캐시 메모리는 작고 빠른 메모리로 CPU의 메모리 프로세싱 병목 현상을 줄이도록 도와주는 역할을 한다.
CPU -> L1$(I & D) -> L2$ -> Main memory
위의 구조 순으로 접근하며, CPU와 가까울수록 접근 속도가 빠르다.
지역성
캐시는 시간 지역성(Temporal Locality)과 공간 지역성(Spatial Locality)라는 것을 활용한다.
시간 지역성 : 최근 접근한 데이터에 다시 접근할 가능성이 높다.
공간 지역성 : 접근한 데이터에 가까운 주소에 접근할 가능성이 높다.
for (i = 0; i < 10; i++)
sum += x[i] * y[i];위와 같은 코드가 있다라고 했을 때,
변수 sum은 루프가 실행되는 동안 계속해서 호출된다. (시간지역성)
배열 x와 y는 0번째 인덱스를 접근한 후에 다른 요소들까지 접근한다. (공간지역성)
자세한 것은 시간이 될 때 적도록 하겠다.
Fetch Flow
CPU가 메모리에 접근하면, 컨트롤러는 원하는 값이 캐시에 있는지 확인한다.
값(명령 또는 데이터)이 캐시에 있으면 "Cache Hit"가 발생하고, 값을 CPU로 전달한다.
반대로 원하는 값이 캐시에 없다면, "Cache Miss"가 발생하고,
캐시 컨트롤러는 다음 메모리 수준(접근순서는 맨 위에 기술)에서 값을 찾는다.
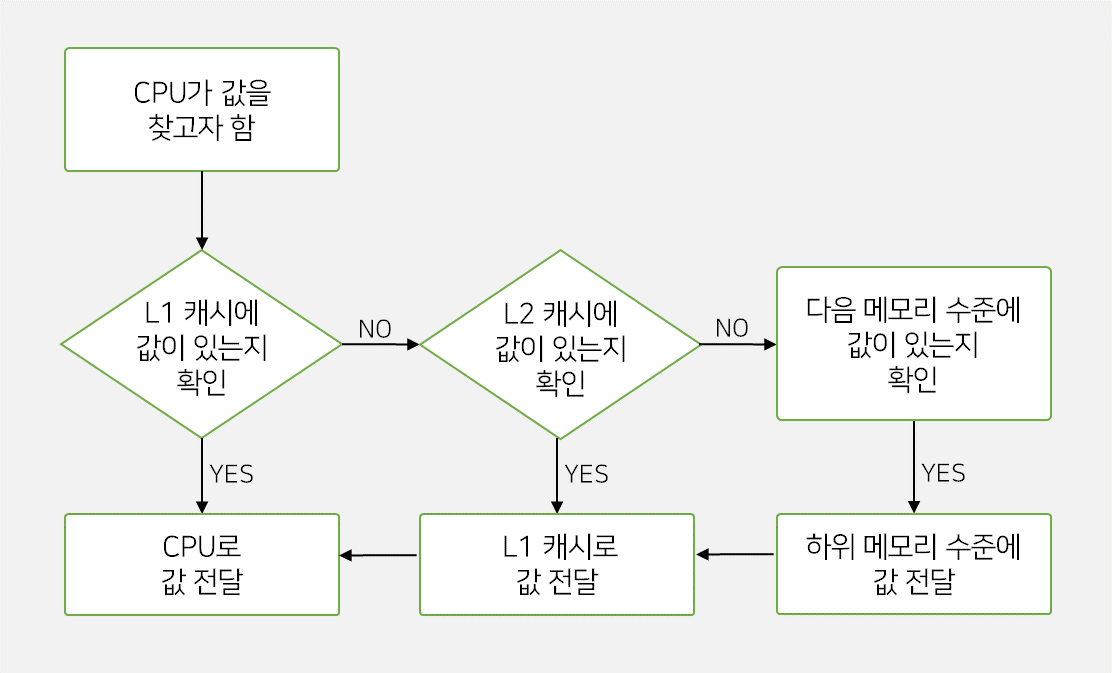
Cache Miss
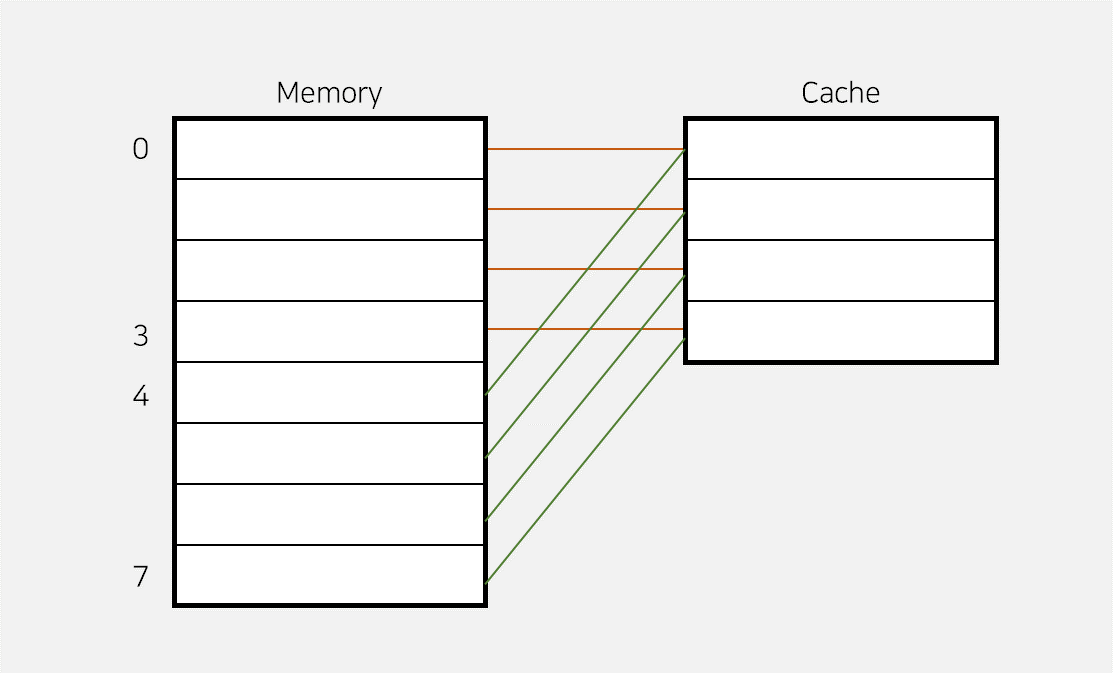
이 사진에서 0~3에 위치한 값들이 Cache에 채워져있다고 해보자.
