문제
BEER라는 단어를 이루는 알파벳들로 만들 수 있는 단어들을 사전 순으로 정렬하게 되면
BEER
BERE
BREE
EBER
EBRE
EEBR
EERB
ERBE
EREB
RBEE
REBE
REEB와 같이 된다. 이러한 순서에서 BEER 다음에 오는 단어는 BERE가 된다. 이와 같이 단어를 주면 그 단어를 이루는 알파벳들로 만들 수 있는 단어들을 사전 순으로 정렬할 때에 주어진 단어 다음에 나오는 단어를 찾는 프로그램을 작성하시오.
입력
입력의 첫 줄에는 테스트 케이스의 개수 T (1 ≤ T ≤ 10)가 주어진다. 각 테스트 케이스는 하나의 단어가 한 줄로 주어진다. 단어는 알파벳 A~Z 대문자로만 이루어지며 항상 공백이 없는 연속된 알파벳으로 이루어진다. 단어의 길이는 100을 넘지 않는다.
출력
각 테스트 케이스에 대해서 주어진 단어 바로 다음에 나타나는 단어를 한 줄에 하나씩 출력하시오. 만일 주어진 단어가 마지막 단어이라면 그냥 주어진 단어를 출력한다.
예제 입력
4
HELLO
DRINK
SHUTTLE
ZOO예제 출력
HELOL
DRKIN
SLEHTTU
ZOOCode
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
let T = +input[0]; // 테스트 케이스 개수
let line = 1;
let answer = ''; // 출력 결과
while (T > 0) {
const word = input[line].split(''); // 단어 쪼개기
let [index1, index2] = [-1, -1];
// 단어 맨 뒤부터 아스키 코드 값이 감소하는 부분 찾기
for (let i = word.length - 1; i > 0; i -= 1) {
if (word[i - 1].charCodeAt() < word[i].charCodeAt()) {
index1 = i - 1;
break;
}
}
// 감소하는 부분이 없다면 사전 순으로 가장 맨 마지막이므로 그냥 해당 값 출력
if (index1 === -1) {
answer += word.join('') + '\n';
} else {
// 단어 맨 뒤부터 감소하는 부분보다 큰 부분 구하기
for (let i = word.length - 1; i > index1; i -= 1) {
if (word[i].charCodeAt() > word[index1].charCodeAt()) {
index2 = i;
break;
}
}
// 두 알파벳 순서 변경
const temp = word[index1];
word[index1] = word[index2];
word[index2] = temp;
// 감소하는 부분 기준으로 뒤에 부분 오름차순 정렬
answer +=
[...word.slice(0, index1 + 1), ...word.slice(index1 + 1).sort()].join(
''
) + '\n';
}
line += 1;
T -= 1;
}
answer = answer.trimEnd();
