NL조인
NL 조인, 소트머지 조인, 해시 조인 모두 데이터를 가공하는 방법의 차이가 있을 뿐이지 기본적인 조인 프로세싱은 다르지 않다. <2중 루프 구조>
기본 메커니즘
NL조인은 기본적으로 인덱스를 이용하는 조인이기 때문에 인덱스 구성이 중요하다.
- 일반적으로 NL 조인은 Outer와 Inner 양쪽 테이블 모두 인덱스를 사용한다. Outer 쪽 테이블은 사이즈가 크지 않으면 인덱스를 이용하지 않을 수 있다. Table Full Scan을 하더라도 그것은 한 번에 그치기 때문이다.
- NL조인 과정
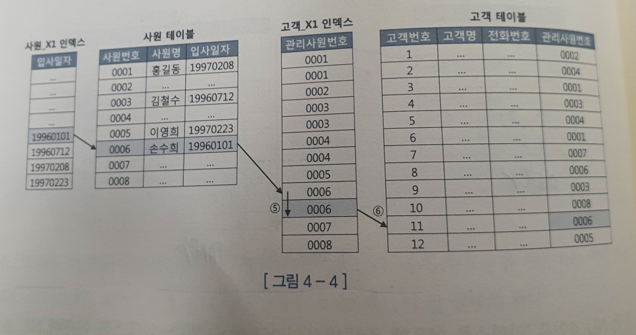
select e.사원명, c.고객명, c.전화번호 from 사원 e, 고객 c where e.입사일자 >= '19960101' and c.관리사원번호 = e.사원번호- 사원_X1 인덱스에서 입사일자 >= '19960101'인 첫 번째 레코드 탐색
- 인덱스에서 읽은 ROWID로 사원 테이블 레코드를 찾아간다.
- 사원 테이블에서 읽은 사원번호 '0006'으로 고객_X1 인덱스를 탐색한다.
- 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블 레코드를 찾아간다.
- 258쪽 사진 첨부
NL 조인 실행계획 제어
- 위쪽 사원 테이블 기준으로 아래쪽 고객 테이블과 NL조인하는 실행 계획

