
Collections
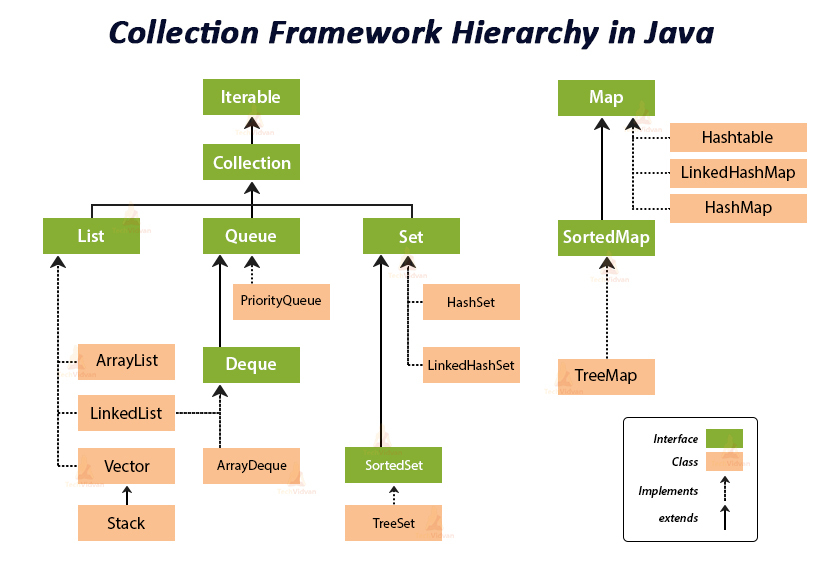
Collection은 객체에 데이터를 담을 수 있는 자료구조를 모아 놓은 인터페이스이다. 흔히 우리가 아는 List, Queue, Set 같은 형태가 인터페이스로 제공된다.
- Collection : 가장 상위 인터페이스
- Set : 중복을 허용하지 않는 집합을 처리하기 위한 인터페이스
- Sorted Set : 오름차순을 갖는 Set 인터페이스
- List : 순서가 있는 집합을 처리하기 위한 인터페이스
중복 허용, 인덱스 가능 - Queue : 여러 개의 객체를 처리하기 전에 담아서 처리를 위한 인터페이스
- Map : 키, 값으로 구성된 객체의 집합을 처리하기 위한 인터페이스
키 중복 불가능 - Sorted Map : 키를 오름차순으로 정렬하는 Map 인터페이스
사실 Set, List, Map의 자료구조에 대해서는 다들 익숙할 거다. 이를 기반으로 구현된 다양한 클래스가 자바에 존재 하지만, 이 포스팅에서는 이에 대한 개념을 주로 살피는 것보단, 어떤 클래스가 어떤 상황에서 어떤 퍼포먼스를 내는지를 우선적으로 살펴 볼 것이다.
Set
HashSet, LinkedHashSet, TreeSet을 비교할 것이다.
이름에서 알 수 있듯이 Hash가 들어간 것은 해시 테이블을 사용했고,
TreeSet은 red-black 트리를 사용하였다.
책에서 세 가지 클래스를 대상으로 여러 테스트를 진행하였다.
모든 조건은 1000개의 데이터이다.
Add
| 대상 | 평균 응답 시간(ms) |
|---|---|
| HashSet | 375 |
| LinkedHashSet | 378 |
| TreeSet | 1,249 |
해시 테이블을 사용한 Set에 비해 Tree를 사용한 것이 느림을 볼 수 있다.
이는 TreeSet의 경우 값에 따라 정렬하며 집어넣기 때문이다.
또한 데이터의 크기를 미리 알고 있다면, Set을 초기화 할 때 크기를 미리 설정하면, 성능에 이점을 얻을 수 있다.
Search
이번엔 데이터 조회를 비교했다. 순차적으로 데이터를 조회할 경우는 TreeSet도 다른 두 클래스에 비해 크게 느리지 않지만, Random하게 데이터를 조회할 경우 결과는 다음과 같았다.
| 대상 | 평균 응답 시간(ms) |
|---|---|
| HashSet | 32 |
| LinkedHashSet | 841 |
| TreeSet | 32 |
TreeSet만 유독 느린 결과가 발생했다.
이런 TreeSet을 구현한 이유는 데이터의 정렬에 있다. TreeSet의 선언문을 보면
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, SerializableNavigableSet은 특정 값보다 큰 값이나 작은 값, 가장 큰 값, 가장 작은 값 등을 추출하는 메서드가 선언 돼있다. 즉, 데이터를 순서에 따라 탐색하는 작업에 TreeSet을 사용하는 것이다.
