웹크롤링이란?
구글이나 네이버같은 검색엔진이 내 사이트를 퍼가는 행위
스크래핑이란?
웹페이지의(순위)목록정보 들을 스크랩해 오는 것.
(공부할 때, 스크래핑을 웹크롤링이라 지칭한다.)
크롤링을 위해서 필요한 2가지는?
request 로 정보목록을 요청하고
수많은 정보중에 필요한 것을 솎아내는 bs4(beautifulsoup)
*2가지 모두 설치 후 사용하기!
Beautifulsoup 으로 정보를 솎아내는 방법은
select_one 정보1개 솎아내기, select 정보 여러개 솎아내기
크롤링할 페이지 내의 원하는 정보(ex.타이틀) : Elements 에서 copy selector
ex. #old_content > table > tbody > tr:nth-child(2) > td.title > div > a
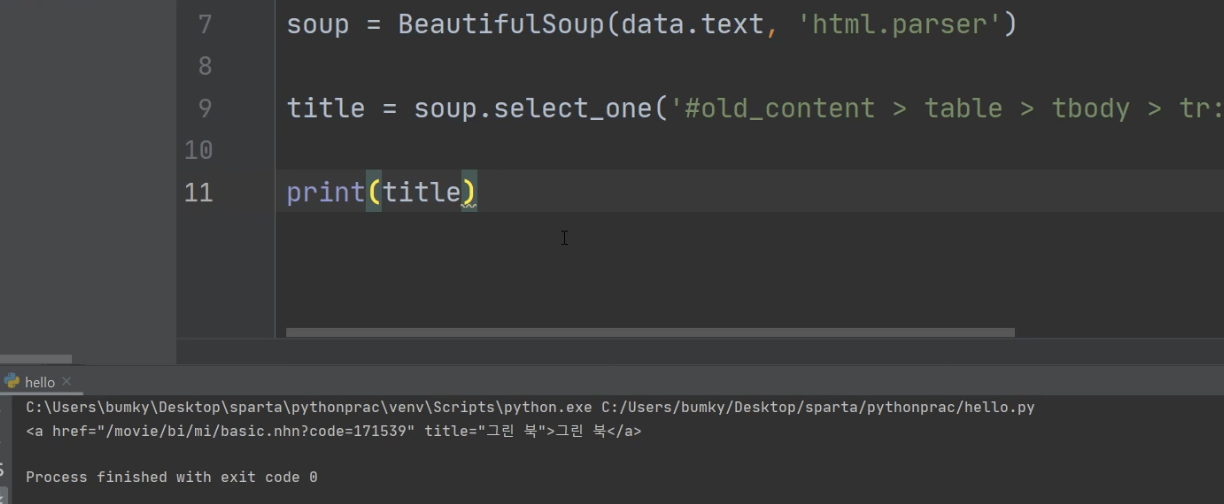
태그안의 글씨를 가져올 때는 .text
태그안의 속성을 가져올 때는 ['href']
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a)
print(title.text)
