해시Lv2위장
문제
문제 설명
스파이들은 매일 다른 옷을 조합하여 입어 자신을 위장합니다.
예를 들어 스파이가 가진 옷이 아래와 같고 오늘 스파이가 동그란 안경, 긴 코트, 파란색 티셔츠를 입었다면 다음날은 청바지를 추가로 입거나 동그란 안경 대신 검정 선글라스를 착용하거나 해야 합니다.
종류 이름
얼굴 동그란 안경, 검정 선글라스
상의 파란색 티셔츠
하의 청바지
겉옷 긴 코트
스파이가 가진 의상들이 담긴 2차원 배열 clothes가 주어질 때 서로 다른 옷의 조합의 수를 return 하도록 solution 함수를 작성해주세요.
제한사항
clothes의 각 행은 [의상의 이름, 의상의 종류]로 이루어져 있습니다.
스파이가 가진 의상의 수는 1개 이상 30개 이하입니다.
같은 이름을 가진 의상은 존재하지 않습니다.
clothes의 모든 원소는 문자열로 이루어져 있습니다.
모든 문자열의 길이는 1 이상 20 이하인 자연수이고 알파벳 소문자 또는 '_' 로만 이루어져 있습니다.
스파이는 하루에 최소 한 개의 의상은 입습니다.
입출력 예
clothes return
[["yellowhat", "headgear"], ["bluesunglasses", "eyewear"], ["green_turban", "headgear"]] 5
[["crowmask", "face"], ["bluesunglasses", "face"], ["smoky_makeup", "face"]] 3
입출력 예 설명
예제 #1
headgear에 해당하는 의상이 yellow_hat, green_turban이고 eyewear에 해당하는 의상이 blue_sunglasses이므로 아래와 같이 5개의 조합이 가능합니다.
-
yellow_hat
-
blue_sunglasses
-
green_turban
-
yellow_hat + blue_sunglasses
-
green_turban + blue_sunglasses
예제 #2
face에 해당하는 의상이 crow_mask, blue_sunglasses, smoky_makeup이므로 아래와 같이 3개의 조합이 가능합니다. -
crow_mask
-
blue_sunglasses
-
smoky_makeup
코드
#스파이들은 매일 다른 옷을 조합하여 입어 자신을 위장합니다.
# clothes의 각 행은 [의상의 이름, 의상의 종류]
def solution(clothes):
answer = 1
classify = dict()
for a,b in clothes:
if b in classify:
classify[b].append(a)
else:
classify[b] = [a]
for a in classify:
print(a)
answer *= (len(classify[a])+1) # 이 친구는 변태라 선글라스 끼고 아무것도 안 입을 수 있으므로 +1
return answer-1 # 옷을 아예 안입는 경우를 빼준다.다른 사람 코드
def solution(clothes):
from collections import Counter
from functools import reduce
cnt = Counter([kind for name, kind in clothes])
answer = reduce(lambda x, y: x*(y+1), cnt.values(), 1) - 1
return answercounter 이용하여 clothe 마다 value값 계산
reduce()함수안에 람다 함수를 이용하여 1부터 cnt.values()를 각각 곱한다
배운 것
람다 함수
lambda() 함수
lambda 매개변수 : 표현식
다음은 두 수를 더하는 함수입니다.
>>> def hap(x, y):
... return x + y
...
>>> hap(10, 20)
30이것을 람다 형식으로는 어떻게 표현할까요?
>>> (lambda x,y: x + y)(10, 20)
30몇 가지 함수를 더 배워보면서 람다가 어떻게 이용되는지 알아보도록 하죠.
map()
먼저 map 함수를 볼까요?
map(함수, 리스트)
이 함수는 함수와 리스트를 인자로 받습니다. 그렇죠? 그리고, 리스트로부터 원소를 하나씩 꺼내서 함수를 적용시킨 다음, 그 결과를 새로운 리스트에 담아준답니다. 말이 좀 복잡하죠? 그럴 때 예제를 보는 게 최고죠.