- NL 조인을 제어할 때는 아래와 같이 use_nl 힌트를 사용
- ordered 힌트는 FROM 절에 기술한 순서대로 조인하라고 옵티마이저에 지시
- A -> B -> C -> D순으로 조인하되 B, C는 NL 방식으로, D는 해시 방식
select /*+ ordered use_nl(B) use_nl(C) use_hash(D) */ * from A, B, C, D- leading 힌트는 기술한 순서대로 조인하라고 옵티마이저 지시(from 절과 상관X)
- C -> A -> D -> B순으로 조인하되 A, D는 NL 방식으로, B는 해시 방식
select /*+ leading(C, A, D, B) use_nl(A) use_nl(D) use_hash(B) */ * from A, B, C, D- 아무런 힌트를 기술 하지않으면 옵티마이저가 스스로 정한다.
- ordered 힌트는 FROM 절에 기술한 순서대로 조인하라고 옵티마이저에 지시
NL 조인 수행 과정 분석
select /*+ ordered use_nl(c) index(e) index(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문번호
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000-
인덱스 구성
- 사원_PK : 사원번호
- 사원_X1 : 입사일자
- 고객_PK : 고객번호
- 고객_X1 : 관리사원번호
- 고객_X2 : 최종주문금액
-
실행계획
-
실행 순서
- 3 -> 2 -> 5 -> 4 -> 1
- 입사일자 >= '19960101'조건을 만족하는 레코드를 찾으려고 사원_X1 인덱스를 Range 스캔하다.
- 찾은 ROWID로 부서코드 = 'Z123'로 필터링
- 사원 테이블에서 읽은 사원번호 값으로 조인 조건(c.관리사원번호 = e.사원번호)를 만족하는 고객 쪽 레코드를 찾으려고 고객_X1 인덱스 Range 스캔한다.
- 고객_X1 인덱스에서 읽은 ROWID로 고객 테이블을 액세스해서 최종주문금액 >= 20000 필터 조건을 만족하는지 확인한다.
- 3 -> 2 -> 5 -> 4 -> 1
NL조인 튜닝 포인트
- 첫번째 튜닝 포인트는 사원_X1 인덱스를 읽고 나서 사원 테이블을 액세스 하는 부분
- 입사일자를 >= 조건으로 스캔 후 랜덤 액세스를 통해서 테이블 액세스를 하고 부서코드로 필터링을 한다. 부서코드에 의해서 필터링되는 부분이 높다면 부서코드를 인덱스에 추가시키는 방법을 고려해야한다.
- 두번째 튜닝 포인트는 고객_X1 인덱스를 탐색하는 부분이다.
- 고객_X1 인덱스를 탐색하는 횟수. 즉, 조인 액세스 횟수가 많을 수록 성능이 느려진다. 조인 액세스 횟수는 Outer 테이블인 사원을 읽고 필터링한 결과 건수에 의해 결정된다.
- 고객_X1 인덱스를 읽고 나서 고객 테이블을 액세스하는 부분이다.
- 최종주문금액 >= 20000 조건에 의해 필터링되는 비율이 높다면 고객_X1 인덱스에 최종주문금액 컬럼을 추가하는 방안을 고려해야 한다.
- 맨 처음 액세스하는 사원_X1 인덱스에서 얻은 결과 건수에 의해 전체 일량이 좌우된다
- 맨 처음 액세스하는 사원_X1 인덱스를 줄이는 것이 가장 효율적이다.
- 온라인 트랜잭션 처리(OLTP) 시스템에서 튜닝할 때는 일차적으로 NL조인부터 고려해야한다.
- NL조인은 인덱스를 사용하기 때문에 대용량 데이터에서 소량의 데이터를 뽑아는 OLTP에 적합하다.
NL조인 특징 요약
NL 조인의 첫 번째 특징은 랜덤 액세스 위주의 조인 방식
- 레코드 하나를 읽으려고 블록을 통째로 읽는 랜덤 액세스 방식이라서 대량 데이터 조인에서 비효율적
한 레코드씩 순차적으로 진행한다는 점
- 테이블이 아무리커도 부분범위 처리가 가능하다면 NL조인은 빠른 응답이 가능하다.
NL 조인은 인덱스에 영향을 많이 받기 때문에 인덱스 구성 전략이 매우 중요하다.
- 조인 컬럼에 대한 인덱스가 있는지 없는지, 있다면 컬럼이 어떻게 구성됐는지 조인 효율이 달라진다.
NL조인 튜닝 실습
select /*+ ordered use_nl(c) index(e) index(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문번호
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- SQL 트레이스

-
사원_X1 인덱스를 스캔하고서 사원 테이블을 액세스한 횟수가 2,780인데, 테이블에서 부서코드 = 'Z123'조건을 필터링한 결과는 세건
- 불필요한 테이블 액세스를 많이 한 결과이고 테이블 액세스 후 필터링 된 비율이 높다면 인덱스에 테이블 필터 조건 컬럼을 추가하는 것을 고려할 필요가 있다.
-
입사일자와 부서코드로 인덱스를 구성했을 경우
-

-
논리적인 블록 요청 횟수(cr), 디스크에서 읽은 블록 수(pr), 디스크에 쓴 블록 수(pw)
-
사원_X1 인덱스로 부터 읽은 블록 102이고 한 블록에 평균 500개의 레코드가 있다고 하면 인덱스에서 세 건의 ROW를 얻기 위해서 50000개의 레코드를 읽은 것이다.
-
-
사원_X1 인덱스 컬럼 순서를 조정해 [부서코드 + 입사일자]로 구성하여 튜닝하는 것이 옳은 방법이다
- 하지만 인덱스 구성을 변경하면 다른 쿼리에 미치는 영향도도 고려해야하기 때문에 전체적인 액세스 유형을 분석해서 결정 해야한다.
-
부하지점 찾기