이때 사용자가 4번째에 위치한 값을 원한다면, "Cache Miss"가 발생할 것이고 4~7에 위치한 값들을 Cache로 가져올 것이다. (공간지역성 때문)
이제 이 이후로 0번째 값과 4번째 값을 번갈아가면서 찾는다고 해보자.
그러면 계속 Cache Miss가 발생할 것이고, Update를 해줌으로써 발생하는 overhead가 추가적으로 발생할 것이다.
위와 같은 상황이 계속 된다면, 매우 좋지 않은 CPU 성능을 보일 것이다. (스레싱)
이러한 Cache Miss는 여러 코드 최적화 기법에 의해 줄일 수 있다.
Cache Miss 유형
Compulsory misses : "First-Reference Misses" 라고도 하며, 캐시 라인에 처음 액서스하는 동안 발생한다. 이는 파이프라인을 이용하여 최소화할 수 있다.
Capacity misses : 캐시에서 프로그램을 실행하는 동안 모든 데이터를 저장할 공간이 충분하지 않을 때 Miss가 발생한다. 더 적은 양의 데이터나 코드를 작업함으로써 줄일 수 있으며, 데이터 접근을 재정렬하거나 더 작은 조각으로 데이터를 분할하여 이를 달성할 수 있다.
Conflict misses : 여러 블록의 데이터 또는 프로그램 코드가 동일한 캐시 라인에서 경쟁하기 때문에 이러한 Miss가 발생한다. 데이터 또는 프로그램 코드의 주소를 변경함으로써 제거할 수 있으며 이를 통해 동일한 캐시 라인을 다투지 않는다.
Handling Cache Writes
캐시 메모리를 사용하게 되면 데이터의 값을 업데이트 했을 때, 메모리가 아닌 캐시 블록의 데이터가 업데이트된다. (캐시 데이터와 메모리 데이터가 달라짐)
그렇다면 캐시의 데이터를 메모리에 언제 쓰게 될까?
이에 대해선 2가지 쓰기 정책(Write Policies)이 존재한다.
Write-through 방식
캐시에 데이터가 작성될 때마다 메모리의 데이터도 같이 업데이트하는 방식이다.
이렇게 하면 메모리와 캐시의 데이터가 동일하게 유지될 수 있다는 장점이 있지만,
update를 자주하기 때문에 많은 트래픽이 발생하게 된다.
read 연산 - cache를 통해 빠르게 값을 찾을 수 있음.
write 연산 - CPU가 대기하는 시간이 필요하기 때문에 성능 저하가 발생.
이 방식은 write 연산이 자주 일어난다면 굉장히 비효율적이게 될 수 있다.
다만, 데이터 로스가 발생하면 안 되는 상황에서는 Write-through을 사용하는 것이 좋다.
Write-back 방식
CPU 데이터를 사용할 때, 데이터는 먼저 캐시에 기록된다. (dirty bit : 1)
그 후, 블록 단위로 캐시가 해제되는 시기에 dirty bit가 1이라면, 메모리의 데이터를 업데이트 해주는 방식이다.
장점 : 당연하게도 Write-Through 방식보다 훨씬 빠르다.
단점 : 캐시와 메모리가 서로 값이 다른 경우가 발생한다.
이 방식은 데이터 손실보다 빠른 서비스를 요하는 상황에서 사용하는 것이 좋다.
Reference
https://blog.naver.com/PostView.nhn?blogId=cjsksk3113&logNo=222251292946
https://akai-tenshi.tistory.com/archive/20201124
https://parksb.github.io/article/29.html
https://literate-t.tistory.com/73
http://blog.skby.net/%EC%A7%80%EC%97%AD%EC%84%B1-locality/
https://melonicedlatte.com/computerarchitecture/2019/02/12/203749.html