>>> map(lambda x: x ** 2, range(5)) # 파이썬 2
[0, 1, 4, 9, 16]
>>> list(map(lambda x: x ** 2, range(5))) # 파이썬 2 및 파이썬 3
[0, 1, 4, 9, 16]위의 map 함수가 매개변수로 받은 함수는 lambda x: x 2구요, 리스트로는 range(5)를 받았습니다. range 함수는 알고계시죠? range(5) 라고 써주면 [0, 1, 2, 3, 4]라는 리스트를 돌려줍니다. 그리고 x 2 라는 것은 x 값을 제곱하라는 연산자죠.
map 함수는 리스트에서 원소를 하나씩 꺼내서 함수를 적용시킨 결과를 새로운 리스트에 담아주니까, 위의 예제는 0을 제곱하고, 1을 제곱하고, 2, 3, 4를 제곱한 것을 새로운 리스트에 넣어주는 것입니다.
reduce()
이번엔 reduce 함수를 살펴봅시다.
reduce(함수, 시퀀스)
형식은 위와 같구요, 시퀀스(문자열, 리스트, 튜플)의 원소들을 누적적으로(?) 함수에 적용시킨답니다. 말이 진짜 어렵군요. 예제를 살펴보도록 하겠습니다.
>>> from functools import reduce # 파이썬 3에서는 써주셔야 해요
>>> reduce(lambda x, y: x + y, [0, 1, 2, 3, 4])
10위의 예제는 먼저 0과 1을 더하고, 그 결과에 2를 더하고, 거기다가 3을 더하고, 또 4를 더한 값을 돌려줍니다. 한마디로 전부 다 더하라는 겁니다. 생각보다 쉽죠?
의기양양하게 '예'라고 대답하신 분들을 위해 짜증나는 예제를 권해드리죠~.
>>> reduce(lambda x, y: y + x, 'abcde')
'edcba'
역순 더하기가 된다 !전 원래 뭐 하나를 배우면 꼭 엽기적인 실험을 해본답니다. 더 짜증나라고 설명 안 해드릴랍니다~
filter()
그 다음은 filter를 살펴볼 차례입니다. 필터가 뭐죠? 정수기에서 물을 걸러주는 것이 필터죠? 에어컨의 바람 들어가는 곳에도 필터가 달려있구요.
filter(함수, 리스트)
파이썬의 필터는 이렇게 생겼는데요, 리스트에 들어있는 원소들을 함수에 적용시켜서 결과가 참인 값들로 새로운 리스트를 만들어줍니다. 다음은 0부터 9까지의 리스트 중에서 5보다 작은 것만 돌려주는 예제입니다.
>>> filter(lambda x: x < 5, range(10)) # 파이썬 2
[0, 1, 2, 3, 4]
>>> list(filter(lambda x: x < 5, range(10))) # 파이썬 2 및 파이썬 3
[0, 1, 2, 3, 4]reduce() 함수
파이썬의 functools 내장 모듈의 reduce() 함수는 여러 개의 데이터를 대상으로 주로 누적 집계를 내기 위해서 사용합니다.
기본 문법은 다음과 같은데요. 기본적으로 초기값을 기준으로 데이터를 루프 돌면서 집계 함수를 계속해서 적용하면서 데이터를 누적하는 방식으로 작동합니다.
reduce(집계 함수, 순회 가능한 데이터[, 초기값])
여기서, 집계 함수는 두개의 인자를 받아야 하는데요. 첫번째 인자는 누적자(accumulator), 두번째 인자는 현재값(current value)가 넘어오게 됩니다. 누적자는 함수 실행의 시작부터 끝까지 계속해서 재사용되는 값이고, 현재값은 루프 돌면서 계속해서 바뀌는 값입니다.
실습 데이터 생성
파이썬 인터프리터에서 다음과 같이 유저 5명의 데이터를 임의로 생성합니다. 5개의 dictionary를 담고 있는 list 입니다.
