "키 값2": "밸류 값2"}' -> "키 값1"
SELECT '{"p":{"1":"postgres"},"s":{"1":"sql"}}'::json -> 'p' AS result;
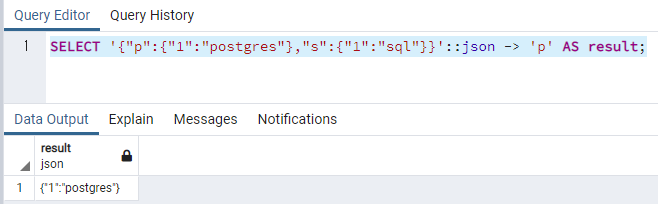
키값1에 접근하면 밸류값1이 나온다?!
데이터의 집계 및 결합
p.213 방식대로 할 수도 있고, p.152쪽 방식으로 할 수도 있다.(createdb -U postgres union_example;를 cmd에서 사용)
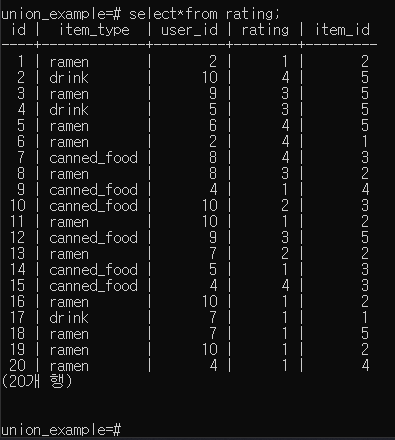
데이터 집계
- createdb 명령어는 user 위치에서 해도 되고 psql위치에서 해도 된다.
다만 경로 설정할때는 psql밖에서 해야 한다.
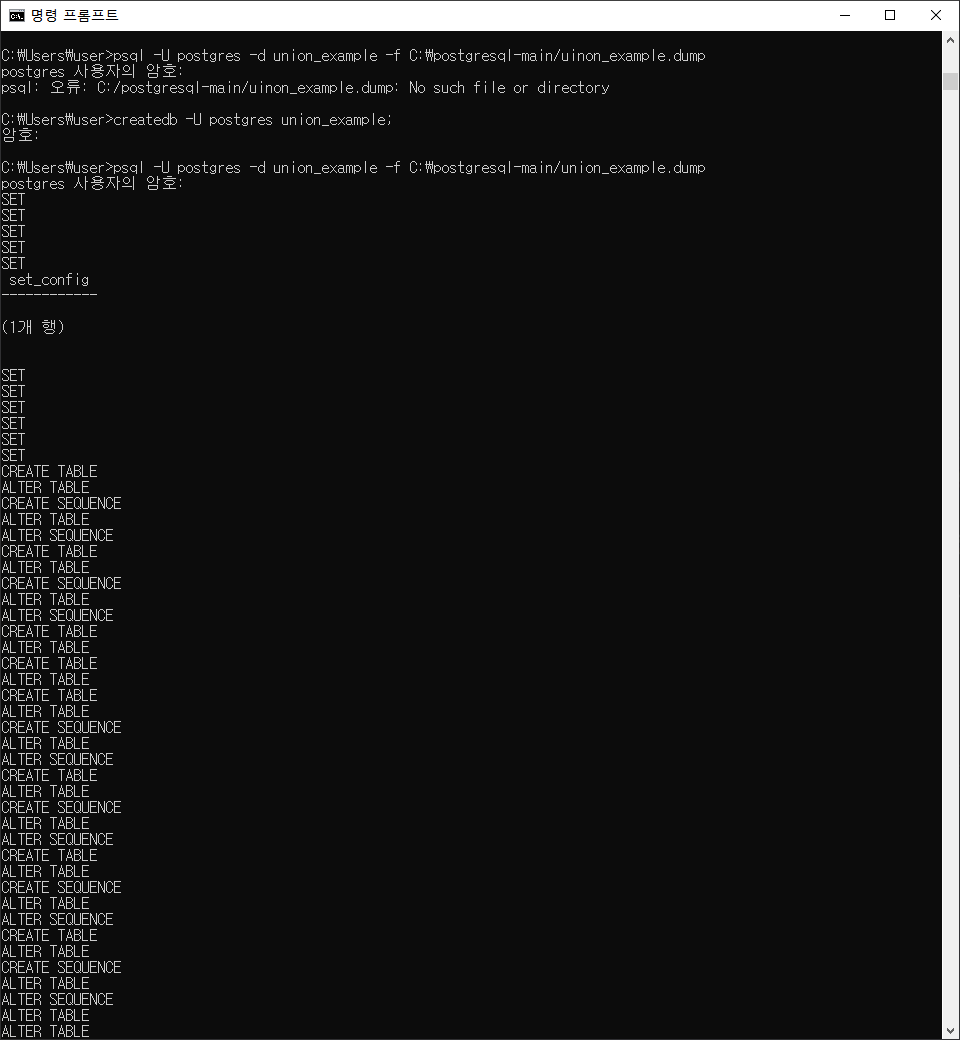
아래와 같이 table확인이 가능하다.
