DB
1.데이터베이스 정규화

개념데이터베이스의 설계를 재구성하는 기술목적불필요한 데이터(data redundancy) 제거데이터 저장을 논리적으로 함규칙각 컬럼이 하나의 속성만을 가져야 함하나의 컬럼은 같은 종류나 같은 타입을 가져야 함각 컬럼이 유일한 이름을 가져야 함칼럼의 순서가 상관이 없어야
2023년 4월 20일
2.SQL query
양 끝 a, b 포함
2023년 5월 17일
3.Function & Procedure
delimeterDELIMITER: delimer(구분자) 재정의return함수가 반환하는 데이터 유형 정의
2023년 6월 9일
4.window function
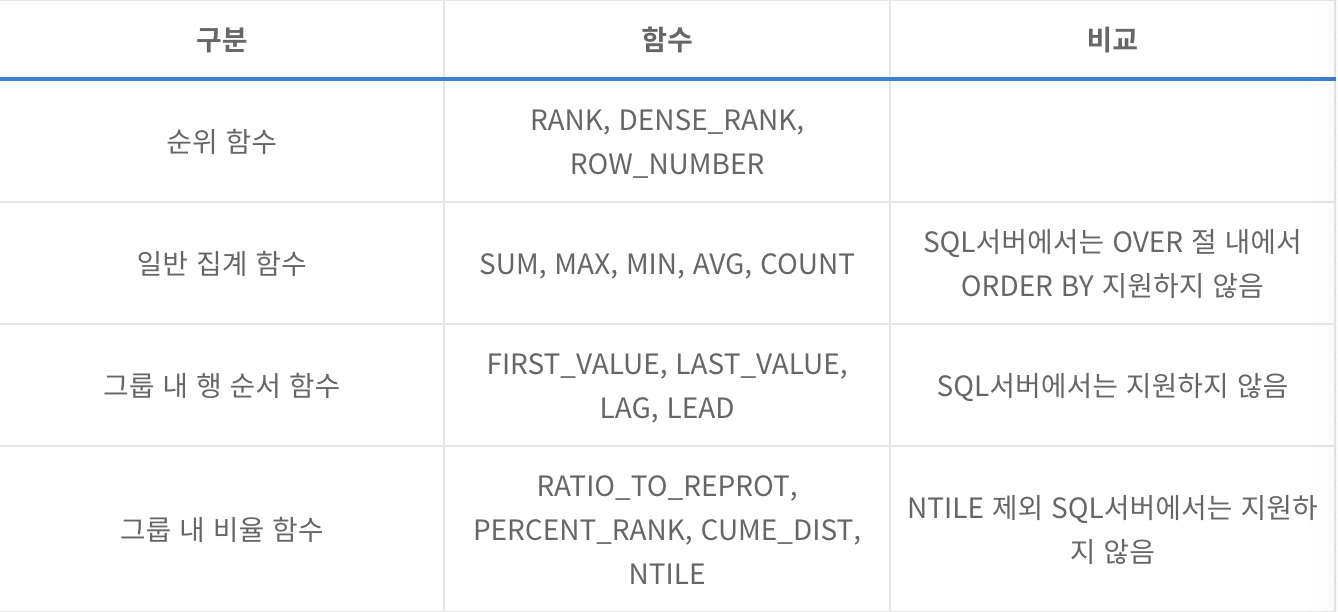
