CBD(Component-Based Development) 방법론을 기반으로 하는 SPA가 대중화되면서 Angular, React, Vue.js, Svelte 등 다양한 SPA 프레임워크/라이브러리 또한 많은 사용자 층을 확보하고 있다.
오랜만에 '모던 자바스크립트 Deep Dive'책을 읽다가 위 내용의 글을 읽고 나서, 내가 주로 사용하는 라이브러리인 React가 CBD 방법론을 기반으로 한다고 하여, CBD는 무엇인지에 대해 알아보고자 한다.
CBD 개발방법론
CBD 개발방법론(Component Based Development)이란 컴포넌트를 조합해 재사용함으로써 개발 생산성과 품질을 높이고 시스템 유지보수 비용을 최소화할 수 있는 개발방법론이다.
개요
: 소프트웨어를 독립적인 컴포넌트들로 나누어 개발하고, 이러한 컴포넌트들을 조합하여 완성된 소프트웨어를 만드는 방법.
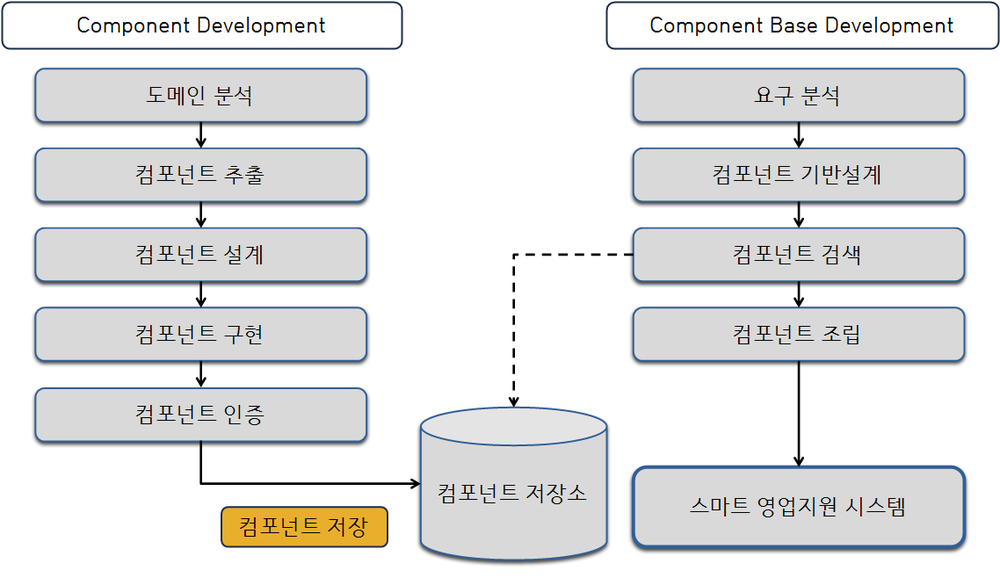
등장 배경
Component Based Development (CBD)는 1990년대 중반부터 등장한 개발 방법론으로, 기존의 소프트웨어 개발 방법론에서 발생하는 문제점들을 해결하고자 등장하였다.
기존의 소프트웨어 개발 방법론은 대부분 모놀리식(monolithic) 개발 방식을 사용하였다.
모놀리식(monolithic)
: 모놀리식(monolithic) 개발 방식은 소프트웨어를 전체적으로 하나의 큰 모듈로 개발하는 방식
- 소프트웨어를 개발하기 쉬운 방식으로, 초기 소프트웨어 개발에 많이 사용.
- 소프트웨어가 복잡해질수록 유지보수가 어렵고, 기능 추가나 변경이 어려움.
- 소프트웨어 전체의 장애나 버그가 발생 시, 시스템 전체가 영향을 받아 전체적인 안정성이 낮아지는 문제점.
CBD는 이러한 문제점들을 해결하기 위해 소프트웨어를 재사용 가능한 컴포넌트로 분해하여 개발하는 방식을 제안하였고 아래와 같은 이점을 얻었다.