- 사원 테이블에서 인덱스 스캔 과정에서 블록은 4개이고 테이블 액세스 후 필터링되는 데이터도 없기 때문에 비효율적인 부분은 없다. 하지만 2,780번 조인 시도를 했지만 조인에 성공하고 필터링까지 마친 최종 결과 집합은 다섯 건뿐이다.
조인 순서 변경을 통해서 고객 테이블의 테이터를 먼저 액세스하고 사원 테이블 INNER JOIN으로 사용하는 방법이 있다. 조인 순서 변경 후 별 소득이 없다면 소트 머지 조인과 해시 조인 검토
NL조인 확장 메커니즘
NL조인 성능을 높이기 위해 테이블 Prefetch, 배치 I/O 기능 도입
- 테이블 Prefetch는 인덱스를 이용해 테이블을 액세스하다가 디스크 I/O가 필요해지면, 곧 읽게 될 블록까지 미리 읽어서 버퍼캐시에 적재하는 기능이다.
- 배치 I/O는 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리하는 기능
-
전통적인 실행계획
-
테이블 Prefetch 실행계획

- Inner 쪽 테이블에 대한 디스크 I/O 과정에 테이블 Prefetch 기능이 작동
-
배치 I/O 실행계획

- Inner 쪽 테이블에 대한 디스크 I/O 과정에 배치 I/O 기능이 작동

- Inner 쪽 테이블 블록을 모두 버퍼캐시에서 읽는다면 어떤 방식으로 수행하든 성능에 차이가 없다. 데이터 출력도 100% 같다. 즉, 버퍼캐시에서 읽는다면 성능은 동일하다.

- NL 조인 결과집합이 항상 일정한 순서로 출력되기를 원한다면, 배치 I/O기능이 작동하지 못하도록 no_nlj_batching(b) 힌트를 추가하거나, 아래와 같이 맨 바깥쪽 ORDER BY 절에 정렬 기준을 명시해야한다.
- 또한, 바깥쪽에 ORDER BY를 추가했어도 안쪽 ORDER BY를 함부로 제거해서는 안된다.
- Top N 쿼리를 구현하기 위한 것
NL 조인 튜닝 실습
select *
from TEST1 A, TEST 2 B
where A.ORG_ID = :ORG_ID
and A.GRP_ID = B.GRP_ID
and A.STRD_ID = B.STRD_ID
ORDER BY A.STC_DT DESC- 요청 인덱스
- ORG_ID + GRP_ID + STRD_ID + STC_DT
- 잘못된 점
- INNER 테이블 alias를 왼쪽에 기술 해야한다.
소트머지조인
오라클 서버 프로세스는 SGA에 공유된 데이터를 읽고 쓰면서, 동시에 자신만의 고유 메모리 영역(PGA)을 갖는다.
SGA와 PGA
- SGA(Shared Global Area)는 공유 메모리 영역이고 캐시된 데이터는 여러 프로세스가 공유할 수 있다. 하지만 동시에 액세스할 수는 없다.
- 동시에 액세스하려는 프로세스 간 액세스를 직렬화하기 위한 Lock 메커니즘으로 래치를 사용한다.
