월별 잡은 물고기 수 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/293260

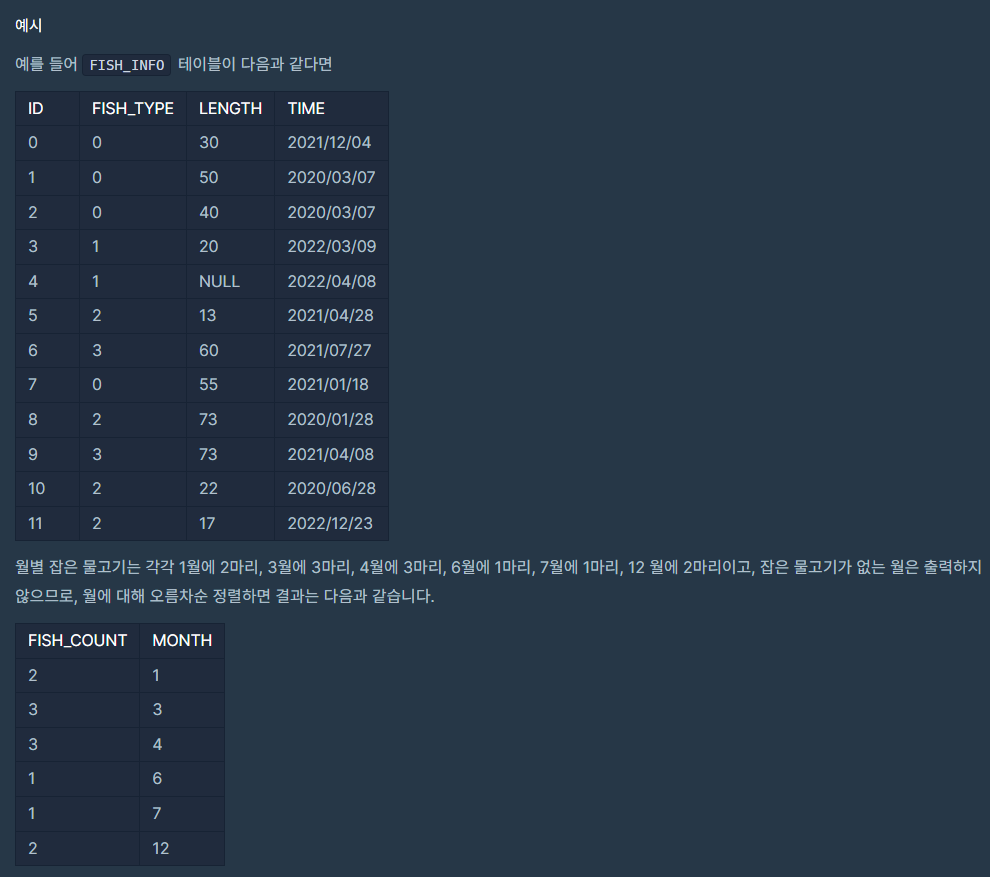
문제는 간단하다.
월별로 그룹화하여 잡은 물고기의 수를 카운트하여 출력한다.
SELECT
COUNT(ID) AS FISH_COUNT,
MONTH(TIME) AS MONTH
FROM
FISH_INFO
GROUP BY
MONTH(TIME)
ORDER BY
MONTH문제?
우선 GROUP BY절에 함수를 작성하여 그룹화하였다.
이 과정에서 데이터베이스는 TIME 컬럼의 모든 값을 스캔하고, 각각에 대해 MONTH() 함수를 실행한 후에 그 결과를 기반으로 그룹을 형성해야 한다.
이는 데이터셋이 큰 경우 상당한 처리 시간을 요구할 수 있다.
실제로 회사에서 약 1000만건 정도 결과 튜플이 생성되는 쿼리의 GROUP BY 절에 저런식으로 함수를 사용해서 그룹화한 적이 있었는데
읽기 과정에서 약 5초 정도 소요되었다. 1000만건 밖에 되지 않는데 5초라니.. 매우 느리다...
해결?
이런 경우에 간단한 방법으로 두 가지를 떠올려 볼 수 있다.
- MONTH 컬럼을 가지는 임시테이블을 생성하기
먼저 MONTH 컬럼을 가지는 임시테이블을 생성하고 그 임시 테이블의 MONTH 컬럼을 GROUP BY에 사용한다.
WITH MonthlyFishInfo AS (
SELECT
ID,
MONTH(TIME) AS MONTH
FROM
FISH_INFO
)
SELECT
COUNT(ID) AS FISH_COUNT,
MONTH
FROM
MonthlyFishInfo
GROUP BY
MONTH
ORDER BY
MONTH;- 인덱스 활용하기
TIME 컬럼에 인덱스를 걸어봐야 저런식으로 GROUP BY를 사용하면 아무 소용이 없다.
대신에 월만 있는 컬럼을 추가로 생성해서 해당 컬럼에 인덱스를 걸어준다면 좋은 성능을 낼 수 있을 것 같다.
정리
SQL 문제에 답 가지고 성능이 어떨 것 같다느니 하는 게 좀 이상한 것 같긴 한데 복기하는 겸 작성하였다.

백엔드 개발자