- 개발 기간 단축
- 개발 비용 단축
- 시스템의 유지보수성 향상
- 시스템의 품질 향상
컴포넌트
: 소프트웨어에서 특정 기능을 수행하는 데 필요한 코드와 자원들을 묶어서 재사용 가능한 단위로 만든 것이다. 독립적으로 동작 가능한 소프트웨어 모듈로, 다른 소프트웨어에서 재사용할 수 있다.
CBD 방법론 핵심
: 소프트웨어를 독립적인 컴포넌트들로 나누어 개발하고, 이러한 컴포넌트들을 조합하여 완성된 소프트웨어를 만드는 것이다.이러한 방법으로 소프트웨어를 개발하면, 각 컴포넌트가 재사용 가능하며, 독립적으로 테스트할 수 있어야 한다.
CBD의 장점으로는 재사용성과 유지보수 용이성이다. 각 컴포넌트가 독립적으로 개발되기 때문에, 한 번 개발된 컴포넌트는 다른 시스템에서도 사용될 수 있으며, 시스템에 변경이 필요할 때도 해당 컴포넌트만 수정하면 된다. 이러한 장점으로 인해 개발 생산성이 증가하고, 시스템의 품질도 향상된다.
하지만 CBD 방법론을 적용할 때에는 컴포넌트의 구조와 인터페이스, 컴포넌트들 간의 상호작용 등을 신중하게 설계해야 하며, 컴포넌트의 선택과 구성에 따라 시스템의 성능과 안정성에 영향을 미칠 수 있기 때문에, 적절한 컴포넌트를 선택하고 테스트해야 한다.
리액트로 사고하기
프런트엔드에서 컴포넌트는 사용자와의 인터렉션을 통해 필요한 비즈니스 로직을 실행하거나 스타일, 애니메이션과 같은 시각적인 부분을 표현하는 UI(User Interface)를 적절하게 나눈 것입니다.
- React 컴포넌트와 추상화 - Kakako FE 기술블로그
이제 우리는 개발 방법론을 통해 CBD가 무엇인지 알게 되었다(?). 어찌보면 리액트와 많이 닮아 있어서 익숙한 느낌이어서 새로 알게 된 것은 크게 없을지도 모른다. 그렇지만, SPA(Single Page App.)는 CBD(Component Based Dev.)를 기반으로 하고 있고, 리액트는 SPA를 위한 라이브러리이니, 결론은 리액트가 객체 지향 방법론 중에서 컴포넌트 베이스 개발 방법론으로 만들어졌다는 것을 알게되었다. 공식 문서에서 리액트에 대해서 생각해보는 문서가 있는데 이것을 보면서 CBD와의 연관성을 지어볼 수 있으면 좋겠다.
1단계: UI를 컴포넌트 계층 구조로 나누기
: 모든 컴포넌트(와 하위 컴포넌트)의 주변에 박스를 그리고 그 각각에 이름을 붙이기.
새 함수 또는 개체를 만들어야 하는지 여부를 결정하는데 사용하는 기술 중 '단일 책임 원칙'을 사용한다. 즉 구성 요소는 이상적으로는 한 가지 작업만 수행해야 한다.
JSON이 잘 구조화되어 있으면 자연스럽게 UI의 구성 요소 구조에 매핑되는 경우가 많고, UI와 데이터 모델은 종종 동일한 정보 아키텍처, 동일한 형태를 갖는다.