- 데이터 블록과 인덱스 블록을 캐싱하는 DB 버퍼캐시는 SGA의 가장 핵심적인 구성요소이며, 여기서 블록을 읽으려면 버퍼 Lock도 얻어야한다.
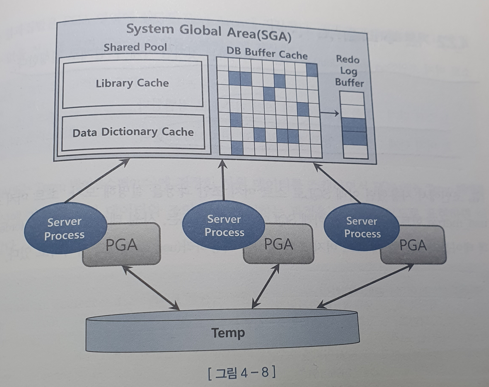
- PGA(Process Global Area)는 다른 프로세스와 공유하지 않는 독립적인 메모리 공간이므로 래치 메커니즘이 불필요하다. 같은 양의 데이터를 읽더라도 SGA 버퍼 캐시에서 읽을 때보다 빠르다.
- 할당받은 PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블스페이스를 이용한다.
기본 메커니즘
- 소트 단계: 양쪽 집합을 조인 컬럼 기준으로 정렬
- 머지 단계: 정렬한 양쪽 집합을 서로 머지
select /*+ ordered use_merge(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문번호
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- 수행과정
- 조인 컬럼인 사원번호 순으로 정렬한다. 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장한다. 정렬한 결과집합이 PGA에 담을 수 없을 정도로 크면, Temp 테이블스페이스에 저장한다.
select
사원번호, 사원명, 입사일자,
from 사원
where e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
ordery by 사원번호- 조인 컬럼인 관리사원번호 순으로 정렬한다. 정렬한 결과집합은 PGA 영역에 할당된 Sort Area에 저장한다. 정렬한 결과집합이 PGA에 담을 수 없을 정도로 크면, Temp 테이블스페이스에 저장한다.
select
고객번호, 고객명, 전화번호, 최종주문금액, 관리사원번호
from 고객
where 최종주문금액 >= 20000
ordery by 관리사원번호- PGA에 저장된 사원 데이터를 스캔하면서 PGA에 저장한 고객 데이터와 조인한다.
소트 머지 조인이 빠른 이유
- 소트 머지 조인은 Sort Area에 미리 정렬해 둔 자료구조를 이용한다는 점만 다를 뿐 조인 프로세싱 자체는 NL조인과 같다 하지만 소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합을 일곽적으로 읽어 PGA에 저장한 후 조인한다.
- PGA는 프로세스만을 위한 독립적인 메모리 공간이라서 데이터를 읽을 때 래치 획득 과정이 없다.
소트 머지 조인의 주용도
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인
- 조인 조건식이 아예 없는 조인(Cross Join)
소트 머지 조인 제어하기
-

