- pair와 tuple
- vector
- Array
- 배열이란?
- 2차원 배열
- map
- set
- multiset
- stack
- queue
- deque
- struct(구조체)
- priority queue
- 자료구조 복잡도 정리
1. pair와 tuple
1. pair와 tuple
- 두 가지 값을 담을 때에는 pair, 세 가지 이상의 값을 담을 때에는 tuple
2. tie
- pair 또는 tuple에 들어있는 2가지 이상의 값을 끄집어낼 때 사용
tie(a, b) = pi;,tie(a, b, c) = tl;first와 second를 쓰면 상대적으로 복잡해짐
3. 정렬(sort())
sort(first, last, *커스텀비교함수)- '*커스텀비교함수'는 기본적으로 오름차순('less()') 'greater()'를 사용하여 내림차순으로 변경가능
2. vector
- 동적으로 요소를 할당할 수 있는 동적 배열
- 컴파일 시점에 개수를 모른다면 벡터를 써야 함
- push_back(), pop_back(), erase, find(vector의 함수가 아니라 algorithm에서 제공하는 함수), clear()
3. Array
- 정적배열
- 연속된 메모리 공간이며 스택에 할당
1. 배열의 초기화 : fill과 memset
- fill(시작값, 끝값, 초기화 하는 값)
fill(v.begin(), v.end(), 0); - memset(초기화하는 배열, 값, 배열의 크기) $\to\
memset(v, 0, sizeof(v));
2. 배열의 복사 : memcpy
- 어떤 변수의 메모리에 있는 값들을 다른 변수의 "특정 메모리값"으로 복사랗 때 사용
- 주로 배열을 복사할 때 사용
memcpy(temp, a, sizeof(a));
4. 배열이란?
- 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합 C++에서는 vector나 array로 구현
1. 랜덤 접근과 순차적 접근
5. 2차원 배열
6. map
- key와 value 형태로 이루어져 있고 레드-블랙트리라는 구조를 내장
- 데이터를 삽입할 때 '정렬된' 위치에 삽입
- first와 second를 이용하여 탐색이 가능
7. set
- 특정 순서에 따라 고유한 요소를 저장하는 컨테이너
- 중복되는 요소는 없고, 오로지 희소한(unique) 값만 저장하는 자료구조
8. multiset
- 중복되는 원소도 집어넣을 수 있는 자료구조
- key와 value 형태로 집어넣을 필요도 없고, 넣으면 자동적으로 정렬되는 편리한 자료구조
9. stack
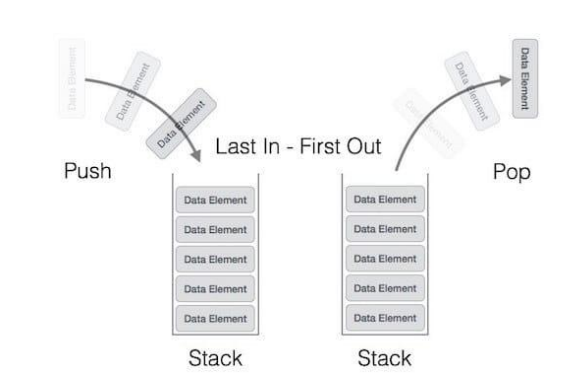
- LIFO(Last In First Out)
- 문자열 폭발, 아름다운 괄호 만들기, 짝을 찾기 등의 문제에 쓰임
- "교차하지 않고" 라는 문장이 나오면 스택을 사용할지 말지를 의심
10. queue
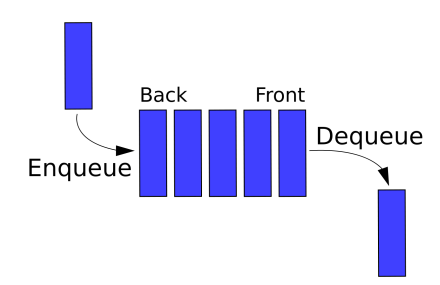
- FIFO(First In First Out)
- 주로 BFS에서 사용
11. deque
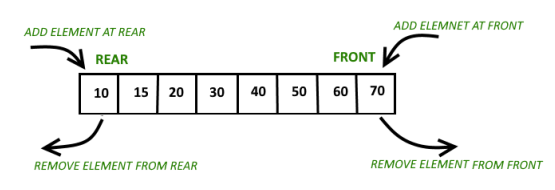
- queue는 앞에서만 끄집어낼 수 있는 반면, dequeue에서는 앞뒤로 참조가 가능
12. struct(구조체)
- C++에서는 커스텀한 구조체를 형성하기 위해 class와 struct를 사용하는데, struct만 알아도 충분
- 커스텀한 무언가를 진행하고 싶다면 구조체를 통해서 해야 함
13. priority queue
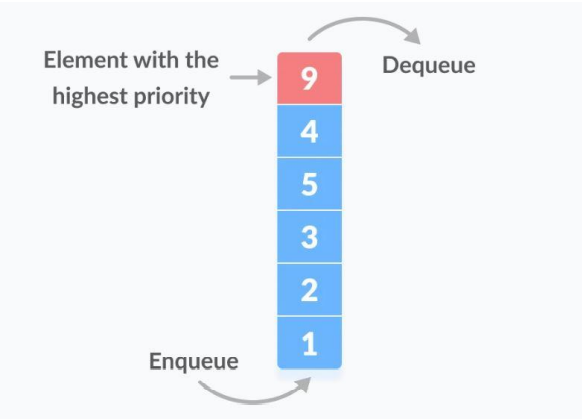
- 우선순위 큐
- 내부 구조는 heap으로 구현되어있으며 주로 다익스트라, 그리디 등에 쓰임
- priority_queue<자료형, 구현체, 비교연산자>
priority_queue<int, vector<int>, greater<int>> pq;
14. 자료구조 복잡도 정리
보통 시간 복잡도를 생각할 때, '평균' 그리고 '최악의 시간 복잡도'를 고려하면서 사용
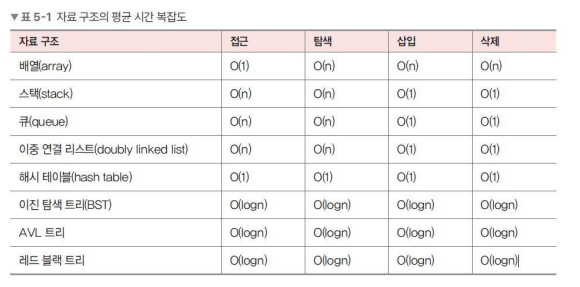
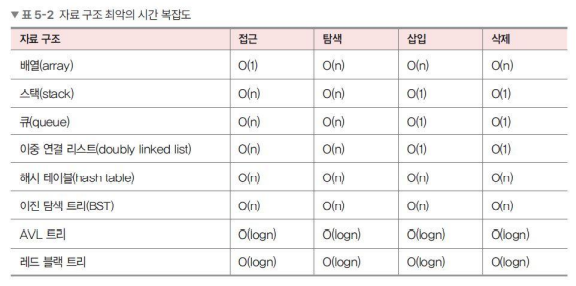
이 글은 큰돌님의 '10주완성 C++코딩테스트 | 알고리즘 IT취업'을 수강하고 정리한 내용입니다.

가보자고