CH#1. 주요 개념
Galera Cluster

Syncnrhnous/Asynchronous
1. 동기/비동기 복제 구분에서 주요하게 관찰해야 할 키워드는 transaction과 commit이다. lazy replication인 비동기 복제는 마스터가 복제 내용을 전파한 순간 transaction이 commit된다. 따라서 마스터와 다른 노드 간 내용이 다른 순간이 잠시라도 존재한다. 내 손을 떠났으니까 책임지지 않는 무책임한 모습이다..?
2. Eager replication의 동기적 복제는 transaction commit 시점에 모든 노드가 같은 내용을 공유하는데, 속도가 느린 문제가 있다고 한다.
3. Eager replication의 경우 2 phase commit(혹은 distributed locking)을 사용한다고 하는데 이는 간단하게 커밋을 할지/말지 결정하고(temporary) 합의가 이뤄진 상황(permanent)에서부터는 이를 롤백 지점으로 사용할 수 있다는 특징을 가진다. 이 롤백 가능 여부는 장점이기도 하지만, blocking이라는 문제를 갖는다고 한다.
4. n: 노드 개수, o: 작업 개수, t: 초당 트랜잭션 조건에서 초당 메세지 m은 m = n o t로 도출할 수 있는데, 이 때문에 n 증가량에 exponential하기 때문에 "동기적 복제는 느리다."는 명제의 구체적 원인이 된다고는 하는데, 수식 자체에서 exponential의 원인을 설명하지는 않고 있다. 아마 t가 n의 영향을 받기 때문이 아닐까?
Certification-based replication
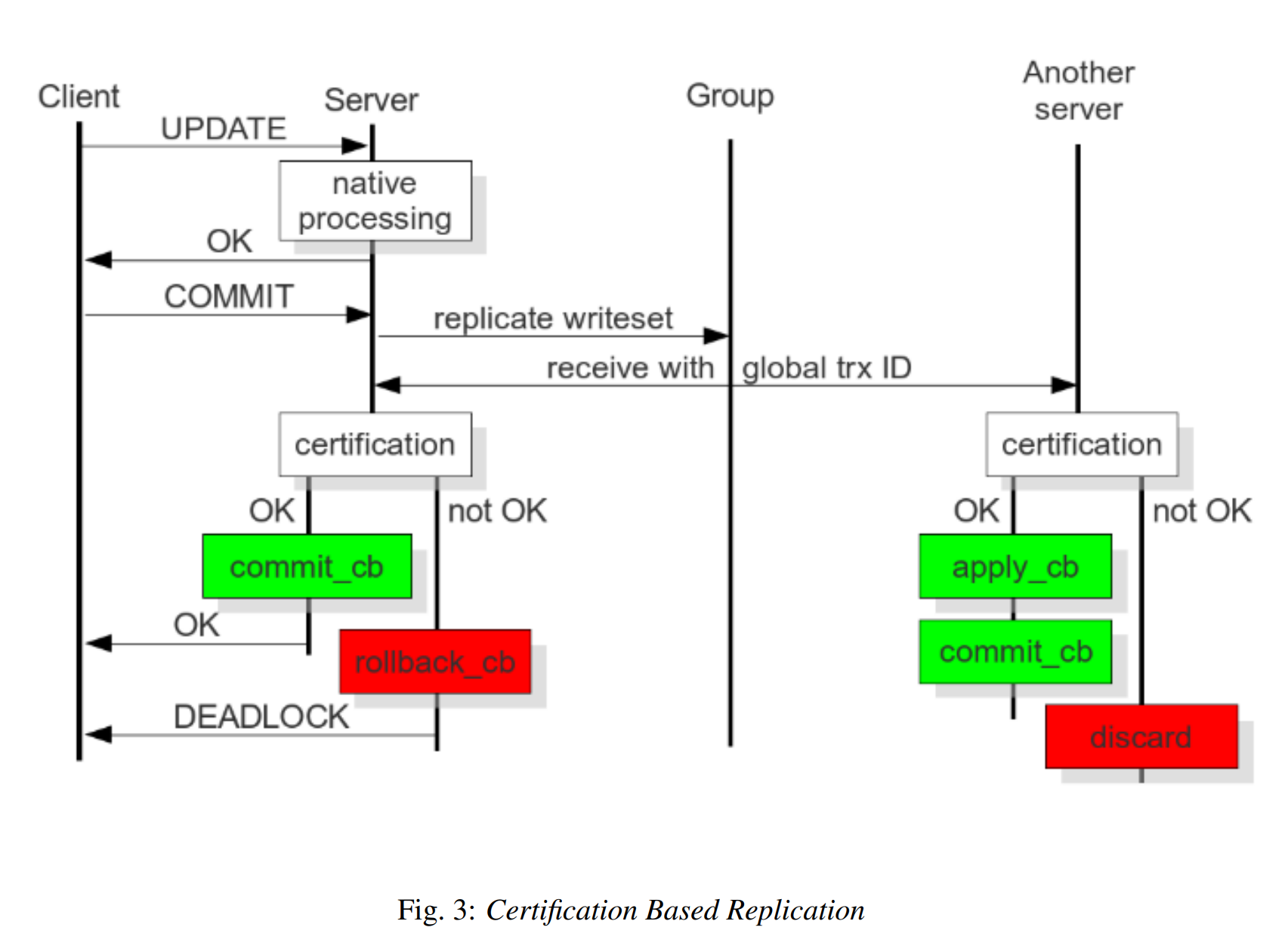
1. 앞서 lazy replication은 마스터가 복제 내용을 전파한 순간 transaction commit이 이뤄진다고 했는데, 인증-기반 복제에서는 commit command를 전달하는 시점과 실제 commit이 이뤄지는 시점이 다르다.(commit command가 실제 commit에 선행한다.) 따라서 보다 eager replication에 가깝다고 이해할 수 있었다.
2.
먼저 commit command가 전달되면 DB 업데이트 내용과 primary key가 write-set에 작성된다.
write-set은 각 노드에 보내지며, 기준 노드를 포함해서 인증 작업을 거친다.
