class
- 변수, 함수를 묶어서 코드를 작성하는 방법
- 객체 지향 구현하는 문법
- 객체 지향 : 실제세계를 모델링하여 프로그램을 개발하는 개발 방법론 (협업을 용이하게 하기 위함)
함수 사용법
- 함수 선언(코드 작성) → 함수 호출(코드 실행)
클래스 사용법
- 클래스 선언(코드 작성) → 객체 생성(메모리 사용) → 메서드 실행(코드 실행)
- 클래스 선언(설계도 작성) → 객체 생성(제품 생산) → 메서드 실행(기능 사용)
식별자 컨벤션
- 변수, 함수 : snake_case
- 클래스 : PascalCase, UpperCamelCase
class 개념
classself사용자 정의 데이터 타입, special methods(__init__()__add__()…)상속supergetter-settermanglingmethods(instantclassstatic)
class 선언
- 코드 작성
# 계산기 설계 : Calculator : number1, number2, plus(), minus()
class Calculator:
number1, number2 = 1, 2
def plus(self):
return self.number1 + self.number2
def minus(self):
return self.number1 - self.number2# 객체생성 : 메모리사용
calc1 = Calculator()
calc2 = Calculator()[var for var in dir(calc1) if var[0] != '_']
# Terminal
['minus', 'number1', 'number2', 'plus']calc1.number1, calc1.number2
# Terminal
(1, 2)# 메서드실행 : 코드실행
calc1.plus(), calc1.minus()
# Terminal
(3, -1)# 객체의 변수 수정 : 데이터선택 = 수정할데이터
calc1.number1, calc1.number2, calc2.number1, calc2.number2
# Terminal
(1, 2, 1, 2)calc1.number1 = 20
calc1.number1, calc1.number2, calc2.number1, calc2.number2
# Terminal
(20, 2, 1, 2)calc1.plus(), calc2.plus()
# Terminal
(22, 3)dir()
- 객체에 들어있는 변수를 출력
self
- 객체 자신
# Calculator.plus() : self.number1 + self.number2
# calc1.plus() : self == calc1
# - self.number1 + self.number2 > calc1.number1 + calc1.number2# 클래스선언 : 은행계좌 : Account : balance, insert(), withdraw()
class Account:
balance = 0
def insert(self, amount):
self.balance += amount
def withdraw(self, amount):
if self.balance >= amount:
self.balance -= amount
else:
print(f'잔액이 {amount - self.balance}원 부족합니다.')# 객체생성
account_1 = Account()
account_2 = Account()
account_1.balance, account_2.balance
# Terminal
(0, 0)# 메서드실행
account_1.insert(10000)
account_1.balance, account_2.balance
# Terminal
(10000, 0)account_1.withdraw(15000)
account_1.balance, account_2.balance
# Terminal
잔액이 5000원 부족합니다.
(10000, 0)special methods
- 특별한 기능을 하는 메서드
- 앞 뒤로
__가 붙음
__init__()
- 생성자 메서드
- 객체를 생성할때 실행되는 메서드
- 변수의 초기값을 설정할때 주로 사용
- 불량 객체(메서드 사용 X)가 만들어질 확률을 줄여줌
# 클래스생성 : 설계도작성
class Account:
def __init__(self, balance=20000):
self.balance = balance
def insert(self, amount):
self.balance += amount
def withdraw(self, amount):
if self.balance >= amount:
self.balance -= amount
else:
print(f'잔액이 {amount - self.balance}원 부족합니다.')# 객체생성 : 메모리사용 : 자원사용
account = Account()# 메서드실행 : 코드실행 : 기능사용 : 불량품 생산
account.insert(3000)account.balance
# Terminal
23000# 클래스는 사용자 정의 데이터 타입이다.# account의 데이터 타입은 Account
# account 객체가 만들어진 클래스는 Account
# 데이터 타입 == 클래스 > 클래스는 데이터 타입이다.
# Account 클래스는 우리가 만듦 > 사용자 정의
# > 클래스는 사용자 정의 데이터 타입이다.
type(account)
# Terminal
__main__.Account# data의 데이터 타입은 list
# data 객체가 만들어진 클래스는 list
# list 클래스는 우리가 만들지 X
data = [1, 2, 3]
type(data)
# Terminal
list# account의 메서드는 Account 클래스에서 정의
# data의 메서드는 list 클래스에서 정의
[var for var in dir(account) if var[0] != '_']
# Terminal
['balance', 'insert', 'withdraw']# account.insert(), data.sort(), data.append()
# 데이터 타입의 메서드를 암기할 필요 X
print([var for var in dir(data) if var[0] != '_'])
# Terminal
['append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']help(data.pop)
# Terminal
Help on built-in function pop:
pop(index=-1, /) method of builtins.list instance
Remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.# 객체의 데이터 타입에 따라서 사용할수 있는 변수, 메서드가 다르다.