console.log(answer);풀이 및 해설 ⇒
- 출력값 ⇒ 사전순으로 정렬 후 주어진 단어 다음에 나오는 단어
아스키 코드 이용하여 정렬
- 단어를 split() 이용해서 쪼개기
- 단어 맨 뒤부터 해당 알파벳의 아스키코드가 감소하는 부분 찾기
- 단어 맨 뒤부터 감소하는 아스키코드보다 큰 부분 찾기
- 두 위치 바꾸기
- 감소하는 부분 인덱스 이후부터 다시 오름차순 정렬
ex) ACDB → 다음 단어 구하기
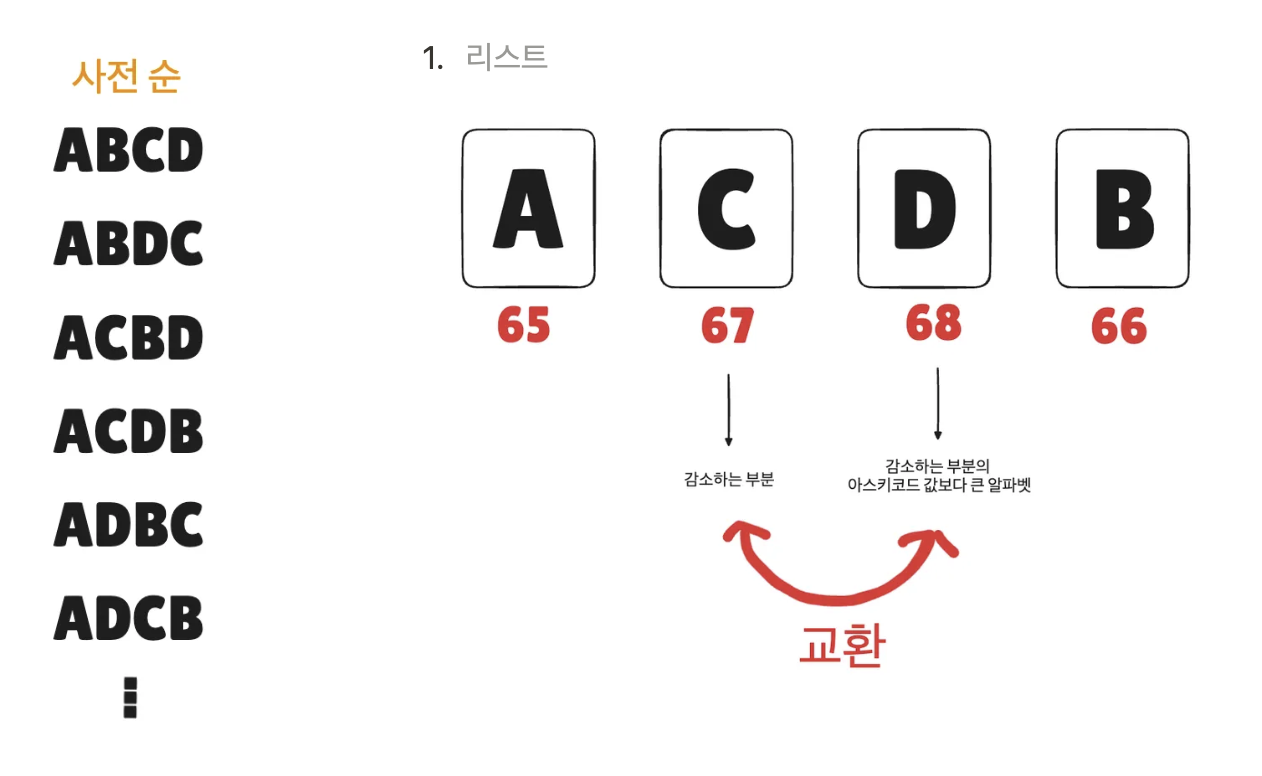
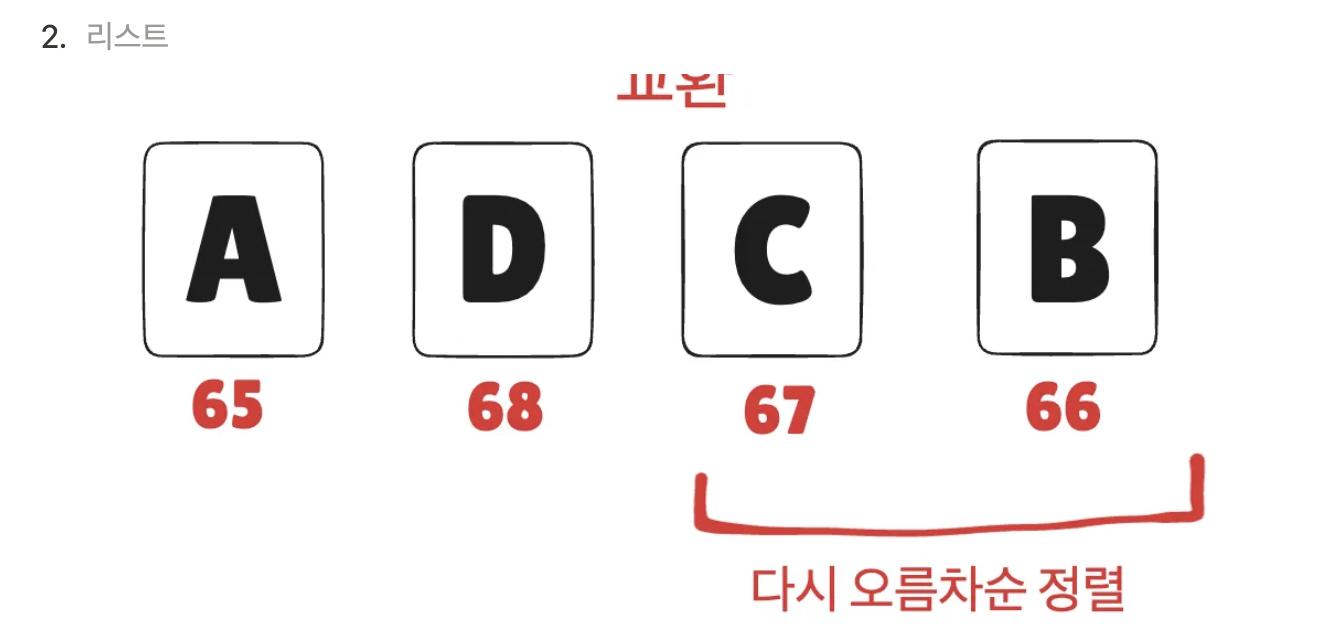

첫 풀이 Code => 메모리 초과
const fs = require('fs');
const input = fs.readFileSync('/dev/stdin').toString().split('\n');
let T = +input[0]; // 테스트 케이스 개수
let line = 1;
const permutationFunc = (arr, selectedNum) => {
if (selectedNum === 1) return arr.map((a) => [a]);
const result = [];
arr.map((fixed, idx, origin) => {
const remainer = [...origin.slice(0, idx), ...origin.slice(idx + 1)];
const permutation = permutationFunc(remainer, selectedNum - 1);
const attached = permutation.map((item) => [fixed, ...item]);
result.push(...attached);
});
return result;
};
let answer = '';
while (T > 0) {
const word = input[line];
const permutationResult = permutationFunc(word.split('').sort(), word.length);
const set = new Set();
permutationResult.forEach((permu) => set.add(permu.join('')));
const dictionary = [...set];
const index = dictionary.findIndex((item) => word === item);
answer +=
index === dictionary.length - 1 ? dictionary[index] : dictionary[index + 1];
answer += '\n';
line += 1;
T -= 1;
}
answer = answer.trimEnd();
console.log(answer);
풀이 및 해설 ⇒ 메모리 초과
- 출력값 ⇒ 사전순으로 정렬 후 주어진 단어 다음에 나오는 단어
- 주어진 단어를 오름차순으로 정렬
- 순열을 이용해서 사전 순으로 정렬
- 해당 단어의 인덱스 출력
- 정렬된 배열에 인덱스 + 1 위치에 있는 단어 출력