3. Commit 시점까지 non-conflict를 가정하고 고전적인 transaction을 수행할 수 있는 이유는, 아마 2PC이 roll-back point을 보장하므로 나중에 후회해도? 안전하기 때문이라고 생각한다.
3. Transaction order이 보장될 때 이 복제 방식을 cluster 수준으로 확장할 수 있는데, 그것을 적용한 것이 Galera cluster이다.
wsrep API
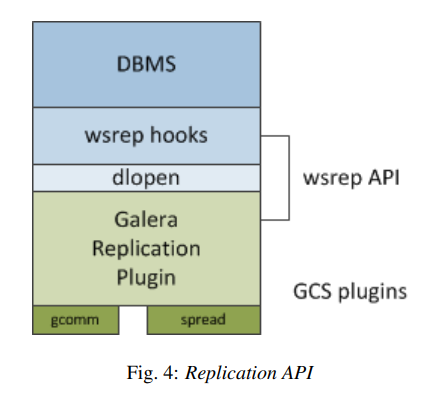
1. DB 서버와 복제 플랫폼을 wsrep API라 할 때 이는 다시
write set관련 기능을 제공하는 Galera Replication Plugin
(추상적인) 상태 변화를 '낚아채' (보다 구체적인) write set에 해석해 놓는 wsrep hook
hook과 기능 공급자를 연결하는 dlopen()으로
구분할 수 있다.
2. wsrep API는 DB 서버의 내용 변화를 상태(state)로서 참조한다고 할 수 있는데, 나중에 확인할 global transaction identifier(GTID) 역시 state를 참조한 기능이다.
3. Galera replication plugin은 다시certification layer/replication layer/group communication framework 층위로 구분할 수 있다.
4. gcomm에서는 virtual synchrony QoS를 사용함에 따라 메세지 전달 혹은 노드들의 state의 공유에 있어 일관성은 제공하지만, temporal synchrony는 보장하지 않는다고 한다.
5.이는 multi-master 환경에서 치명적이라고 하는데 이를 런타임 환경에서 조절하기 위해 (뒤에 설명할) flow control 메커니즘을 도입했다고 한다. 아마 feedback을 무수히 수행해서 노드 간 동기화를 보장하는 것 같다.
6. 통신 관점에서 복제를
메세지의 의미론적 delivery와
멤버들이 제공받는 서비스로
구분할 수 있다는 점이 흥미로웠다.
Isolation Level
1. READ-UNCOMMITTED/READ-COMMITTED/REPEATABLE-READ/SERIALIZABLE의 네 단계가 있는데 첫 번째는 (dirty read 현상 등의 이유로) 사실상 격리 수준이라 부르기 어렵고, 마지막은 multi-master 클러스터에서는 권장되나 읽기 수준에서도 공유 잠금을 걸어 성능에 영향이 크다고 한다.