data1, data2 = 'python', [1, 2, 3]
print(type(data1), type(data2))
print([var for var in dir(data1) if var[0] != '_'])
print([var for var in dir(data2) if var[0] != '_'])
# Terminal
<class 'str'> <class 'list'>
['capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
['append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']# account : 클래스, 데이터타입 : Account : 사용자 정의 데이터 타입 O
# data1 : 클래스, 데이터타입 : str : 사용자 정의 데이터 타입 X
# data2 : 클래스, 데이터타입 : list : 사용자 정의 데이터 타입 X
type(account), type(data1), type(data2)
# Terminal
(__main__.Account, str, list)%whos
# Terminal
Variable Type Data/Info
------------------------------------
Account type <class '__main__.Account'>
Calculator type <class '__main__.Calculator'>
account Account <__main__.Account object at 0x7f5716177c70>
account_1 Account <__main__.Account object at 0x7f5716158f10>
account_2 Account <__main__.Account object at 0x7f5716158400>
arr ndarray 3: 3 elems, type `int64`, 24 bytes
calc1 Calculator <__main__.Calculator object at 0x7f571e6b1250>
calc2 Calculator <__main__.Calculator object at 0x7f571e6b1730>
data list n=3
data1 str python
data2 list n=3
np module <module 'numpy' from '/us<...>kages/numpy/__init__.py'>import numpy as np
arr = np.array([1, 2, 3])
type(arr)
# Terminal
numpy.ndarray__add__() 와 __str__()
__add__(): + 연산자 정의__str__():print()함수 실행 정의
# 데이터 타입에 따라서 수행되는 연산이 다르다.
d1, d2, d3, d4 = 1, 2, '3', '4'
d1 + d2, d3 + d4
# Terminal
(3, '34')# d1 + d2 : + 연산자 == d1.__add__() 실행
d1 + d2, d1.__add__(d2), d3 + d4, d3.__add__(d4)
# Terminal
(3, 3, '34', '34')# d1 + d2 : d1.__add__(d2) : d1.__add__() : int 클래스의 __add__() 메서드
# d3 + d4 : d3.__add__(d4) : d3.__add__() : str 클래스의 __add__() 메서드
# > 데이터 타입에 따라서 수행되는 __add__() 메서드가 다르다.d5, d6 = [1, 2], [3, 4]
d5 + d6
# Terminal
[1, 2, 3, 4]arr1 = np.array([1, 2])
arr2 = np.array([3, 4])
arr1 + arr2
# Terminal
array([4, 6])# dir(d1)# 덧셈연산을 하지만 뺄셈연산이 수행되는 객체를 생성
class Number:
def __init__(self, data):
self.data = data
def __add__(self, obj):
return self.data - obj.data
def __str__(self):
return str(self.data)
def __repr__(self):
return str(self.data)num1 = Number(10)
num2 = Number(3)
num1.data, num2.data
# Terminal
(10, 3)print(num1)
print(num2)
# Terminal
(10, 3)num1, num2
# Terminal
(10, 3)num1 + num2
# Terminal
7상속
- 다른 클래스의 변수(메서드)를 가져와서 사용하는 방법
# iPhone1 : call
# iPhone2 : call, send_msg
# iPhone3 : call, send_msg, internetclass iPhone1:
def call(self):
print('calling!')class iPhone2:
def call(self):
print('calling!')
def send_msg(self):
print('send_msg!')class iPhone3:
def call(self):
print('calling!')
def send_msg(self):
print('send_msg!')
def internet(self):
print('internet!')# 상속 사용
class iPhone1:
def call(self):
print('calling!')
class iPhone2(iPhone1):
def send_msg(self):
print('send_msg!')
class iPhone3(iPhone2):
def call(self):
print('video calling!')
def internet(self):
print('internet!')
# Terminal
iphone1 = iPhone1()
iphone2 = iPhone2()
iphone3 = iPhone3()def show_vars(obj):
return [var for var in dir(obj) if var[0] != '_'][var for var in dir(iphone3) if var[0] != '_']
# Terminal
['call', 'internet', 'send_msg']show_vars(iphone1), show_vars(iphone2), show_vars(iphone3)
# Terminal
(['call'], ['call', 'send_msg'], ['call', 'internet', 'send_msg'])iphone3.call()
# Terminal
video calling!다중 상속
class Human:
def walk(self):
print('walking!')
class Korean:
def eat(self):
print('eat kimchi!')
class Indian:
def eat(self):
print('eat curry!')# Human > Korean > Jin
class Jin(Korean, Human):
def skill(self):
print('coding')jin = Jin()
show_vars(jin)
# Terminal
['eat', 'skill', 'walk']# Human > Korean > Jin
class Anchel(Indian, Human):
def skill(self):
print('speak english!')anchel = Anchel()
jin.eat()
anchel.eat()
# Terminal
eat kimchi!