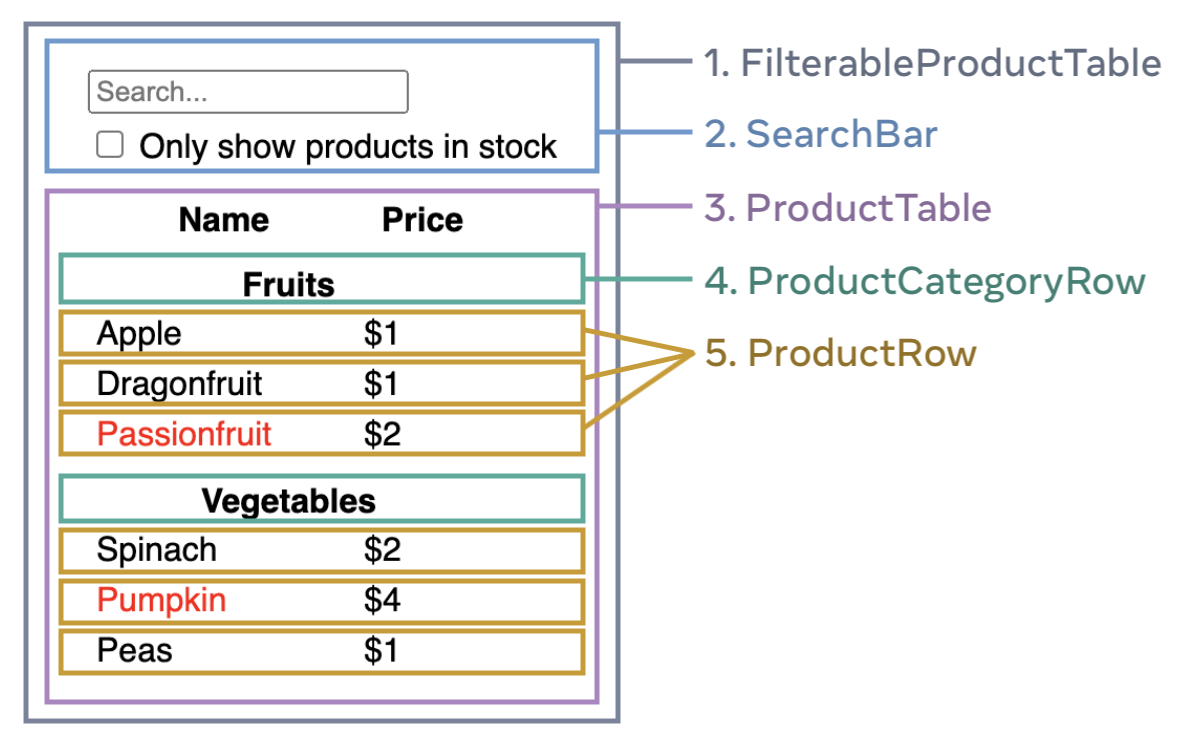
- FilterableProductTable(노란색): 예시 전체를 포괄
- SearchBar(파란색): 모든 유저의 입력(user input)을 받는다.
- ProductTable(연두색): 유저의 입력(user input)을 기반으로 데이터 콜렉션(data collection)을 필터링 해서 보여준다
- ProductCategoryRow(하늘색): 각 카테고리(category)의 헤더를 보여준다.
- ProductRow(빨강색): 각각의 제품(product)에 해당하는 행을 보여준다.
2단계: React로 정적인 버전 만들기
: props를 통해서 데이터 전달하면서 정적인 버전 만들기.
이제 컴포넌트 계층구조가 있으므로 앱을 구현할 차례이다. 가장 쉬운 방법은 데이터 모델을 가지고 UI를 렌더링은 되지만 아무 동작도 없는 버전을 만들어보는 것이다.
데이터 모델을 렌더링하는 앱의 정적 버전을 만들기 위해 다른 컴포넌트를 재사용하는 컴포넌트를 만들고 props 를 이용해 데이터를 전달하도록 한다. props는 부모가 자식에게 데이터를 넘겨줄 때 사용할 수 있는 방법이다.
[주의]
정적 버전을 만들기 위해 state를 사용하지 않도록 한다. state는 오직 상호작용을 위해, 즉 시간이 지남에 따라 데이터가 바뀌는 것에 사용한다.
이 단계가 끝나면 데이터 렌더링을 위해 만들어진 재사용 가능한 컴포넌트들의 라이브러리가 생긴다. 데이터가 최상위 구성 요소에서 트리 맨 아래에 있는 구성 요소로 흐르기 때문에 이를 단방향 데이터 흐름(one-way data flow) (또는 단방향 바인딩(one-way binding)) 이라고 한다.
3단계: UI state에 대한 최소한의 (하지만 완전한) 표현 찾아내기
: 중복배제원칙을 이용하여 state를 만들기
UI를 상호작용하게 만들려면 기반 데이터 모델을 변경할 수 있는 방법이 있어야 한다. React는 state를 통해 변경한다.
