HBase Write Process
클라이언트에서 데이터를 PUT하라는 쿼리가 발생하면, 해당 데이터는 WAL에 기록된다. WAL은 Write-Ahead Log로 입력된 데이터를 append형식으로 관리한다. WAL에 쌓인 데이터는 Memstore로 copy가 된다. 이때 클라이언트에 데이터가 성공적으로 write가 되었다는 acknowledgement 신호가 전송된다.
Memstore에서는 Key-Value 데이터를 정렬된 상태로 저장한다. 이후, memstore에서 설정한 threshold size보다 크기가 커지게 되면 memstore에 저장되어 있는 데이터를 Column Family마다 HFile로 저장한다. 하지만 column family가 늘어나면 HFile이 늘어나는 구조이기 때문에, HBase는 column family에 제한을 두고 있다. 또한 마지막으로 기록된 시퀀스 번호 (TimeStamp) 저장해서 지금까지 저장한 내용을 추척할 수 있게 한다.
HBase Balancing
Region Server는 하나 이상의 Region을 서비스 하고, 각 Region은 하나의 Region Server에 시작시 할당된다. Master는 load balancing의 결과로 region을 원래의 region server에서 다른 region server로 이동하도록 결정할 수 있다. 하나의 region이 커져서, sharding 과정으로 인해 두개의 region 으로 나눠지고, load balancing로 인해 하나의 region이 다른 region server로 옮겨지게 된다. 이것은 major compaction이 데이터 파일을 region server의 local node로 옮길때 까지, remote access로 다른 region server에서 데이터를 가져온다.
HBase Data Replication