2. 세 번째 REPEATABLE-READ가 다른 트랜잭션의 커밋 여부를 신경쓰지 않고, 적어도 read 수준에서의 정합성을 보장할 수 있어서 합리적으로 보인다. MySQL에서는 이를 기본으로 지원한다고 한다.
GCache
1. write-set은 GCache에 저장되는데, 이것의 제 1 목적은 램 상의 write-set footprint를 최소화하는 것이라고 한다.
2. Permanent In-Memory Store/Permanent Ring-Buffer File/On-Demand Page Store 순서로 저장되는 알고리즘에서 ring-buffer style이 주된 저장소인데 footprint 대목과 관련 지어서 생각해보자면, 미리 할당된 메모리를 (head/tail pointer에 의해) 안전하게 사용하는 데 그 목적이 있다고 생각해볼 수 있을 것 같다.
3. Ring-buffer의 특징은 다음과 같다고 한다.
고정된 사이즈에서 시작과 끝을 자유롭게 변경할 수 있다.
Read/write pointer를 이용해서 데이터 입력/출력이 간섭없이 (거의) 동시에 이루어질 수 있다.
4. write-set 캐싱은 memory mapping을 이용하는데 이는 파일을 프로세스의 메모리에 직접 매핑해서 입/출력 함수를 거치지 않고 변수를 사용하는 방법이라고 한다. 그래서 표시 메모리 사용량보다 실제 메모리 사용량이 적을 수 있다고 한다.
State Transfer
1. Dump와 유사하다고 생각한 State Snapshot Transer(SST)은 다시 logical/physical로 구분할 수 있는데, 전자에 해당하는 mysqldump 진행 시 마스터는 read lock이 걸리게 되므로 blocking한 방법이다.
2. logical/physical의 큰 차이는 전자에서는 데이터 이동 전에 수신 서버 초기화가 필요하다는 점인데 DB가 중심이 돼서 수신 서버가 DB 구조 자체를 수용할 수 있도록 마음의 준비를 하는 모양새고, 후자는 데이터 전송 이후에 수신 서버 초기화가 필요하긴 한데 수신/송신 서버 간 설정이 비슷해야 하는 등의 제약이 있다고 한다. 그래도 보다 데이터 중심 관점으로 이해됐다.
3. IST(Incrememtal State Transfer)에서는 donor/joiner의 동일 UUID 여부와 doner의 GCache size가 중요하다. Doner 입장에서 non-blocking한 작업이라고 한다.
(차후 정리 필요)
Flow Control
Quorom
Streaming Replication
참조
https://severalnines.com/blog/how-galera-cluster-enables-high-availability-high-traffic-websites/
https://severalnines.com/blog/multiple-data-center-setups-using-galera-cluster-mysql-or-mariadb/
https://severalnines.com/blog/comparing-mariadb-server-mariadb-cluster/
https://severalnines.com/blog/how-set-asynchronous-replication-galera-cluster-standalone-mysql-server-gtid/
https://severalnines.com/blog/avoiding-deadlocks-galera-setting-haproxy-single-node-writes-and-multi-node-reads/
https://severalnines.com/blog/how-avoid-sst-when-adding-new-node-mysql-galera-cluster/
https://severalnines.com/blog/galera-cluster-comparison-codership-vs-percona-vs-mariadb/
https://galeracluster.com/2015/07/geo-distributed-database-clusters-with-galera/
https://mariadb.com/kb/en/using-mariadb-replication-with-mariadb-galera-cluster-using-mariadb-replica/
https://mariadb.com/kb/en/configuring-mariadb-replication-between-two-mariadb-galera-clusters/
https://mariadb.com/kb/en/using-mariadb-replication-with-mariadb-galera-cluster-configuring-mariadb-r/
https://www.youtube.com/watch?v=VSGOnoy_j2k&t=46s
https://www.youtube.com/watch?v=QCVWE_B0qfk&t=215s
https://sightstudio.tistory.com/59
https://en.wikipedia.org/wiki/Circular_buffer
https://galeracluster.com/library/faq.html
https://www.linkedin.com/pulse/two-phase-commit-2pc-umang-agarwal-1f/
https://galeracluster.com/library/galera-documentation.pdf
https://joont92.github.io/db/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98-%EA%B2%A9%EB%A6%AC-%EC%88%98%EC%A4%80-isolation-level/