print(title['href']ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
파이썬에서 스크래핑 select로 list 가져올 때,
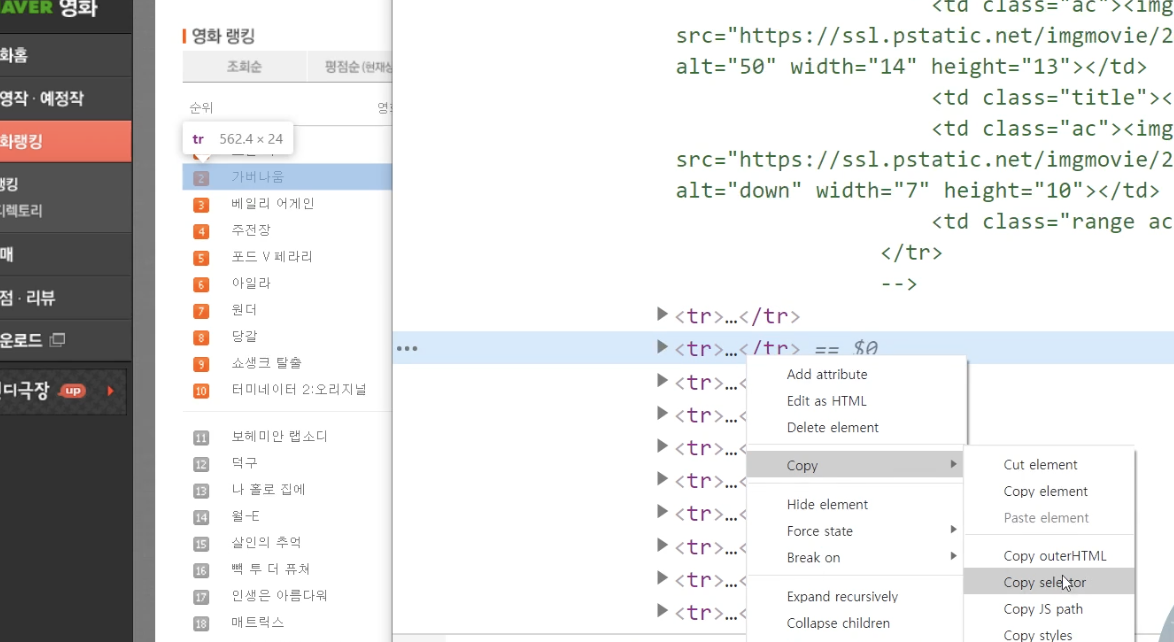

copy 한 부분의 다른곳(제일 마지막 값)을 제외한 공통된 부분만 가져오면 된다!
ex. #old_content > table > tbody > tr
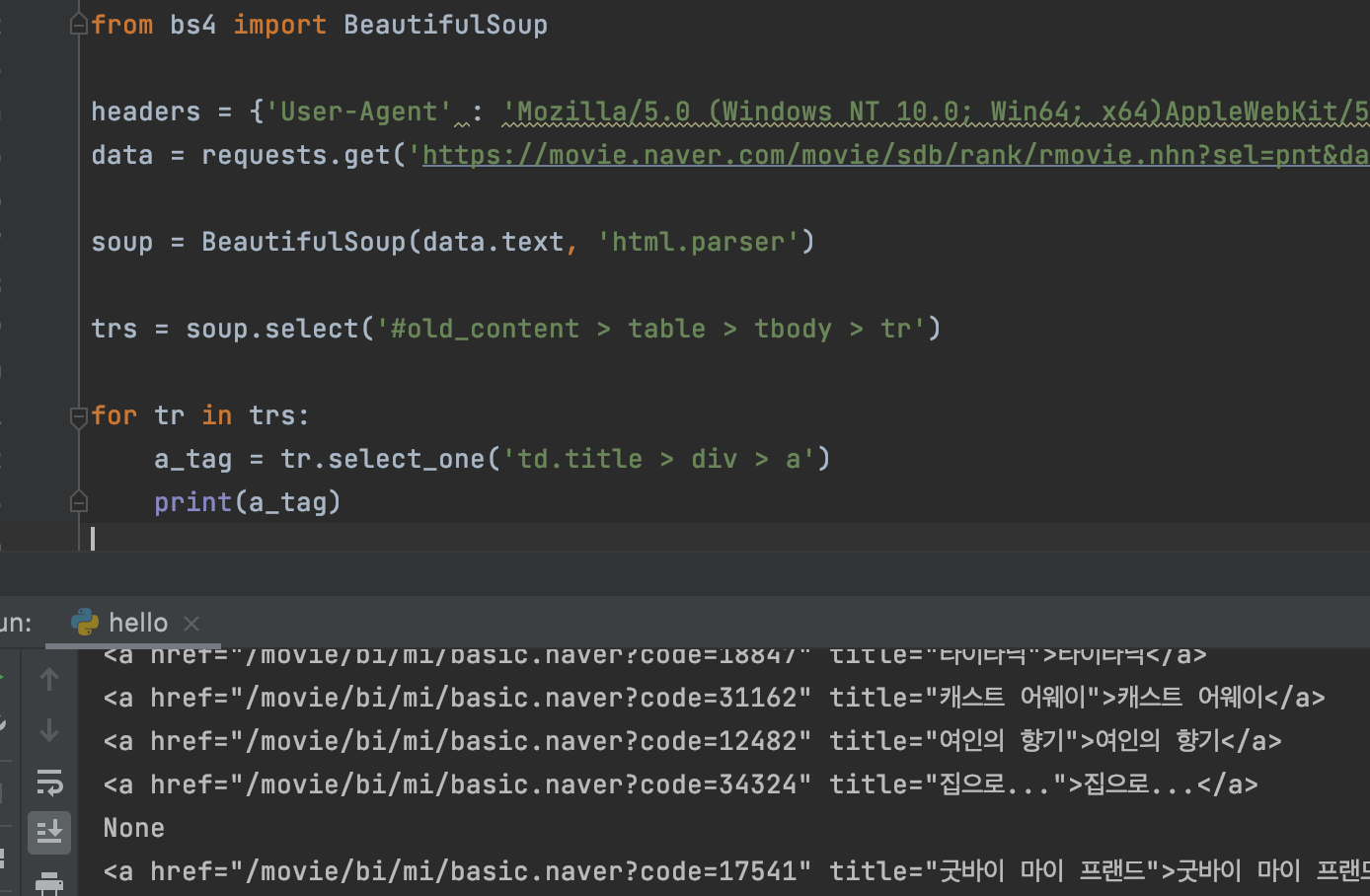