HDFS는 쓰기로 인해서 만들어진 WAL과 HFile Block을 복제한다. HBase는 HDFS의 data replication 정책으로 인해 하나의 cluster의 failure로 인해 해당 cluster 내부에 저장되어 있는 데이터가 손실되는 것을 방지한다. 데이터가 HDFS에 쓰여지면 하나의 copy는 locally 하게 저장되고, 그런 후에 secondary node에 데이터가 replication 된다. Replication 노드는 network topology로 의해 결정된다.
HBase Read Process
Zookeeper
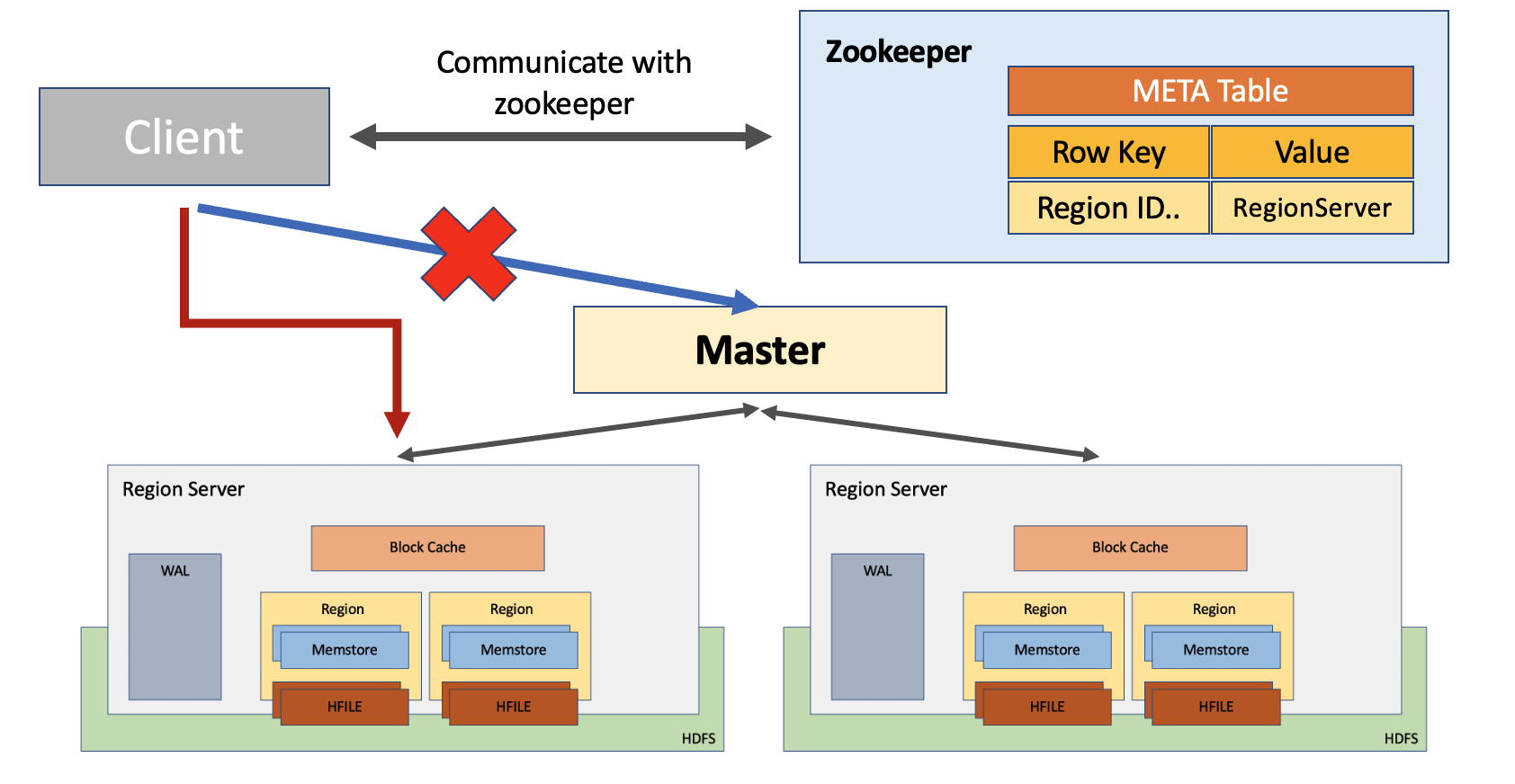
HBase는 zookeeper를 이용해서 cluster를 구성하는 서버들의 상태를 관리힌다. Zookeeper는 서비스들이 살아 있는지 HeartBeat 메세지를 통해서 확인하며, 사용 가능한지를 모니터링한다. HMaster의 system failure는 전체 cluster의 실패로 이어질 수 있으므로, 두대 이상의 노드가 Master/Slave 방식으로 구성되며 활성화 하는 노드는 zookeeper가 관리한다. 또한 regionserver의 system failure는 문제의 노드를 cluster에서 즉시 제외된다. 이 모든 관리를 zookeeper에서 하게 된다.
Zookeeper META TABLE
HBase는 META TABLE이라는 HBase Catalog table을 유지한다. 이는 cluster에 포함된 region의 위치정보를 저장하고 있다. HBase META TABLE은 Zookeeper에서 관리한다. META TABLE은 Key-Value형태로 구성되며, Row Key는 region의 ID와 Table, Start Key에 대한 정보가 Value는 Region Server로 구성된다.
HBase Read Schematic Diagram
Client는 Read Query의 Key를 찾기 위해 HMaster와 통신하는 것이 아니라, Zookeeper와 통신한다.
