소트 튜닝
5.1 소트 연산에 대한 이해
소트 연산은 메모리 집약적이고 CPU 집약적이다. 처리할 데이터량이 많을 때는 디스크 I/O까지 발생해서 쿼리 성능을 좌우하는 매우 중요한 요소이다.
5.1.1 소트 수행과정
- 소트 과정: PGA에 할당한 Sort Area => 디스크 Temp 테이블스페이스 활용
- 메모리 소트
- 전체 데이터의 정렬 작업을 메모리 내에서 완료하는 것을 의미
- 디스크 소트
- 할당받은 Sort Area 내에서 정렬을 완료하지 못해 디스크 공간까지 사용하는 경우
- 메모리 소트
- 디스크 소트 과정
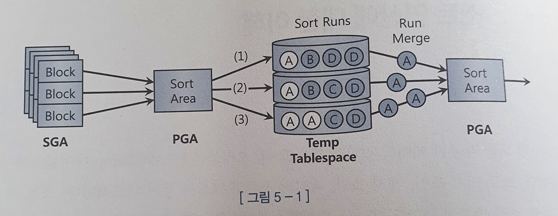
- 소트할 대상 집합을 SGA 버퍼캐시에서 읽는다.
- Sort Area에서 처리할 수 있는 양보다 데이터가 많다면 정렬된 중간집합을 Temp 테이블스페이스에 임시 세그먼트를 만들어 저장한다. => Sort Run이라고 부른다.
- 정렬된 Sort Run들을 Merge해서 PGA로 읽어들인다.
- PGA가 찰 때마다 쿼리 수행 다음 단계나 클라이언트에게 전송
- 소트 사용시 주의사항
- 소트가 발생하지 않도록 SQL 작성하는 것이 중요
- 소트가 불가피하다면 메모리내에서 수행을 완료할 수 있도록 해야한다.
5.1.2 소트 오퍼레이션
- Sort Aggregate
- 전체 로우를 대상으로 집계를 수행할 때 나타난다.
=> 실제로 데이터를 정렬하지않고 Sort Area를 사용한다는 의미 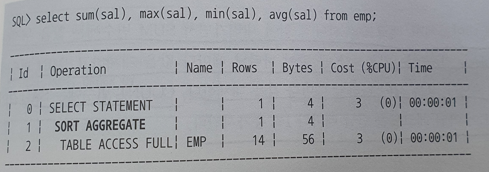
- Sort Area에 SUM, MAX, MIN, COUNT값에 대한 변수 설정
- EMP 테이블 레코드를 읽어 내려가면서 변수들 갱신
- 테이블 액세스 후 AVG는 SUM/COUNT로 값 출력
- 전체 로우를 대상으로 집계를 수행할 때 나타난다.
- Sort Order By
- sort order by는 데이터를 정렬할 때 나타나는 실행계획
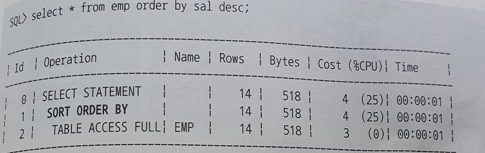
- sort order by는 데이터를 정렬할 때 나타나는 실행계획
- Sort Group By
- sort group by는 소팅 알고리즘을 사용해 그룹별 집계를 수행할 때 나타나는 실행계획
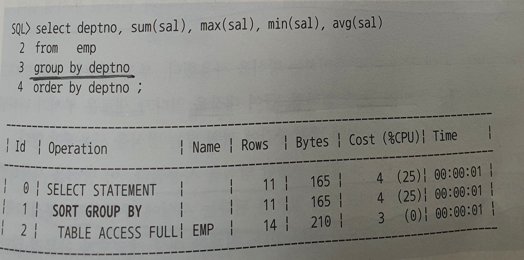
- Group By 부서번호로 틀을 만든다.
- 데이터 정보를 읽으면서 조건에 맞는 부서번호 틀에 들어있는 변수들을 갱신한다.
- 결과값을 출력한다.
- 그룹 개수가 많지 않다면 Sort Area가 클 필요가 없다.
=> 하나의 그룹(SUM, MAX, MIN, COUNT)만 있으면 되기 때문
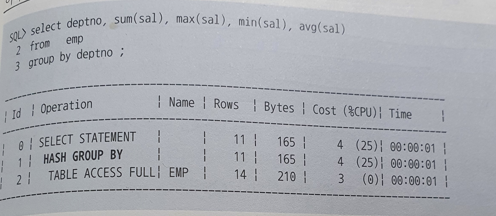
- Group By 절 뒤에 Order By절을 명시하지 않는다면 대부분 Hash Group By 방식으로 처리한다.
- Hash Group By는 Group by 컬럼의 해시 값으로 해시 버킷을 찾아 그룹별로 집계항목을 갱신하는 방식이다.
- 오라클 9i부터 그룹핑 결과가 정렬 순서를 보장하지 않음
- Sort Group by는 소팅 알고리즘을 사용해서 값을 집계한다라는 의미 이지 정렬을 의미하지는 않는다.
- 소팅 알고리즘을 사용해 그룹핑한 결과집합은 논리적인 정렬 순서를 갖는 연결리스트 구조
- 사용자가 Order By를 명시하면 오라클은 논리적 정렬 순서를 따라 값을 읽는다. => 정렬 순서가 보장
- Order By가 없다면 물리적인 순서로 읽는 것인가??
정렬된 그룹핑 결과를 얻고자 한다면 반드시 Order by를 명시하자
- sort group by는 소팅 알고리즘을 사용해 그룹별 집계를 수행할 때 나타나는 실행계획
- Sort Unique
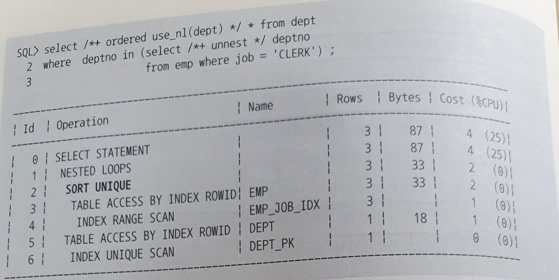
- Unnesting된 1쪽집합의 조인컬럼에 Unique 인덱스가 없거나 서브쿼리가 M쪽집합이면 메인 쿼리와 조인하기 전에 중복 레코드부터 제거해야 한다.
=> Unique 인덱스나 Unnesting된 서브쿼리의 유일성이 보장된다면 Sort Unique 오퍼레이션은 생략된다.
=> Union, Minus, Intersect 같은 집합 연산자를 사용할 때도 아래와 같이 Sort Unique 오퍼레이션이 나타난다.
- Unnesting된 1쪽집합의 조인컬럼에 Unique 인덱스가 없거나 서브쿼리가 M쪽집합이면 메인 쿼리와 조인하기 전에 중복 레코드부터 제거해야 한다.
- Sort Join
- Sort Join 오퍼레이션은 소트 머지 조인을 수행할 때 나타난다.
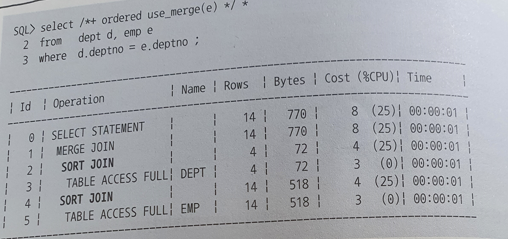
- Sort Join 오퍼레이션은 소트 머지 조인을 수행할 때 나타난다.
5.2 소트가 발생하지 않도록 SQL 작성
Union, Miuns, Distinct 연산자는 중복 레코드를 제거하기 위한 소트 연산을 발생시키므로 꼭 필요한 경우에만 사용하자.
5.2.1 Union vs Union All
-
Union을 사용하면 옵티마이저는 상단과 하단 두 집합 간 중복을 제거하려고 소트 작업을 수행
- Union 사용 예시
- 두 쿼리가 독립적이다.

