Database
1.Interleaving 인터리빙

문제DB 인터리빙(Interleaving)에 대해 설명하시오.답변0\. 질문에 대한 답변DB 인터리빙(Interleaving)이란 다중 트랜잭션 환경에서 동시에 여러 트랜잭션의 연산들이 일정한 규칙에 따라 교차되어 실행되는 방식으로, 데이터베이스의 일관성(Consist
2.Transaction
문제트랜잭션(Transaction)에 대해 설명하시오.답변 0\. 질문에 대한 답변트랜잭션(Transaction)은 데이터베이스에서 하나의 논리적인 작업 단위를 의미하며, 데이터의 무결성과 일관성을 보장하기 위해 ACID 특성을 만족해야 한다.1\. 개념 & 핵심
3.동시성 제어 Concurrency control
문제동시성 제어 기법(Concurrency Control Technique)에 대해 설명하시오.답변 0\. 질문에 대한 답변동시성 제어 기법은 여러 트랜잭션이 동시에 데이터베이스를 조작할 때 발생할 수 있는 충돌을 방지하고, 데이터의 일관성과 무결성을 보장하기 위한
4.DB Locking
DB Locking은 데이터베이스에서 동시성 제어를 위해 사용하는 메커니즘이다.여러 트랜잭션이 동시에 같은 데이터에 접근할 때 데이터 무결성과 일관성을 보장한다.트랜잭션이 데이터에 접근할 때 Lock을 획득한다.트랜잭션이 완료(COMMIT)되거나 롤백(ROLLBACK)
5.db lock expand shrink
락(Lock) 경합 상황을 다루는 방법 중 하나야.DBMS가 락을 "얻는 과정"과 "풀어주는 과정"을 순서대로 안전하게 관리하려고 나눈 단계야.중요 포인트: 확장할 때는 락을 추가만 하고 해제는 안 함. 축소할 때는 락을 해제만 하고 추가는 안 함.즉, 락을 잡을
6.투 페이즈 커밋(Two-Phase Commit, 2PC)
투 페이즈 커밋(2PC)은 분산 환경에서 원자성(Atomicity)을 보장하기 위해 사용되는 분산 트랜잭션 프로토콜입니다. 여러 데이터베이스 노드(또는 자원 관리자)가 하나의 트랜잭션에 참여할 경우, 모든 노드가 정합성 있는 상태로 Commit 혹은 Rollback할
7.비동기 보상 트랜잭션(Asynchronous Compensation Transaction)
비동기 보상 트랜잭션(Asynchronous Compensation Transaction)은 하나의 트랜잭션을 여러 단계로 나누어 실행하고, 실패 시에는 각 단계를 되돌리는 보상 작업(Undo가 아닌 Compensation Action)을 수행하여 전체적인 정합성을 유
8.SAGA 패턴