trs 의 tr 을 찍어보니 중간마다 나오는 None,
브라우저에서 보이는 중간 라인이다.

이 라인은 태그 안의 text 로 인식하지 않기 때문에,
print(a_tag.text) 라고 찍으면 오류발생!
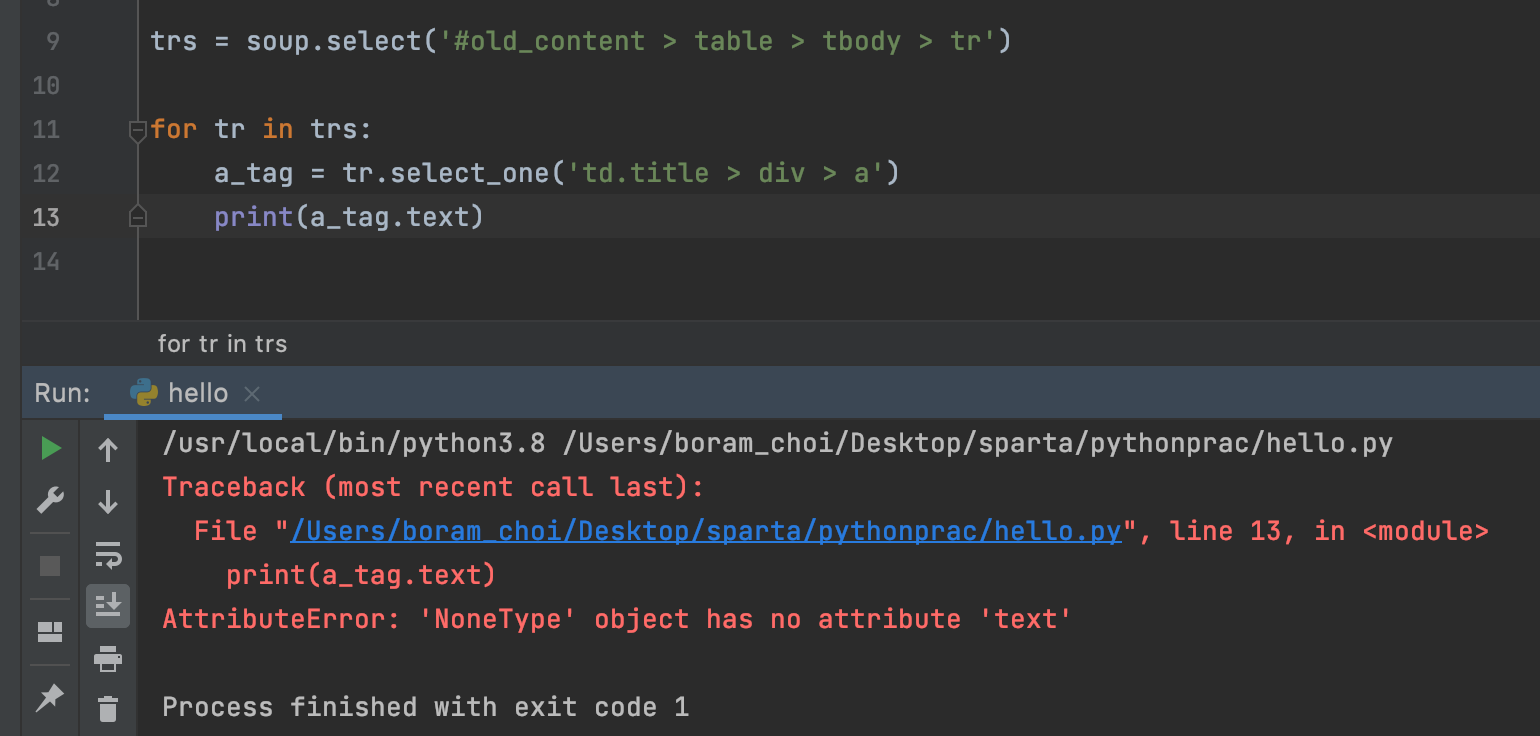
이때는 if 를 사용해서 None을 제외시킨 값을 출력한다
(파이썬에선 더 직관적인 if문)
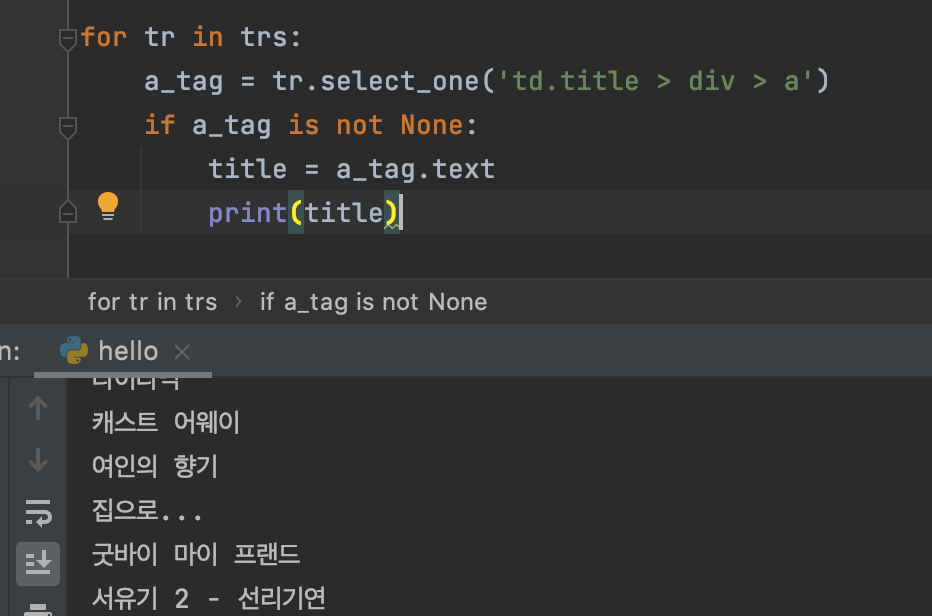
여기서 +
순위값과 별점까지 추가해서 뽑아온다면,