eat curry!decorator
- 함수에서 중복되는 코드를 빼서 데코레이터 함수로 만들어 코드를 작성하는 방법
- 원래있던 함수에 새로운 기능을 추가한 함수로 변경할 때 주로 사용
def func1():
print('code1')
print('code2')
print('code3')
def func2():
print('code1')
print('code4')
print('code3')def deco(func):
def wrapper(*args, **kwargs):
print('code1')
func() # == func1() : print('code2') : == func2() : print('code4')
print('code3')
return wrapper# deco 함수의 파라미터 func에 func1이 들어감
# func1 함수는 deco 함수의 return 함수인 wrapper 함수로 변경
@deco
def func1():
print('code2')
@deco
def func2():
print('code4')
func1()
func2()
# Terminal
code1
code2
code3
code1
code4
code3# timer 데코레이터 함수 생성
import time
def timer(func):
def wrapper(*args, **kwargs):
start = time.time() # 현재시간 저장
result = func(*args, **kwargs)
end = time.time() # 현재시간 저장
print(f'running time : {end - start} sec')
return result
return wrapper@timer
def plus(n1, n2):
return n1 + n2
def minus(n1, n2):
return n1 - n2plus(3, 2)
# Terminal
running time : 1.6689300537109375e-06 sec
5minus(3, 2)
# Terminal
1# 패스워드를 맞춰야 함수의 실행이 가능하도록 하는 데코레이터 작성
def admin(func):
def wrapper(*args, **kwargs):
pw = input('insert password : ')
if pw == 'python': # 패스워드 맞음
result = func(*args, **kwargs)
else: # 패스워드 맞지 않음
result = 'wrong password!'
return result
return wrapperdef plus(n1, n2):
return n1 + n2
@timer
@admin
def minus(n1, n2):
return n1 - n2%%time
plus(1, 2)
# Terminal
CPU times: user 5 µs, sys: 0 ns, total: 5 µs
Wall time: 9.54 µs
3minus(1, 2)
# Terminal
insert password : python
running time : 9.5367431640625e-07 sec
-1상관계수 ( Correlation Coefficient )
- numpy를 이용하여 데이터의 상관계수를 구하기
- python 코드와 numpy의 함수의 속도차이를 비교하기
import numpy as np샘플 데이터 생성
data1 = [80, 85, 100, 90, 95]
data2 = [70, 80, 100, 95, 95]
data3 = [100, 90, 70, 90, 80]분산(variance)
- 1개의 이산정도를 나타냄
- 편차제곱의 평균
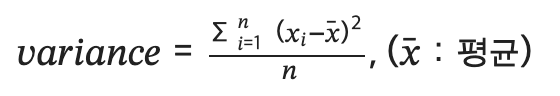
def variance(data):
var = 0
x_ = sum(data) / len(data)
for xi in data:
var += (xi - x_) ** 2
return var / len(data)data1, data2, data3
# Terminal
([80, 85, 100, 90, 95], [70, 80, 100, 95, 95], [100, 90, 70, 90, 80])variance(data1), variance(data2), variance(data3) # 분산
# Terminal
(50.0, 126.0, 104.0)variance(data1) ** 0.5, variance(data2) ** 0.5, variance(data3) ** 0.5 # 표준편차 (분산은 제곱으로 스케일이 커졌기에 루트로 줄여주는 것)
# Terminal
(7.0710678118654755, 11.224972160321824, 10.198039027185569)np.var(data1), np.var(data2), np.var(data3) # 넘파이를 통한 분산
# Terminal
(50.0, 126.0, 104.0)일반 함수와 numpy 함수의 퍼포먼스 비교
data = np.random.randint(0, 100, size=int(1E5)) # E는 10x10의 5승
len(data), data[:5]
# Terminal
(100000, array([94, 36, 0, 56, 70]))# 파이썬으로 계산한 속도
%%time
variance(data)
# Terminal
(100000, array([94, 36, 0, 56, 70]))# 넘파이로 계산한 속도
%%time
np.var(data)
# Terminal
CPU times: user 1.13 ms, sys: 9 µs, total: 1.14 ms
Wall time: 1.16 ms
833.6150025431공분산(covariance)
- 2개의 확률변수의 상관정도를 나타냄
- 평균 편차곱
- 방향성은 보여줄수 있으나 강도를 나타내는데 한계가 있음
- 표본데이터의 크기에 따라서 값의 차이가 큰 단점이 있음
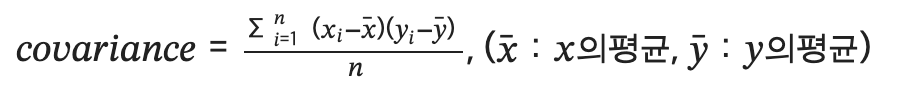
data1, data2, data3
# Terminal
([80, 85, 100, 90, 95], [70, 80, 100, 95, 95], [100, 90, 70, 90, 80])# - 1 : 자유도
def covariance(x, y):
cov = 0
x_ = sum(x) / len(x)
y_ = sum(y) / len(y)
for xi, yi in zip(x, y):
cov += (xi - x_) * (yi - y_)
return cov / (len(x) - 1)covariance(data1, data2), covariance(data1, data3)
# data1과 data2는 같은 방향으로 움직여 양의 상관관계 # data1과 data3는 음의 상관관계
# Terminal
(75.0, -70.0)np.cov(data1, data2)[0,1], np.cov(data1, data3)[0,1]
# Terminal
(93.75, -87.5)# 공분산의 한계 : 방향성은 보여줄 수 있으나, 강도는 보여줄 수 없음
data4 = [data * 10 for data in data1]
data5 = [data * 10 for data in data3]
data1, data3, data4, data5
# Terminal
([80, 85, 100, 90, 95],
[100, 90, 70, 90, 80],
[800, 850, 1000, 900, 950],
[1000, 900, 700, 900, 800])covariance(data1, data3), covariance(data4, data5)
# Terminal
(-70.0, -7000.0)상관계수(correlation coefficient)
-
공분산의 한계를 극복하기 위해서 만들어집니다.