SAGA 패턴은 분산 시스템에서 원자성을 보장하기 위한 트랜잭션 관리 방식입니다. 전통적인 2PC(투 페이즈 커밋)은 동기적이며 중앙 집중적인 방식인데 반해, SAGA는 트랜잭션을 작은 여러 개의 로컬 트랜잭션(local transaction)으로 분할하고, 실패 시
9.DB 설계 및 모델링
1\. 개요정보시스템 구축 시 데이터의 정합성과 일관성 유지, 효율적인 데이터 처리를 위해 체계적인 데이터베이스 설계 및 데이터 모델링은 필수적인 과정이다. 데이터 모델링은 요구사항 분석을 바탕으로 현실 세계의 데이터를 구조화하여 표현하는 작업이며, 데이터베이스 설계는
10.data modeling
문제 데이터 모델링의 종류와 단계별 작업에 대하여 설명하시오.답서론정보시스템의 품질은 데이터의 구조적 안정성과 무결성에 크게 의존하며, 이는 곧 효과적인 데이터 모델링에 의해 좌우된다. 데이터 모델링은 사용자의 요구사항을 기반으로 데이터 구조를 체계화하고, 이를 통해
11.NoSQL, 공간 데이터베이스, 비정형 데이터베이스, 벡터 데이터베이스
현대 데이터 환경은 정형 데이터를 넘어서 반정형, 비정형, 고차원 데이터로 확장되고 있다. 이러한 데이터는 기존 관계형 DBMS로는 저장·검색·분석에 한계가 있으며, 이를 해결하기 위해 등장한 기술이 NoSQL, 공간 데이터베이스, 비정형 DB, 벡터 DB이다. 본 문
12.BOM, Arc, Recursive relationship
BOM(Bill of Materials, 자재명세서)은 최종 제품이 어떤 부품들로 구성되어 있는지를 계층적으로 표현하는 구조입니다. BOM 관계는 이런 구성 요소 간의 관계를 계층적 Parent-Child 형태로 모델링합니다.Parent (상위 항목): 제품 또는 조립
13.개념 데이터 모델링 Conceptual Data Modeling
\*\*개념 데이터 모델링(Conceptual Data Modeling)\*\*이란,“사용자의 비즈니스 요구사항을 바탕으로 데이터의 주요 개체(엔터티), 속성, 관계를 추상적으로 정의하여 정보의 구조를 표현하는 활동”입니다.이는 데이터베이스 설계의 가장 초기 단계로,
14.논리 데이터 모델링(Logical Data Modeling)
논리 데이터 모델링(Logical Data Modeling)은 데이터베이스 설계의 핵심 단계 중 하나로, 업무의 요구사항을 바탕으로 데이터 간의 관계, 구조, 제약조건 등을 논리적으로 정의하는 과정입니다. 이는 물리적인 저장 구조와는 분리되어 있으며, 비즈니스 관점에서
15.기출 개념적 논리적 ERD 로 요구사항을 구조화 하시노
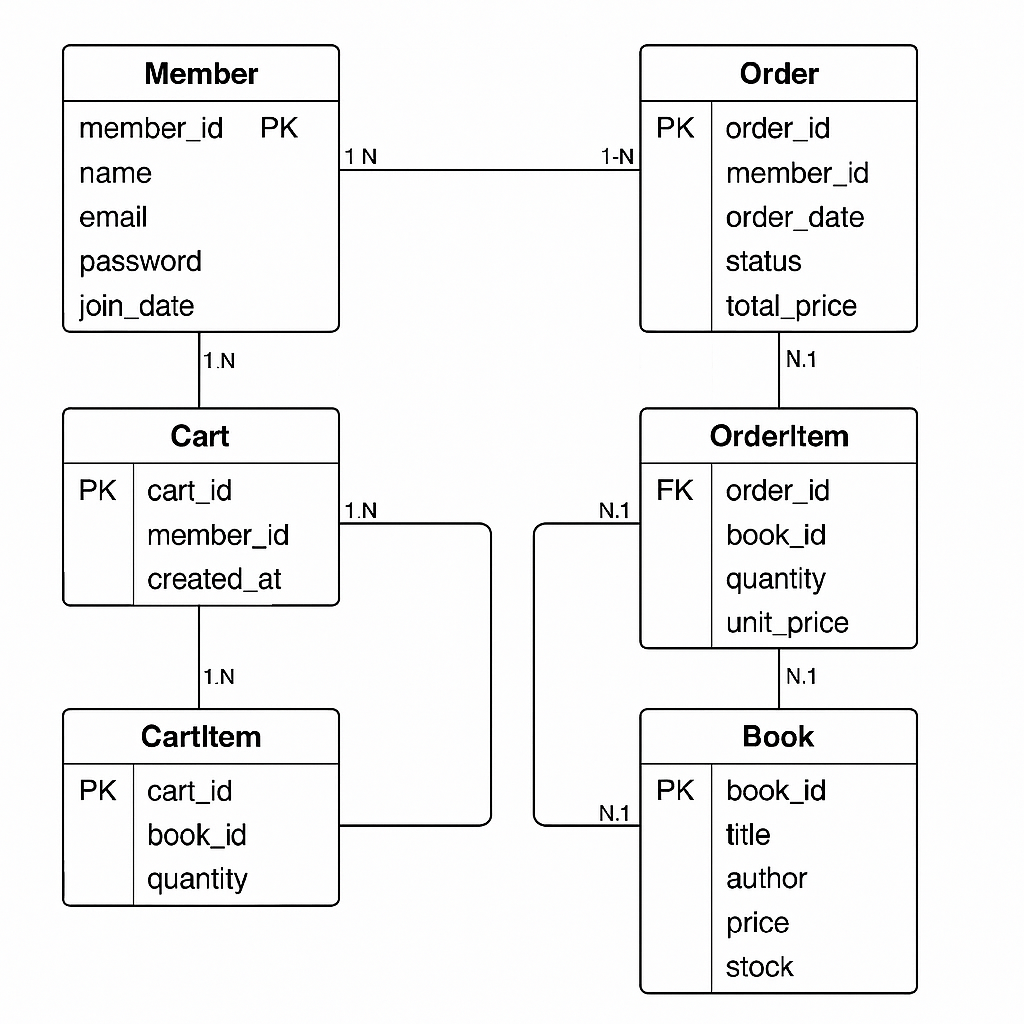