-
양쪽 테이블을 각각 소트한 후, 위쪽 사원 테이블 기준으로 아래쪽 고객 테이블과 머지 조인
-
소트 머지 조인 쿼리
- 양쪽 테이블 조인 컬럼 순으로 각각 정렬한 후 정렬된 사원 기준으로 정렬된 고객과 조인하라
select /*+ ordered use_merge(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문번호
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000소트 머지 조인 특징 요약
- 소트 머지 조인은 조인을 위해 실시간으로 인덱스를 생성한다.
- 양쪽 집합을 정렬한 다음에는 NL 조인과 같은 방식이지만, PGA 영역에 저장한 데이터를 이용하기 때문에 빠르다.
- 소트 부하만 감수한다면, 건건이 버퍼캐시를 경유하는 NL 조인보다 빠르다.
- NL조인은 조인 컬럼에 대한 인덱스 유무에 크게 영향을 받지만, 소트 머지 조인은 영향을 받지 않는다. 양쪽 집합을 개별적으로 읽고 나서 조인을 시작한다.
해시조인
기본 메커니즘
- Build 단계: 작은 쪽 테이블을 읽어 해시 테이블을 생성한다.
- Probe 단계: 큰 쪽 테이블을 읽어 해시 테이블을 탐색하면서 조인한다.
select /*+ ordered use_hash(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000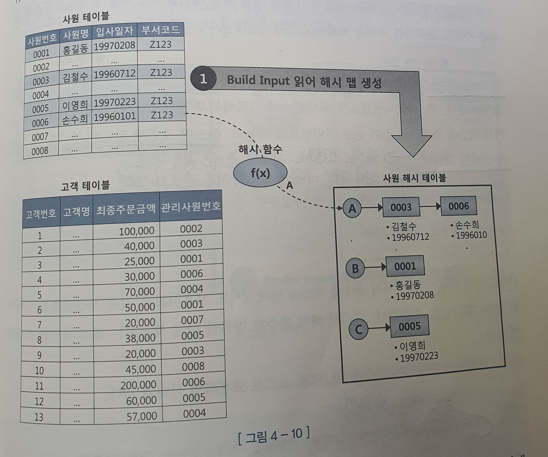
- 수행과정
- Build 단계: 아래 조건에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다. 이때, 조인컬럼인 사원번호를 해시 테이블 키 값으로 사용한다. 즉, 사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에 데이터를 연결한다. 해시 테이블은 PGA 영역에 할당된 Hash Area에 저장한다.
select
사원번호, 사원명, 입사일자,
from 사원
where e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'- Probe 단계: 아래 조건에 해당하는 고객 데이터를 하나씩 읽어 앞서 생성한 해시 테이블을 탐색한다. 즉, 관리사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인을 스캔해서 값이 같은 사원번호를 찾는다. 찾으면 조인에 성공한 것이고, 못 찾으면 실패한 것이다.
select
고객번호, 고객명, 전화번호, 최종주문금액, 관리사원번호
from 고객
where 최종주문금액 >= 20000- Build 단계에서 사용한 해시 함수를 Probe 단계에서도 사용하므로 같은 사원번호를 입력하면 같은 해시 값을 반환한다. 해시맵을 사용해서 NL조인을 처리하는 방식
해시조인이 빠른 이유
- 해시 테이블을 PGA 영역에 할당하기 때문에 NL 조인은 Outer 테이블 레코드마다 Inner 쪽 테이블을 읽기 위해 래치 획득 및 캐시버퍼 체인 스캔 과정을 반복하지만, 해시 조인은 래치 획득 과정 없이 PGA에서 빠르게 데이터를 탐색하고 조인한다.
- 해시 조인도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼캐시를 경유한다.
- 소트 머지 조인의 사전 준비작업은 양쪽 집합을 모두 정렬해서 PGA에 담는 작업이다. 두 테이블중 어느 하나가 중대형 이상이면 디스크에 쓰는 작업을 수반한다.
해시 조인의 사전 준비작업은 양쪽 집합 중 어느 한쪽을 읽어 해시 맵을 만드는 작업이다. 해시 조인은 둘 중에 작은 테이블을 해시 테이블로 Build Input으로 선택하기 때문에 상대적으로 적은 저장 공간이 필요해서 더 효율적이다. - 즉, NL조인처럼 조인 과정에서 발생하는 랜덤 액세스 부하가 없고, 소트 머지 조인 처럼 양쪽 집합을 미리 정렬하는 부하도 없다.
해시 테이블에 담기는 정보는 조인 key 뿐만 아니라 SQL에 사용한 컬럼을 모두 저장한다. 왜냐하면 테이블에 Key 값만 존재하게 된다면 조인에 성공한 Key값에 대한 나머지 정보를 읽으려면 ROWID로 다시 테이블 블록을 액세스해야 하기 때문이다.
대용량 Build Input 처리
데이터가 매우 클 경우는 어떻게 처리할까??
- 분할,정복 방식사용
- 파티션 단계
- 조인하는 양쪽 집합의 조인 컬럼에 해시 함수를 적용하고, 반환된 해시 값에 따라 동적으로 파티셔닝한다. 독립적으로 처리할 수 있는 여러개의 작은 서브 집합으로 분할 후 파티션 짝을 생성하는 단계
- 조인 단계
- 파티션 단계 완료 후 각 파티션 짝에 대해 하나씩 조인을 수행한다. 각 파티션 짝별로 작은 쪽을 Build Input으로 선택하고 해시 테이블을 생성한다.
- 해시 테이블 생성 후 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다.
- 파티션 단계
해시조인 실행계획 제어

