그룹함수
합계를 구해주는 함수
SUM(숫자타입 컬럼|숫자) : 컬럼값들의 총 합계를 반환해주는 함수
컬럼값들의 합계는 한줄로 나오고, 기존 방식대로 컬럼을 SELECT하면 여러 줄이 나오는데
이때 줄 수가 맞지 않아서 에러가 발생함
그래서 GROUP BY를 이용해 SELECT한 컬럼들이 어디에 표시될지를 정해줘야함
혹은 SELECT SUM()을 단일로 써야함
이게 핵심이고 어떤함수가있는지는 대충 눈으로만 보면 됨
평균함수
AVG(숫자타입 컬럼) : 컬럼 값의 평균을 반환해주는 함수
최대/최소값 구하기
MIN(컬럼) : 최소값
MAX(컬럼) : 최대값 ||||||||| 얘네는 문자타입도 됨(사전순)
갯수세기
COUNT(*|컬럼|DISTINCT컬럼) : 행의 갯수
COUNT(*) : 테이블의 행의 갯수
COUNT(컬럼) : 널을 제외한 행의 갯수
COUNT(DISTINCT컬럼) : 중복을 제외한 행의 갯수
GROUP BY❕❗
- 그룹함수를 쓰면서 행의 갯수가 맞지 않아 오류가 발생할 때 그룹함수가 적힐 행의 기준을 만들어줌
[GROUP BY]
그룹기준을 제시할 수 있는 구문(해당 그룹별로 여러 그룹으로 묶을 수 있음)

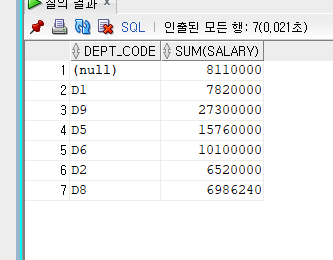
보통 SELECT할때 GROUP으로 묶어줄애(DEPT_CODE)를 같이 넣는다(눈으로 보기 좋음)
GROUP BY의 다양한 사용
-- GROUP BY 절에도 함수식 기술을 할 수 있음
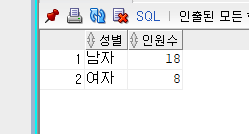
SELECT DECODE(SUBSTR(EMP_NO, 8, 1), '1', '남자', '2', '여자') 성별 , COUNT(*) 인원수
FROM EMPLOYEE
GROUP BY SUBSTR(EMP_NO, 8, 1);
-- GROUP BY 절에는 여러 컬럼 사용 가능
SELECT DEPT_CODE 부서 , JOB_CODE 직급, COUNT(*) 인원수
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE
ORDER BY DEPT_CODE, JOB_CODE NULLS FIRST;
**결과
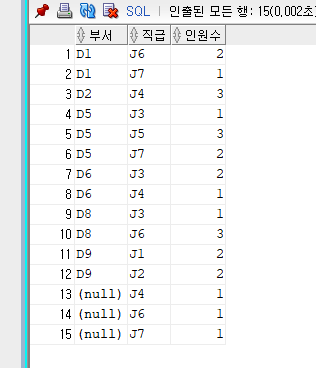
그룹바이로 여러 컬럼을 기준으로 제시할 떄는
저렇게 모든 경우의 수가 묶여 나옴
HAVING절
<HAVING 절>
그룹에 대한 조건을 나타날 때 사용
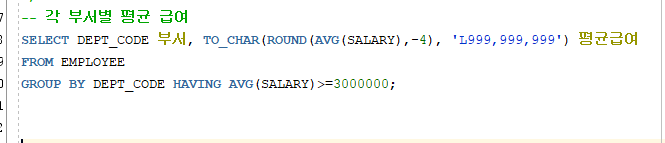
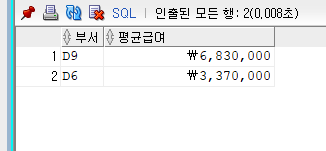
그룹으로 묶어서 기준으로 제시할 때 조건식으로 걸러내고 제시함
쿼리문 순서
<SELECT 순서>
SELECT 부서, 인원수
FROM 직원들
WHERE 직원들 중 00년도 이전 입사
GROUPBY 인원수를 체크할 그룹 기준이 부서
HAVING 부서중에서 연봉평균이 얼마이상인지
ORDERBY 나온걸 무슨 기준으로 정렬할지집계함수
<집계함수>
그룹별 산출된 결과값에 중간집계를 계산해 주는 함수
ROLLUP, CUBE
=> GROUP BY절에 기술
사용법

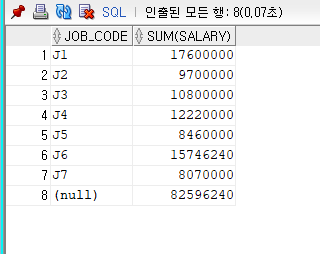
전 직원의 급여 합이 마지막 8행에 나옴
집합연산자(UNION, INTERSECT, 등등)
<집합연산자>
여러개의 쿼리문을 가지고 하나의 쿼리문을 만드는 연산자
- UNION : 합집합 | OR ==> 두 쿼리문을 수행한 결과값을 더한 후, 중복되는 값은 제거하고 반환
- INTERSECT : 교집합 | AND ==> 두 쿼리문을 수행한 결과값 중 중복되는 값만 반환
- UNION ALL : 합집합 + 교집합 ==> 두 쿼리문을 수행한 결과값에서 중복을 무시하고 전부 반환
- MINUS : 차집합 ==> 앞의 쿼리문을 수행한 값에서 뒤의 쿼리문을 수행한 결과값과
중복되는 값을 모두 제거하고 반환그냥 쿼리문 작성할 때 AND OR만 신경써서 넣어줘도 크게 필요없어보임

사용법
두개의 쿼리문 사이에 넣어주기만 하면 됨

다들 화이팅