- 두 쿼리가 독립적이다.
- Union 사용 예시
-
Union All은 중복을 확인하지 않고 두 집합을 단순히 결합하므로 소트 작업을 수행하지 않는다. => 대부분 Union All을 사용하는 것이 좋다.
-
Union을 사용한 해결 방법
- 중복 제거는 발생하지만 소트 작업 발생

- 중복 제거는 발생하지만 소트 작업 발생
-
Union All을 사용한 해결 방법
- 중복 제거 및 소트 작업 발생하지 않음

- 중복 제거 및 소트 작업 발생하지 않음
-
5.2.2 Exists 활용
- 중복 레코드를 제거할 때 Distinct 연산자를 사용하면 조건에 해당하는 모든 데이터를 읽어서 중복을 제거해야 한다. 부분범위 처리는 당연히 불가능하고 모든 데이터를 읽는 과정에 많은 I/O가 발생한다.
- Distinct를 사용할 때
- 계약_X2 인덱스 구성 [상품번호 + 계약일자]일 때, 아래 쿼리는 상품유형코드 조건절에 해당하는 상품에 대해 계약일자 조건 기간에 발생한 계약 데이터를 모두 읽는 비효율이 있다.

- 계약_X2 인덱스 구성 [상품번호 + 계약일자]일 때, 아래 쿼리는 상품유형코드 조건절에 해당하는 상품에 대해 계약일자 조건 기간에 발생한 계약 데이터를 모두 읽는 비효율이 있다.
- Exists를 사용할 때
- Exists 서브쿼리는 데이터 존재 여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.

- Exists 서브쿼리는 데이터 존재 여부만 확인하면 되기 때문에 조건절을 만족하는 데이터를 모두 읽지 않는다.
- Minus 연산자를 Exists 서브쿼리로 변환할 때

- Distinct를 사용할 때
5.2.3 조인 방식 변경
- 아래 SQL문에서 계약_X01 인덱스가 [지점ID + 계약일시]순이면 소트 연산을 생략할 수 있지만, 해시 조인이기 때문에 Sort Order By 사용

- NL조인 방식으로 변경
- 소트 연산 생략 및 부분범위 처리 가능한 상황에서 큰 성능 개선 효과

- 소트 연산 생략 및 부분범위 처리 가능한 상황에서 큰 성능 개선 효과

DIVI