-
1 ~ 1까지의 수를 가지며 0과 가까울수록 상관도가 적음을 의미합니다.
-
x의 분산과 y의 분산을 곱한 결과의 제곱근을 나눠주면 x나 y의 변화량이 클수록 0에 가까워집니다.
-
https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.corrcoef.html
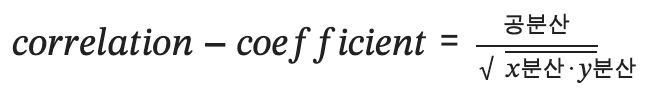
-
최종 상관 계수
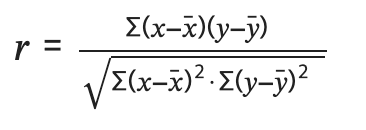
# 자유도를 제거한 covariance 써야 함
def covariance(x, y):
cov, x_, y_ = 0, sum(x) / len(x), sum(y) / len(y)
for xi, yi in zip(x, y):
cov += (xi - x_) * (yi - y_)
return cov / len(x)def cc(x, y):
cov = covariance(x, y)
var = (variance(x) * variance(y)) ** 0.5
return cov / vardata1, data2, data3, data4, data5
# Terminal
([80, 85, 100, 90, 95],
[70, 80, 100, 95, 95],
[100, 90, 70, 90, 80],
[800, 850, 1000, 900, 950],
[1000, 900, 700, 900, 800])# 1과 가까울수록 강한 양의 상관관계
# -1과 가까울수록 강한 음의 상관관계
# 0과 가까울수록 관계없음
cc(data1, data2), cc(data1, data3), cc(data4, data5)
# Terminal
(0.944911182523068, -0.970725343394151, -0.970725343394151)결정계수(cofficient of determination: R-squared)
- x로부터 y를 예측할수 있는 정도
- 상관계수의 제곱 (상관계수를 양수화)
- 수치가 클수록 회기분석을 통해 예측할수 있는 수치의 정도가 더 정확
cc(data1, data2) ** 2, cc(data1, data3) ** 2 # 제곱을 하니 - 를 제거해주는 효과가 남
# data3가 data2보다 data1과 더 강한 상관관계를 가지니 data1을 예측하려면 data3를 가지고 모델링하는 것이 더 좋겠다는 인사이트
# 방향성이 달라도 더 강한 관계를 갖기 때문
# Terminal
(0.8928571428571428, 0.9423076923076923)# 공분산 : 방향성 O, 강도 X
# 상관계수 : 방향성 O, 강도 O
# 결정계수 : 방향성 X, 강도 O
# 방향성만 알아야할때는 굳이 상관계수를 쓰는 것보다 공분산을 쓰는게 연산량이 줄기때문에 더 좋음import picklewith open('sales.pkl', 'rb') as file:
data = pickle.load(file)data.keys()
# Terminal
dict_keys(['meeting_count', 'meeting_time', 'sales'])data['meeting_count'][:5]
# Terminal
[230.1, 44.5, 17.2, 151.5, 180.8]data['meeting_time'][:5]
# Terminal
[69.2, 45.1, 69.3, 58.5, 58.4]data['sales'][:5]
# Terminal
[22.1, 10.4, 9.3, 18.5, 12.9]# 매출을 늘리기 위해서 미팅 횟수를 많이 갖는 것이 중요할까?
# 아니면 고객에게 상담 시간을 많이 할애하는 것이 좋을까?
안녕