GROUP BY p.216
기준을 가지고 그룹으로 묶을 때, 사용
원하는 자료를 그룹화하는 방법
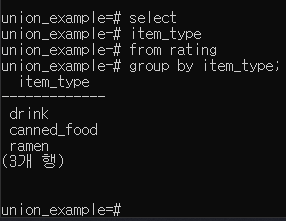
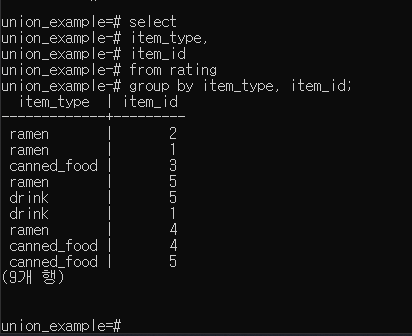
Group by 뒤에있는 컬럼을 중복 제거하고 보여준다.
select 절과 group by 절에는 항상 같은 칼럼을 적어야 한다.
select에 group by 관련 함수를 추가할 수 있다.
※group by와 distinct의 다른점 :
집계 함수 사용 가능
집계 연산 후 having사용 가능
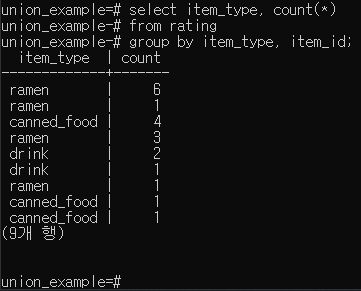
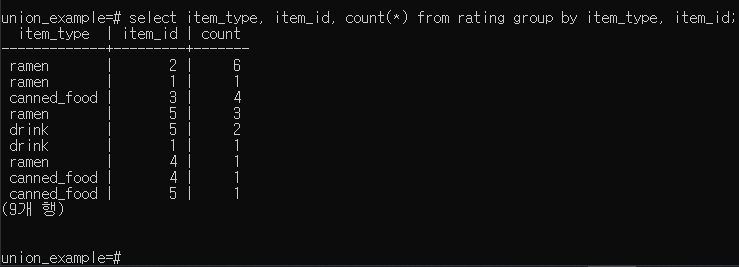
HAVING
집계데이터를 조건으로 검색하고 싶을 경우
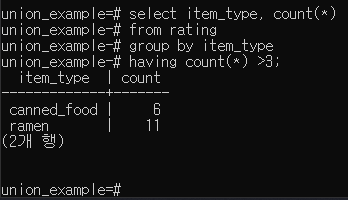
UNION p.216,p.252
분산되어 있는 테이블을 합칠 때, 사용
※ 테이블 끼리 컬럼명이 같아야함
두개의 쿼리문으로 하나의 테이블을 만드는 명령어
1. 두 sql은 서로 컬럼의 개수가 동일 해야함.