- 위쪽 사원 데이터로 해시 테이블을 생성한 후, 아래쪽 고객 테이블에서 읽은 조인 키값으로 해시 테이블을 탐색하면서 조인한다.
select /*+ use_hash(e, c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- Build Input을 옵티마이저가 선택하는데, 일반적으로 둘 중 카디널리티가 작은 테이블을 선택한다.
select /*+ leading(e) use_hash(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- 사원 테이블을 기준으로 고객 테이블과 조인할 때 해시 조인을 사용해라.
select /*+ leading(e) use_hash(c) swap_join_inputs(c) */
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문금액
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000- swap_join_inputs 힌트로 Build Input을 명시적으로 선택
테이블이 3개 이상일 때 해시 조인
select /*+ leading(T1, T2, T3) use_hash(T2) use_hash(T3) */ *
from T1, T2, T3
where T1.key = T2.key
and T2.key = T3.key- 해시 조인에서 leading 힌트 첫 번째 파라미터로 지정한 테이블은 무조건 Build Input으로 선택된다. 첫 번재 파라미터로 T1 테이블을 지정했으므로 T2 테이블과 조인할 때는 T1이 Build Input이다.

select /*+ leading(T1, T2, T3) swap_join_inputs(T2)*/ * - T1이 Build Input으로 선택된 상황에서 T2를 Build Input으로 선택하고 싶은 경우
- 패턴 1을 패턴 2로 바꾸고 싶다면 어떻게 해야 할까?
- T3를 Build Input으로 선택하려는 것이므로
select /*+ leading(T1, T2, T3) swap_join_inputs(T3) */ * - 패턴 2를 패턴 1로 바꾸고 싶을 때
- T1과 T2 조인한 결과집합을 Build Input으로 선택하고 싶은데, 조인한 결과집합을 swap_join_inputs 힌트에 지정할 방법이 없는 경우 어떡해??
- T1과 T2 조인한 결과집합을 Build input으로 선택하는 것이 아닌 T3를 Probe Input으로 선택하는 방식
select /*+ leading(T1, T2, T3) swap_join_inputs(T3) */ *
- T1과 T2 조인한 결과집합을 Build Input으로 선택하고 싶은데, 조인한 결과집합을 swap_join_inputs 힌트에 지정할 방법이 없는 경우 어떡해??
- 서브쿼리를 이용해서 결과 집합 출력 후 해시 조인
select /*+ leading(T4) use_hash(T3) */ * from (select * from T1, T2 where T1.key = T2.key) T4, T3 where T4.key = T3.key

Build Input으로 선택하고 싶은 테이블이 조인된 결과 집합이어서 swap_join_inputs 힌트로 지정하기 어렵다면, no_swap_join_inputs 힌트로 반대쪽 Probe Input을 선택해 주면된다.
조인 메소드 선택 기준
- 소량 데이터 조인할 때 -> NL 조인
- 대량 데이터 조인할 때 -> 해시 조인
- 대량 데이터 조인인데 해시 조인으로 처리할 수 없을 때, 조인 조건식이 등치 조건이 아닐 때 -> 소트 머지 조인
- 소량과 대량의 기준??
- NL조인 기준으로 최적화했는데도 랜덤 액세스가 많아 만족할만한 성능을 낼 수 없다면, 대량 데이터 조인에 해당한다.
- 수행빈도가 매우 높은 쿼리에 대한 기준
- (최적화된) NL 조인과 해시 조인 성능이 같으면 NL 조인
- 해시 조인이 약간 더 빨라도 NL 조인
- NL 조인보다 해시 조인이 매우 빠른 경우, 해시 조인
- 조인 메소드를 선택할 때 왜 NL 조인을 가장 먼저 고려해야 할까??
- NL 조인에 사용하는 인덱스는 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조이다.
- 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조
- 해시 조인을 사용하면 좋은 3가지 조건
- 수행 빈도가 낮을 때
- 쿼리 수행 시간이 오래 걸리는
- 대량 데이터 조인할 때
Q&A
composite index - A,B,C
-> A,B만 사용하는 경우에는 인덱스를 타지만
-> B,C를 사용하는 경우에는 인덱스를 타지 않는다.
선행 컬럼 구성이면 인덱스를 사용한다.
prefetch - 불필요한 데이터도 읽어옴
-> 순서는 지키지만,
batch - 필요한 데이터만 모았다가 읽어옴
-> 디스크가 읽기 편한게 해서 순서를 지키지 않은채로 읽는다.
sort merge를 만들때나 Hash Map을 만들때
full scan을 할 것인지? 아니면 INDEX를 사용할 것인지?
소량과 대량의 기준? nl조인 기준으로 최적화 했는데 랜덤 액세스 때문에 성능 안날 때.
소량 데이터 -> nl(random access & block io), sort merge & hash (table init 작업)
대량 데이터 -> table memory 안담길 정도 크다면 nl?
해시는 파티션을 통해서 병렬적으로 메모리에 매핑이가능한데?
DIVI