애플리케이션을 올바르게 만들기 위해서는 애플리케이션에서 필요로 하는 변경 가능한 state의 최소 집합을 생각해보아야 한다. 여기서 핵심은 중복배제원칙이다.
중복배제원칙
DRY(Don't Repeat Yourself) 원칙은 소프트웨어 개발에서 중복을 배제하고 코드의 재사용성을 높이기 위한 원칙입니다. 이 원칙은 "어떠한 정보나 지식은 시스템 내에서 단일하고 일관된 방식으로 표현되어야 한다"는 것을 의미합니다.
애플리케이션이 필요로 하는 가장 최소한의 state를 찾고 이를 통해 나머지 모든 것들이 필요에 따라 그때그때 계산되도록 만들어야 한다.
- props를 통해 전달되는 것은 state가 되면 안된다.
- state의 조합으로 계산할 수 있는 것 또한 state가 되어서는 안된다.
- 시간이 지나도 변하지 않는 것은 state가 되어서는 안된다.
4단계: State가 어디에 있어야 할 지 찾기
: 만들 state가 있어야 할 위치를 정하기
다음으로는 어떤 컴포넌트가 state를 변경하거나 소유할지 찾아야 한다. React는 항상 컴포넌트 계층구조를 따라 아래로 내려가는 단방향 데이터 흐름을 따른다.
- state를 기반으로 렌더링하는 모든 컴포넌트를 찾기.
- 공통 소유 컴포넌트 (common owner component)를 찾기.(계층 구조 내에서 특정 state가 있어야 하는 모든 컴포넌트들의 상위에 있는 하나의 컴포넌트)
- 공통 혹은 더 상위에 있는 컴포넌트가 state를 가져야 한다.
- state를 소유할 적절한 컴포넌트를 찾지 못하였다면, state를 소유하는 컴포넌트를 하나 만들어서 공통 소유 컴포넌트의 상위 계층에 추가하기.
5단계: 역방향 데이터 흐름 추가하기
: 자식 컴포넌트에서 부모 컴포넌트의 state 변환하는 방법
리액트에서 역방향 데이터 흐름은 자식 컴포넌트에서 부모 컴포넌트로 데이터를 전달하는 것을 의미한다. 역방향 데이터 흐름을 사용하면 자식 컴포넌트가 직접 상태를 변경하는 것이 아니라, 부모 컴포넌트의 상태를 업데이트하도록 할 수 있다.
역방향 데이터 흐름을 사용하면 상위 컴포넌트에서 하위 컴포넌트로 데이터를 전달하는 것보다 더 많은 제어를 할 수 있다. 이를 통해 데이터의 유효성 검사나 변경 로직을 부모 컴포넌트에서 처리할 수 있으며, 하위 컴포넌트는 단순히 전달받은 메서드를 호출하여 데이터를 업데이트할 수 있다.
너무 많이 사용하면 컴포넌트 간의 의존성이 높아져서 유지보수가 어려워질 수 있다. 역방향 데이터 흐름을 사용할 때는 필요한 경우에만 사용하고, 컴포넌트 간의 의존성을 최대한 낮추는 것을 선호한다.
오랜만에 모던 JavaScript 책을 다시 보면서 느낀 것이지만 책에서 알려주는 내용은 생각보다 내가 보는 것보다 더 많은 내용을 담고 있다는 것을 한번 더 느꼈다. CBD라는 것을 처음 알게 되었을 때, 왜 만들어졌는지만 알려고 했는데 공부를 하다보니 리액트가 객체지향 방법론을 베이스에 두고 있다는 것을 알게 되었고 객체지향에 대해 더 깊게 할애하도록 노력해야겠다고 생각이 들었다.
리액트를 처음 배우던 때에 리액트 문서를 전부 다 읽었는데, 그때 읽은 것에 비해 지금 다시 읽어보니 리액트 공식 문서는 공식 문서 중에서도 지나치게 친절함이 보이는 것 같다. 시간이 나면 다시 읽으면서 생각을 정리하도록 해야겠다.