2. 같은 위치에는 동일한 형식과 의미의 데이터가 담겨야 함
JOIN p.217, p.264
정규화된 테이블을 합쳐서 봐야 할 때,
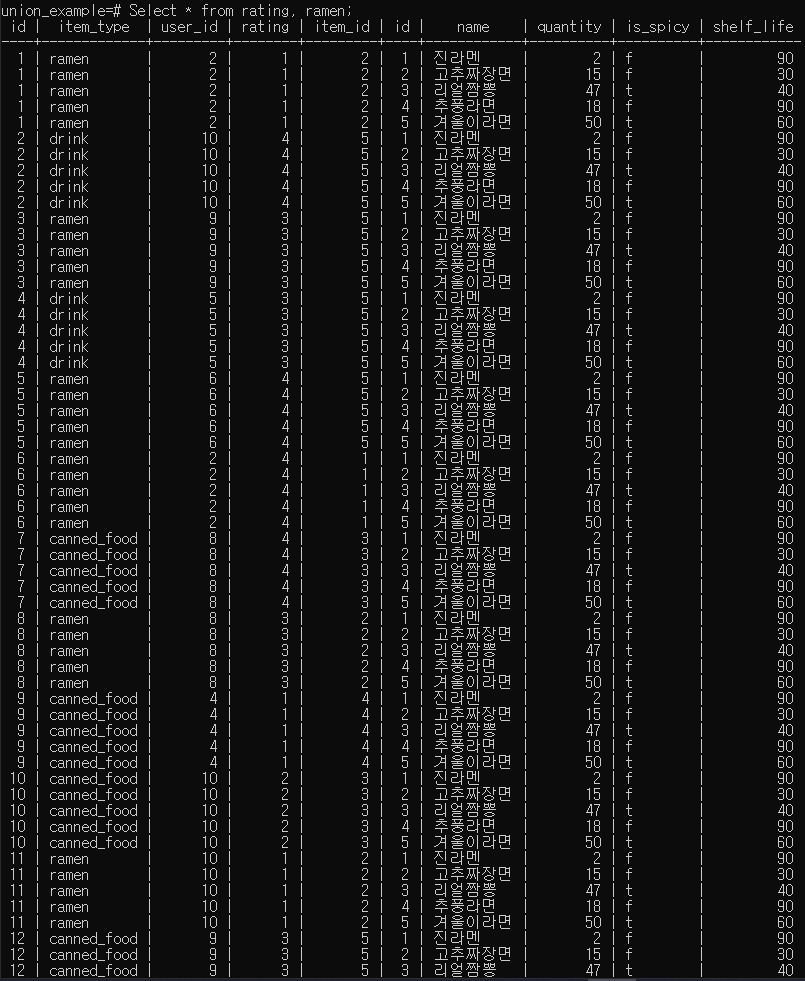
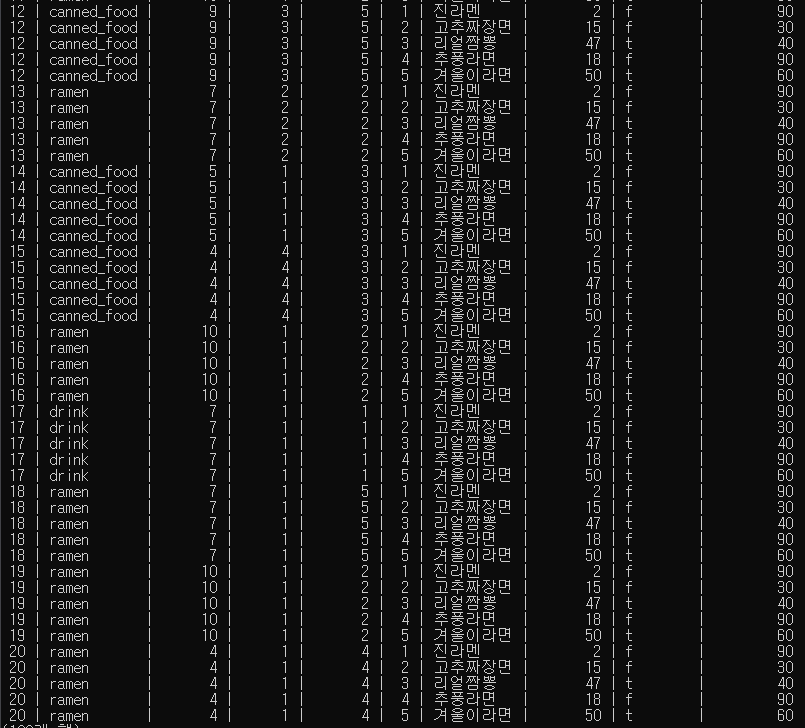
아래 두 방식 모두 같은 내부 동작을 수행
가독성이 좋기 때문에 JOIN 선호
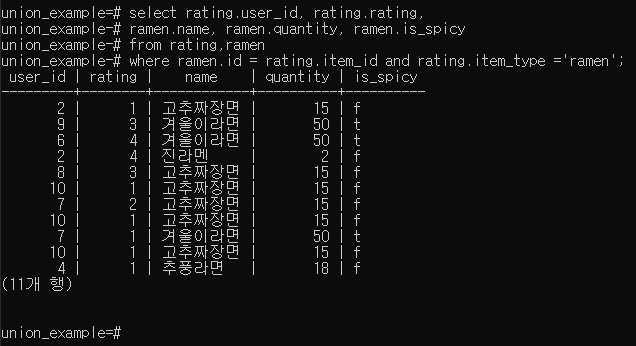
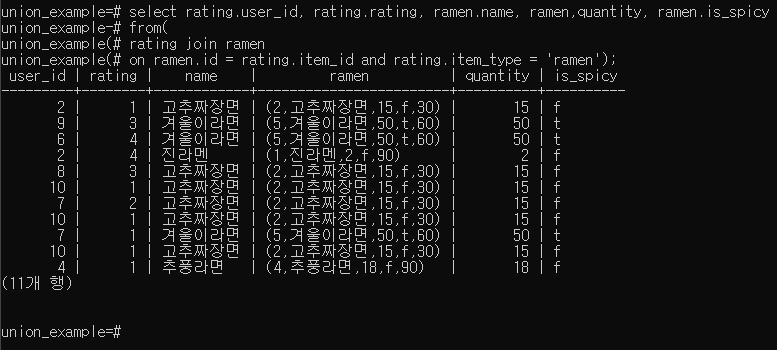
나중에 서브쿼리(괄호 빼고 해보자!!!)
- JOIN 내부 외부
| 명령어 | 축약형 | 내부/외부 구분 |
|---|---|---|
| INNER JOIN | JOIN | 내부 |
| LEFT JOIN | LEFT JOIN | 외부 |
| RIGHT JOIN | RIGHT JOIN | 외부 |
| FULL JOIN | FULL JOIN | 외부 |

Test용이하게 pgadmin으로 넘어왔다!
아래 내용이 INNER JOIN이다. 공통 부분이 있는 컬럼만 나온다.
inner join right_table
on left_table.id = right_table.id;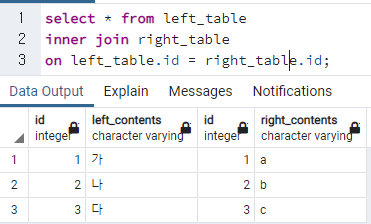
아래는 LEFT JOIN을 사용하였으며, 왼쪽의 모든 컬럼을 출력하는 기준으로 한다.