>>> users = [{'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'sex': 'M', 'age': 73},
... {'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'sex': 'F', 'age': 29},
... {'mail': 'wwagner@gmail.com', 'name': 'Michael Jenkins', 'sex': 'M', 'age': 51},
... {'mail': 'daniel79@gmail.com', 'name': 'Karen Rodriguez', 'sex': 'F', 'age': 32},
... {'mail': 'ujackson@gmail.com', 'name': 'Amber Rhodes', 'sex': 'F', 'age': 42}]임포트
reduce()는 내장 함수가 아니기 때문에 functools 내장 모듈을 통해서 임포트를 해줘야 사용할 수 있습니다.
>>> from functools import reduce```
나이 합계 구하기
그럼, 실습 데이터를 대상으로 reduce() 함수를 사용해서 유저들의 나이의 합을 구해보도록 하겠습니다.
>>> reduce(lambda acc, cur: acc + cur["age"], users, 0)
227
누작자에 초기값 0이 세팅되고, 그 다음 각 유저의 나이가 집계 함수에 의해서 계속해서 더해지게 됩니다.
다음과 같이 reduce() 함수의 실행 과정을 직접 따라가보면 좀 더 이해가 쉬우실 것입니다.
>>> 0
0
>>> 0 + 73
73
>>> 73 + 29
102
>>> 102 + 51
153
>>> 153 + 32
185
>>> 185 + 42
227
이메일 목록 구하기
유저 이메일 목록도 reduce() 함수를 이용하면 어렵지 않게 만들어 낼 수 있습니다.
>>> reduce(lambda acc, cur: acc + [cur["mail"]], users, [])
['gregorythomas@gmail.com', 'hintoncynthia@hotmail.com', 'wwagner@gmail.com', 'daniel79@gm
Counter()함수
dictionary를 이용한 카운팅
아래 코드는 어떤 단어가 주어졌을 때 단어에 포함된 각 알파멧의 글자 수를 세어주는 간단한 함수입니다.
def countLetters(word):
counter = {}
for letter in word:
if letter not in counter:
counter[letter] = 0
counter[letter] += 1
return counter
countLetters('hello world'))
# {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}
이처럼 데이터의 개수를 셀 때 파이썬의 내장 자료구조인 사전(dictionary)이 많이 사용되는데요.collections.Counter를 이용한 카운팅
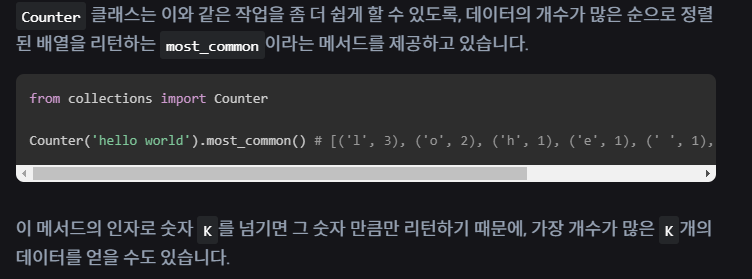
파이썬에서 제공하는 collections 모듈의 Counter 클래스를 사용하면 위 코드를 단 한 줄로 줄일 수가 있습니다.
from collections import Counter
Counter('hello world') # Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
collections.Counter 기본 사용법
collections 모듈의 Counter 클래스는 별도 패키지 설치 없이 파이썬만 설치되어 있다면 다음과 같이 임포트해서 바로 사용할 수 있습니다.from collections import Countercollections 모듈의 Counter 클래스는 파이썬의 기본 자료구조인 사전(dictionary)를 확장하고 있기 때문에, 사전에서 제공하는 API를 그대로 다 시용할 수가 있습니다.
예를 들어, 주어진 단어에서 가장 많이 등장하는 알페벳과 그 알파벳의 개수를 구하는 함수는 다음과 같이 마치 사전을 이용하듯이 작성할 수 있습니다.
from collections import Counter
def find_max(word):
counter = Counter(word)
max_count = -1
for letter in counter:
if counter[letter] > max_count:
max_count = counter[letter]
max_letter = letter
return max_letter, max_count
find_max('hello world') # ('l', 3)