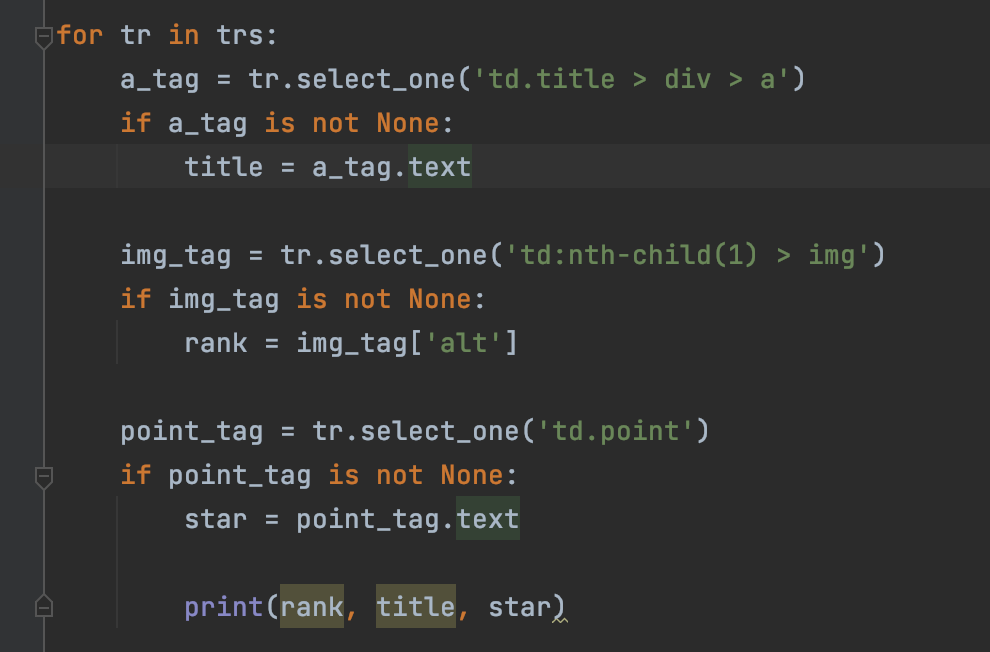
이렇게 따로따로 설정할 필요가 없었다!
제목(title)값 설정 > None 제외시키고 > 값 도출
순위(rank)값 설정 > None 제외시키고 > 값 도출
별점(star)값 설정 > None 제외시키고 > 값 도출
그럴 필요없이,

a_tag 에서 None 제외설정 아래로:
순위,타이틀,별점을 모두 가져오면 한번에 OK!
그런데 a_tag 는 title 이었는데?? 어떻게 순위와 별점에도 적용된걸까?
튜터님이 알려주신 설명첨부!!