LEFT join right_table
on left_table.id = right_table.id;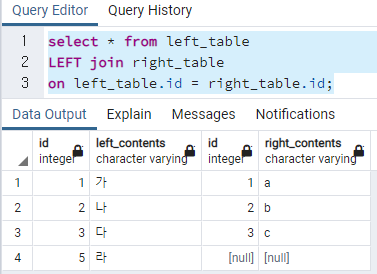
- USING p.275
DISTINCT p.217
테이블에서 중복된 부분을 제거할 때, 사용 여러 칼럼에 동시 적용 가능
SQL 우선순위
| 명령어 | 우선순위 |
|---|---|
| FROM | 1 |
| WHERE | 2 |
| GROUP | 3 |
| HAVING | 4 |
| SELECT | 5 |
| DISTINCT | 6 |
| ORDER BY | 7 |
| LIMIT | 8 |
- 우선순위 예시
| ┏ | ← | SELECT item_type, count(*) | ←┐ |
| ↓ | ↑ | ||
| ↓ | ┏ | (시작)FROM rating | ↑ |
| ↓ | ↓ | WHERE item_type LIKE 'r&' | ↑ |
| ↓ | ↓ | GROUP BY item_type | ↑ |
| ↓ | └ | HAVING count(*) >3 | ┘ |
| ↓ | |||
| └→ | ↓ | ORDER BY item_type; | |
| └→ | LIMIT 0; |
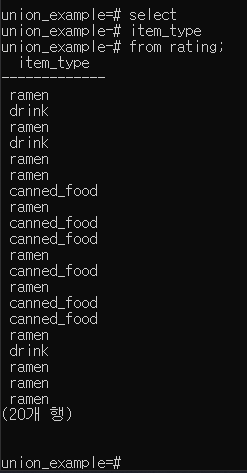
집계 함수 p.227
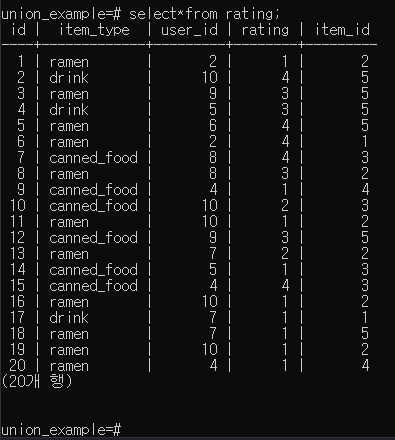
select * from rating;
select count(rating) from rating where item_id =2;
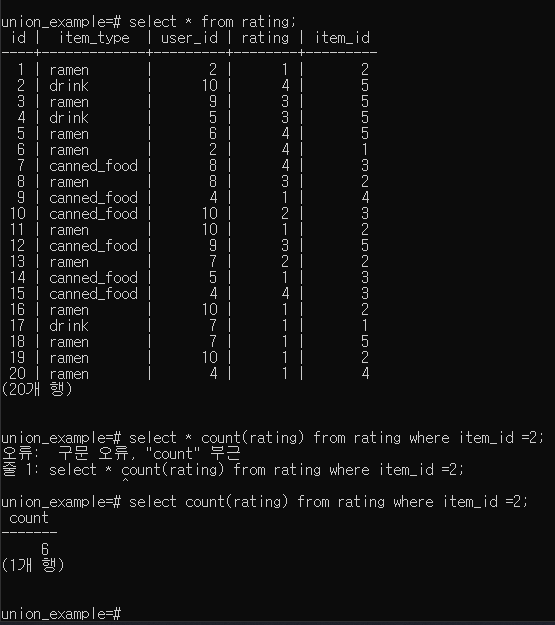
- rating 값이 가증 큰 item_type, itme_id 칼럼 조회
서브 쿼리 형식으로 사용해야함
불리언 연산 집계함수
INTERSECT
명령어는 두 테이블에 공통되는 로우(레코드)만 남김
EXCEPT
두 테이블에 중복되지 않는 로우(레코드)만 남김
데이터 결합 실습 p.283

1. 전국의 인구수 총합을 연도별로 표시하라!