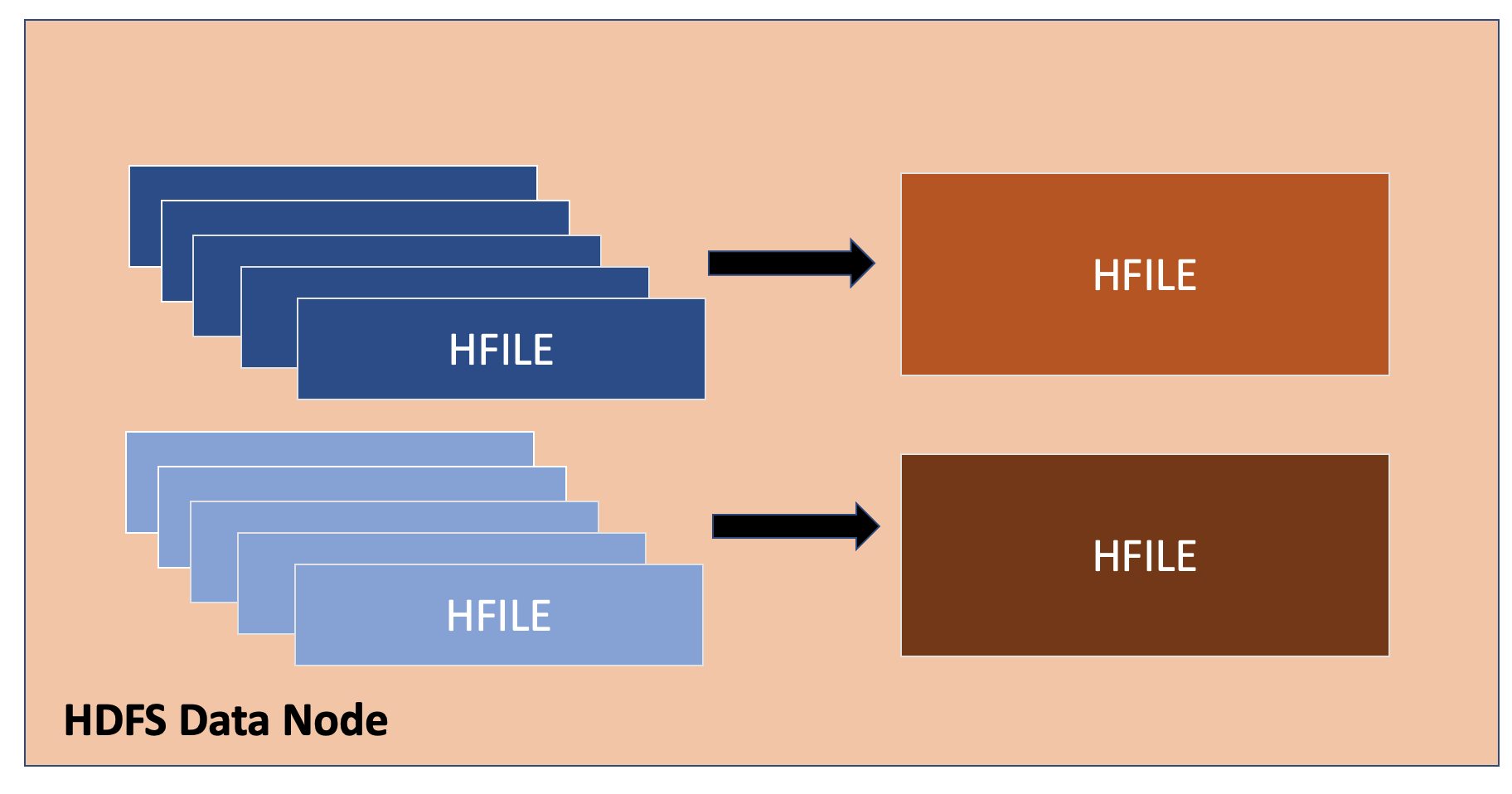
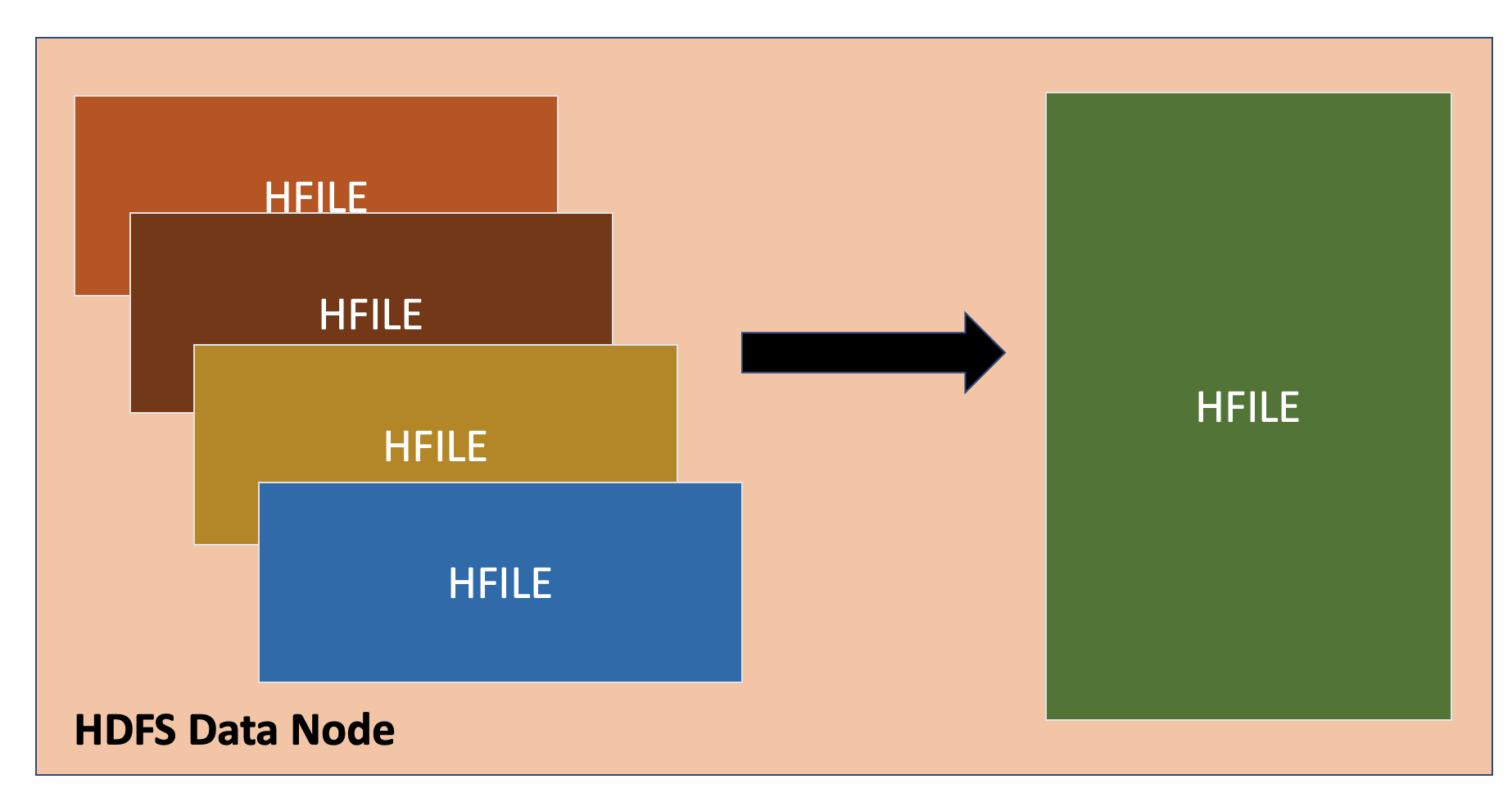
HBase Compaction
HBase Minor Compaction
HBase는 자동적으로 configuration xml 파일에서 정해진 수만큼 HFile을 집어와서, 약간 더 큰 HFile안에 다시 쓴다. 이 과정을 Minor Compaction이라고 한다. Minor Compaction은 HFile 숫자를 줄이고 작은 HFile을 좀 더 큰 HFile로 쓴다. HFile의 수를 줄임으로써, Overlapping되는 range을 포함하는 HFile의 수를 줄일 수 있어서, Read과정에서 Disk I/O의 수가 줄어들게 된다.
HBase Major Compaction
Major Compaction은 한 Region안에 있는 모든 Hfile을 하나의 Column Family마다의 HFile로 머지하고 다시 쓰는 작업이다. 그리고 이 과정에서, 셀을 drop, 삭제하거나 expire한다. 이 작업이 이뤄지면, Minor Compaction과 같은 이유로 read performance을 향상시킨다. 그러나 Major Compaction이 모든 파일을 새로 쓰기 때문에 Disk I/O와 Network Traffic이 많이 발생한다. 이 작업을 write amplification이라고 한다. 그렇기 때문에 Minor Compaction에 비해 자주 일어나지 않으며 default configuraiton 설정으로는 7일에 한번씩 일어난다.