기본 문법partition by: 전체 집합을 해당 기준에 소그룹으로 나눔종류RANK: order by를 포함한 쿼리문에서 특정 컬럼의 순위를 구하는 함수중간 순위 비움DENSE_RANK: rank 작동법과 동일, 중간 순위 비우지 않음ex) 1,1,2,3,3,4row
2023년 6월 13일
5.Transaction
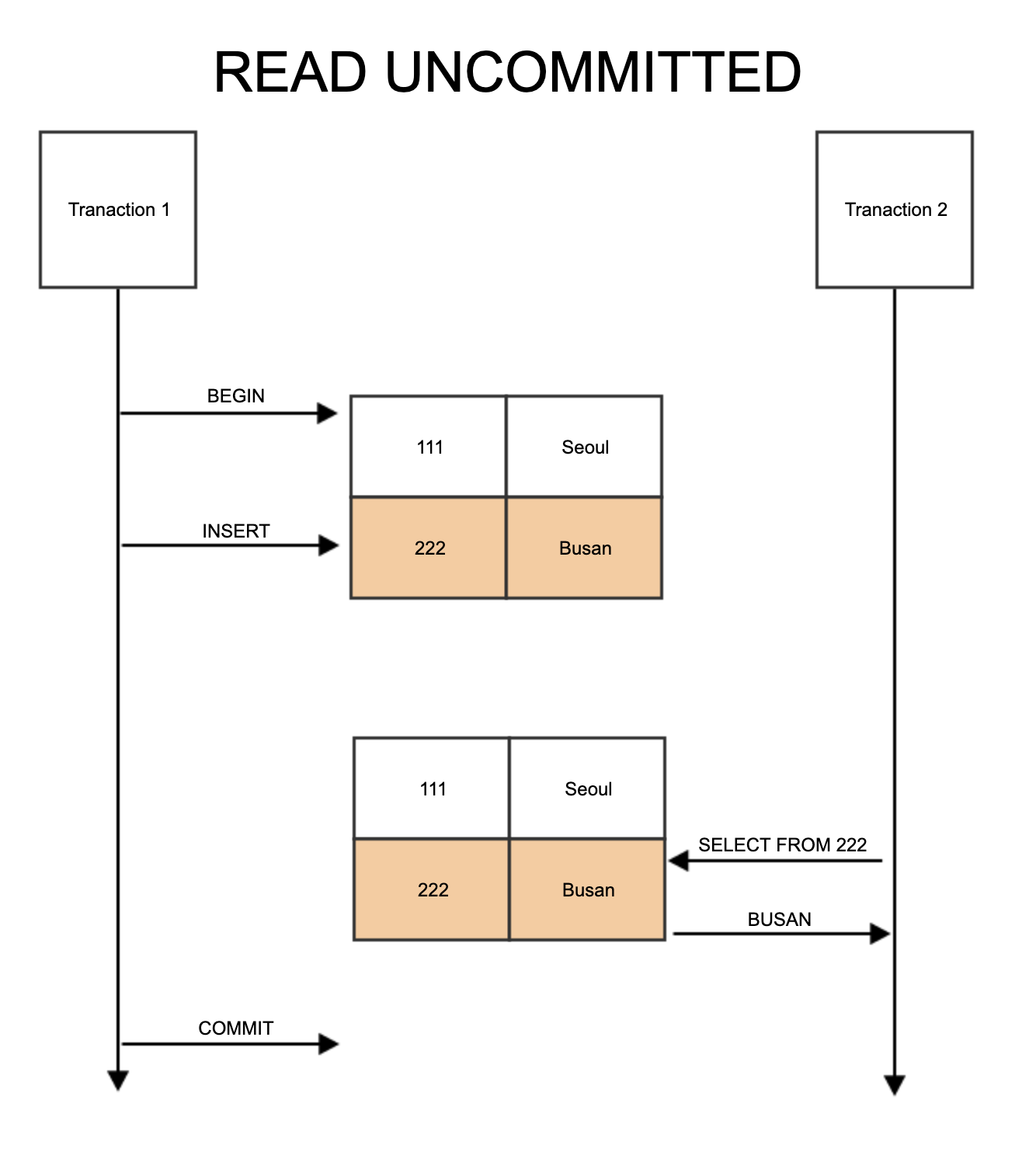
dirty read아직 commit 되지 않은 수정중인 데이터를 다른 트랜잭션에서 읽을 수 있도로 허용non-repeatable read한 트랜잭션에서 같은 쿼리를 두 번 수행할 때 그 사이에 다른 트랜잭션 값을 수정 또는 삭제하면서 두쿼리의 결과가 상이하게 나타나는
2023년 6월 14일