select population_by_year.년도, sum(population_by_year.총인구수)
from population_by_year
group by population_by_year.년도
order by population_by_year.년도;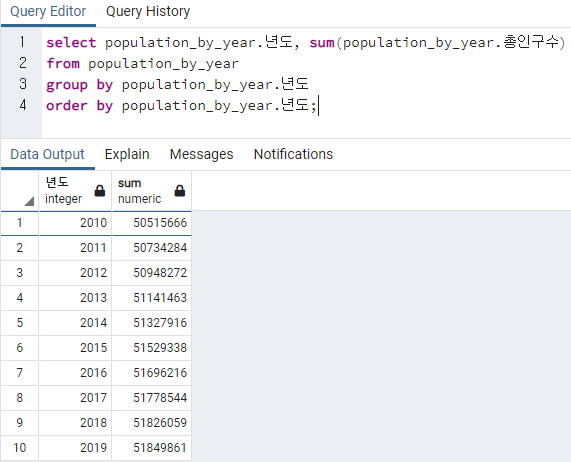
- 최근 5년간 전국의 한 세대당 평균 인구수(총인구수/세대수)를 출력하라. 매연도마다 세대당 평군
데이터 모델링 p.345
데이터 모델링이란? 저장할 데이터 구조를 정하는 작업
예시
커뮤니티 서비스 기획 내용
1. 사용자는 이름과 생년월일, 그리고 점수를 가진다.
2. 게시판은 이름을 가진다.
3. 게시글은 사용자가 게시판에 작성 가능하고, 제목과 내용 조회수를 표시한다.
4. 조회수는 사용자당 1씩만 올릴 수 있고, 다시 게시글을 읽어도 조회수가 오르지 않는다.
정규화 비정규화 란?
정규화
장점
비정규화
실습.정규화vs비정규화
커피 테이블
id, 커피이름, 가격
단골 테이블
id, 구매자 이름, 구매자 성별
구매 내역 테이블
id, 커피id, 구매자id, 일시
create table coffee
(
id integer primary key,
co_name varchar,
price money
);
create table dangol
(
id integer primary key,
cust_name varchar,
cust_sex varchar
);
create table pay_info
(
id integer primary key,
co_id integer references coffee(id),
cust_id integer references dangol(id),
date date
);insert into coffee values
(1, '아메리카노', 3000),
(2, '에스프레소', 4500),
(3, '카푸치노', 4000);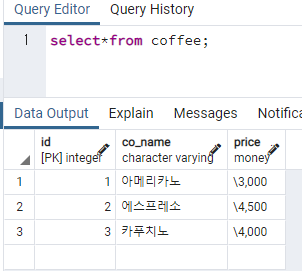
insert into dangol values
(1,'홍길동','남'),
(2,'길상인','남'),
(3,'차숙자','여');
select*from dangol;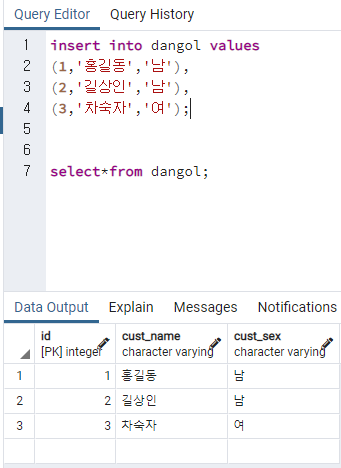
insert into pay_info values
(1,1,1,'2021-07-12'),
(2,2,2,'2021-07-13'),
(3,1,3,'2021-07-14'),
(4,3,1,'2021-07-15'),
(5,2,2,'2021-07-16'),
(6,3,3,'2021-07-17');
select*from pay_info;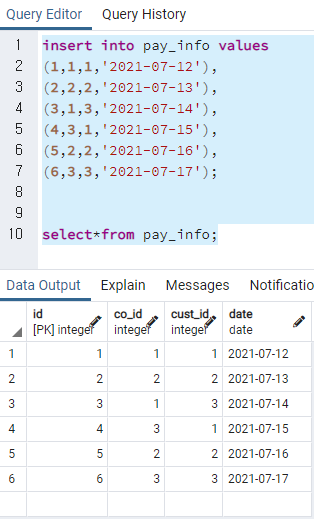
다른 기술들
책 여기저기에 있으니 관심있으면 찾아본다.

이중 책의 9장에 포함되는 TRANSACTION 기능은 자습하자.