List
List에서는 대표적으로 ArrayList, LinkedList, Vector 클래스에 대해 알아볼 것이다.
Add
| 대상 | 평균 응답 시간(ms) |
|---|---|
| ArrayList | 28 |
| LinkedList | 40 |
| Vector | 31 |
3개의 클래스 모두 큰 차이가 없었다.
Search
| 대상 | 평균 응답 시간(ms) |
|---|---|
| ArrayList | 4 |
| LinkedList | 1,512 |
| Vector | 105 |
ArrayList > Vector > LinkedList 의 순으로 속도가 빨랐다.
LinkedList가 터무니없게 느린 이유는 Queue 인터페이스를 상속받기 때문이라고 한다. 이를 수정하기 위해서는 get() 메서드가 아닌 peek() 메서드를 사용해야 한다.
peek()를 사용한 경우는 다음과 같다
| 대상 | 평균 응답 시간(ms) |
|---|---|
| ArrayList | 4 |
| LinkedList | 1,512 |
| LinkedList(Peek) | 0.16 |
| Vector | 105 |
전과 다르게 훨씬 빨라진 걸 확인할 수 있다.
그 외에도 ArrayList와 Vector의 성능이 차이나는 이유에 대해서도 이야기 했다.
ArrayList의 경우 멀티스레드 환경에서 동기화 문제가 발생할 수 있다.
하지만 Vector의 경우 get() 메서드에 synchronized 를 사용했기 때문에 Thread-Safe 하다. 그래서 두 클래스의 성능 차이가 발생한 것이다.
Delete
테스트 횟수를 줄이기 위해 첫 번째와 마지막 값을 삭제하는 메서드를 사용했다.
| 대상 | 평균 응답 시간(ms) |
|---|---|
| ArrayList(first) | 418 |
| ArrayList(last) | 146 |
| LinkedList(first) | 687 |
| LinkedList(last) | 426 |
| Vector(first) | 423 |
| Vector(last) | 407 |
위의 결과를 보면 ArrayList와 Vector는 first를 지우는게 last를 지우는 것에 비해 느리게 나왔다.
이는 배열의 구조를 생각하면 당연한 결과일 수 밖에 없다.
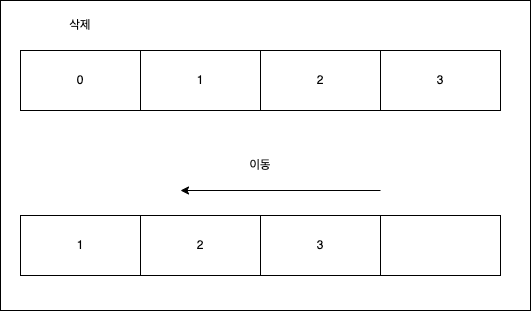
맨 앞의 값을 삭제할 경우 그 뒤에 있던 데이터를 모두 한 칸씩 앞으로 옮겨야 하므로 마지막을 삭제하는 경우에 비해 느리게 되는 것이다.
LinkedList의 경우 가리키는 객체만 변경하면 되기 때문에 first와 last 삭제의 차이가 없는 것이다.
Map
크게 이야기한 내용은 없고 바로 검색에서의 속도 비교로 진행했다.
Search
| 대상 | 평균 응답 시간(ms) |
|---|---|
| SeqHashMap | 32 |
| SeqHashtable | 106 |
| SeqLinkedHashMap | 34 |
| SeqTreeMap | 197 |
| RandomHashMap | 40 |
| RandomHashtable | 120 |
| RandomLinkedHashMap | 46 |
| RandomTreeMap | 277 |
대부분의 클래스가 동일하지만, 역시 Tree를 사용한 TreeMap이 가장 느린 것을 알 수 있다.
정리
각각의 자료구조에서 다양한 구현체를 확인할 수 있었다. 성능이 느린 클래스도 특수한 목적을 위해서 제작된 클래스 이므로 상황에 맞게 사용하는 것이 가장 중요하다고 언급되어있다.
하지만 고민 없이 일반적으로 무난하게 사용할 수 있는 클래스는 다음과 같다.
| 인터페이스 | 클래스 |
|---|---|
| Set | HashSet |
| List | ArrayList |
| Map | HashMap |
| Queue | LinkedList |
Reference
자바 성능 튜닝 이야기 (도서)