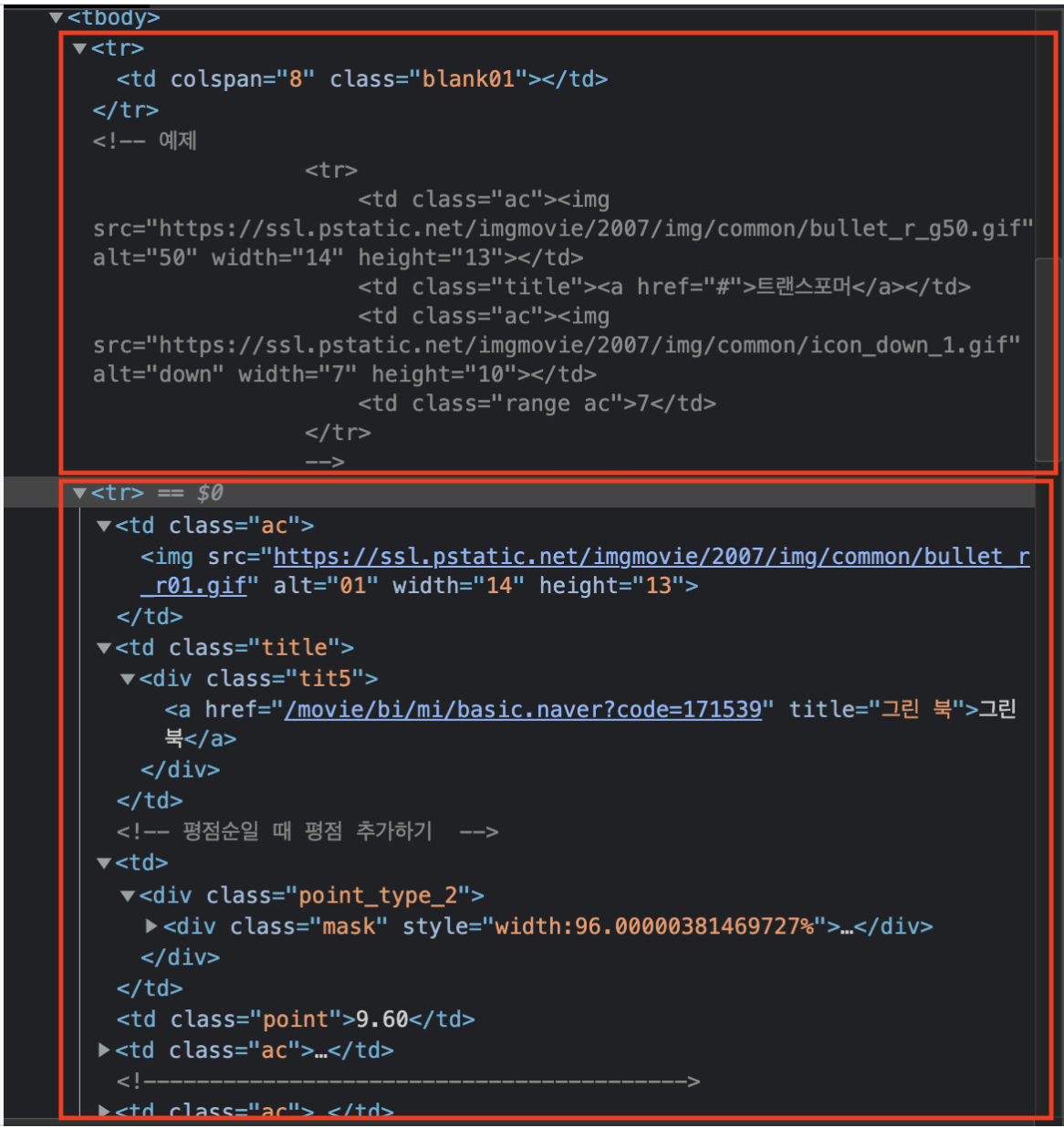
위의 빨간 네모칸을 보면, tr태그 하나씩을 구분해서 빨간칸을 그려주었는데요, 위쪽 네모칸은 tr 태그 안에 a태그가 없어요, 그리고 아래 tr은 a 태그가 있고 ‘그린북’이 들어가 있죠. 그리고 tr 안쪽으로 td태그들이 있어요, 그래서 a태그 하나로 정보들이 있는지 없는지를 구분해주고 있어요. 따라서 윗 네모칸처럼 아예 a가 없다면 if문으로 걸러지고, 그 아래 네모칸은 rank와 star를 불러오는거에요.
아하! 이해쏙쏙👍신기쓰방기쓰😁 감삼다!!!

mongoDB 는 데이터베이스. (컴퓨터에서 돌아가고 있지만, 눈에 보이지 X)
robo3T 는 mongoDB 데이터를 시각화 하는 프로그램. (제대로된 데이터작업확인을 위해)