사용자는 웹사이트를 통해 도서를 검색, 장바구니에 담고 구매판매자는 도서를 등록하고 재고를 관리관리자는 회원과 주문 내역을 관리목적: 비즈니스 요구사항을 반영한 고수준 모델특징: 주체(Entity), 관계(Relationship), 속성(Attribute) 위주로 표현
16.정규화 1~3 Normalization
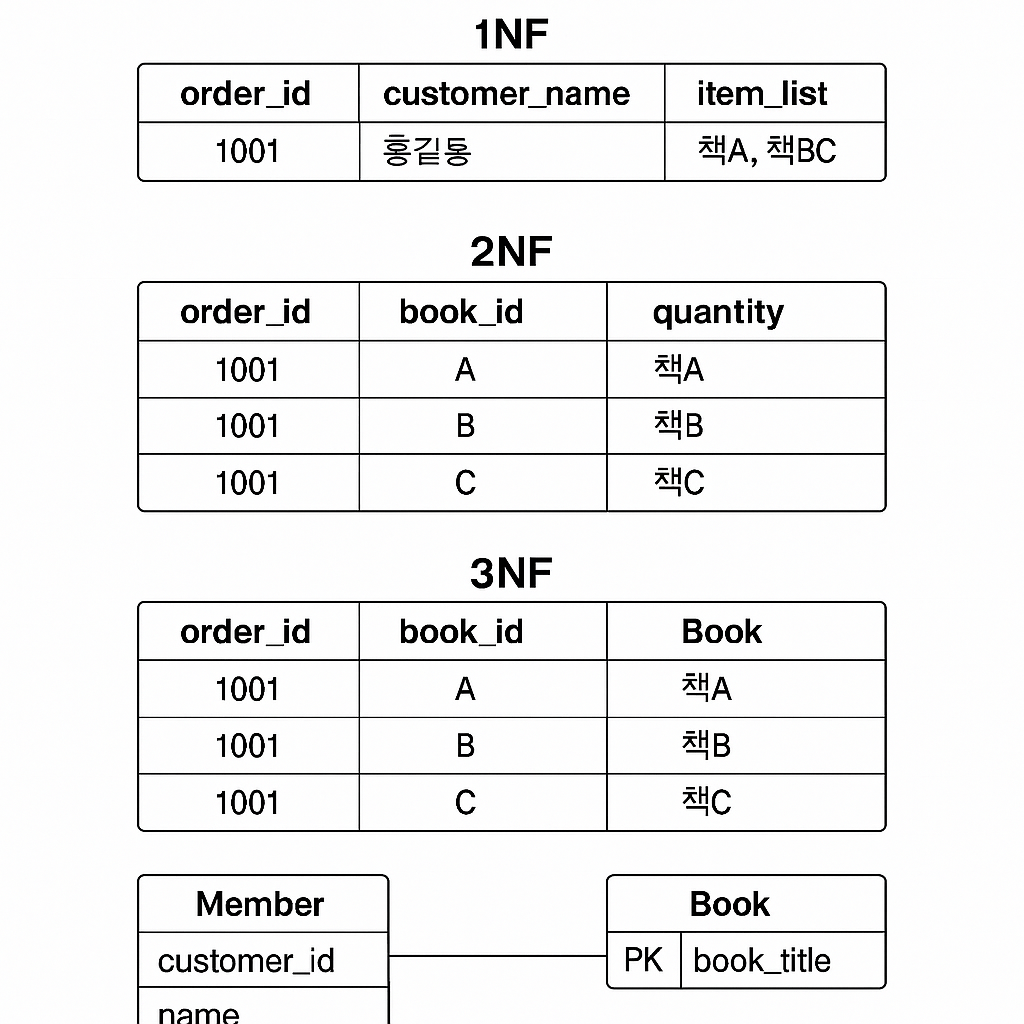
2정규형(2NF)과 3정규형(3NF)은 릴레이션 모델에서 데이터 중복 제거와 데이터 무결성 유지를 위한 핵심 정규화 단계입니다. 기술사 관점에서는 정의, 적용 조건, 예시, 효과까지 구조적으로 정리해야 합니다.속성의 원자성(Atomicity) 만족:하나의 필드는 하나의
17.물리 데이터 모델링 Physical data modeling
물리 데이터 모델링(Physical Data Modeling)은 논리 데이터 모델을 바탕으로 DBMS에 실제 구현 가능한 구조로 변환하는 과정입니다.기술사 수준에서는 성능, 저장 효율, 인덱싱, 파티셔닝, 보안 등을 고려한 현실적이고 최적화된 구조 설계가 핵심입니다.논
18.ARC 관계 Alternative Relationship Constraint
DB의 ARC 관계는 주로 개체(Entity) 간의 관계(Relationship) 를 설명할 때 사용되는 개념 중 하나로, 데이터베이스 설계(특히 E-R 다이어그램)에서 다음과 같은 맥락으로 사용됩니다. ARC는 “Alternative Relationship Const
19.업무규칙, 제약조건
조직의 업무 처리 방식, 규정, 정책을 정보 시스템에서 구현 가능하도록 정형화한 비즈니스 로직입니다.비즈니스 측면에서의 규칙으로, 데이터의 생성, 처리, 흐름, 변경 조건 등을 정의합니다.주로 요구사항 분석 단계에서 도출되며, 시스템의 행위를 제어합니다.예: 고객은 한
20.db index
인덱스(Index) 는 데이터베이스 테이블에서 데이터 검색 속도를 향상시키기 위한 보조적인 데이터 구조입니다.일반적으로 책의 목차나 색인처럼, 원하는 정보를 빠르게 찾기 위해 사용됩니다.목적: 빠른 검색, 정렬, JOIN 성능 향상단점: 저장 공간 증가, 쓰기(INSE
21.기출 foreign key
\*\*외래키(Foreign Key)\*\*는 한 테이블에서 다른 테이블의 기본키(Primary Key)를 참조하는 컬럼입니다. 외래키는 데이터베이스에서 테이블 간의 관계를 설정하는 중요한 요소로, 데이터의 무결성을 유지하는 데 사용됩니다.외래키의 주요 목적은 관계형
22.ER Model 유도, 복합 속성
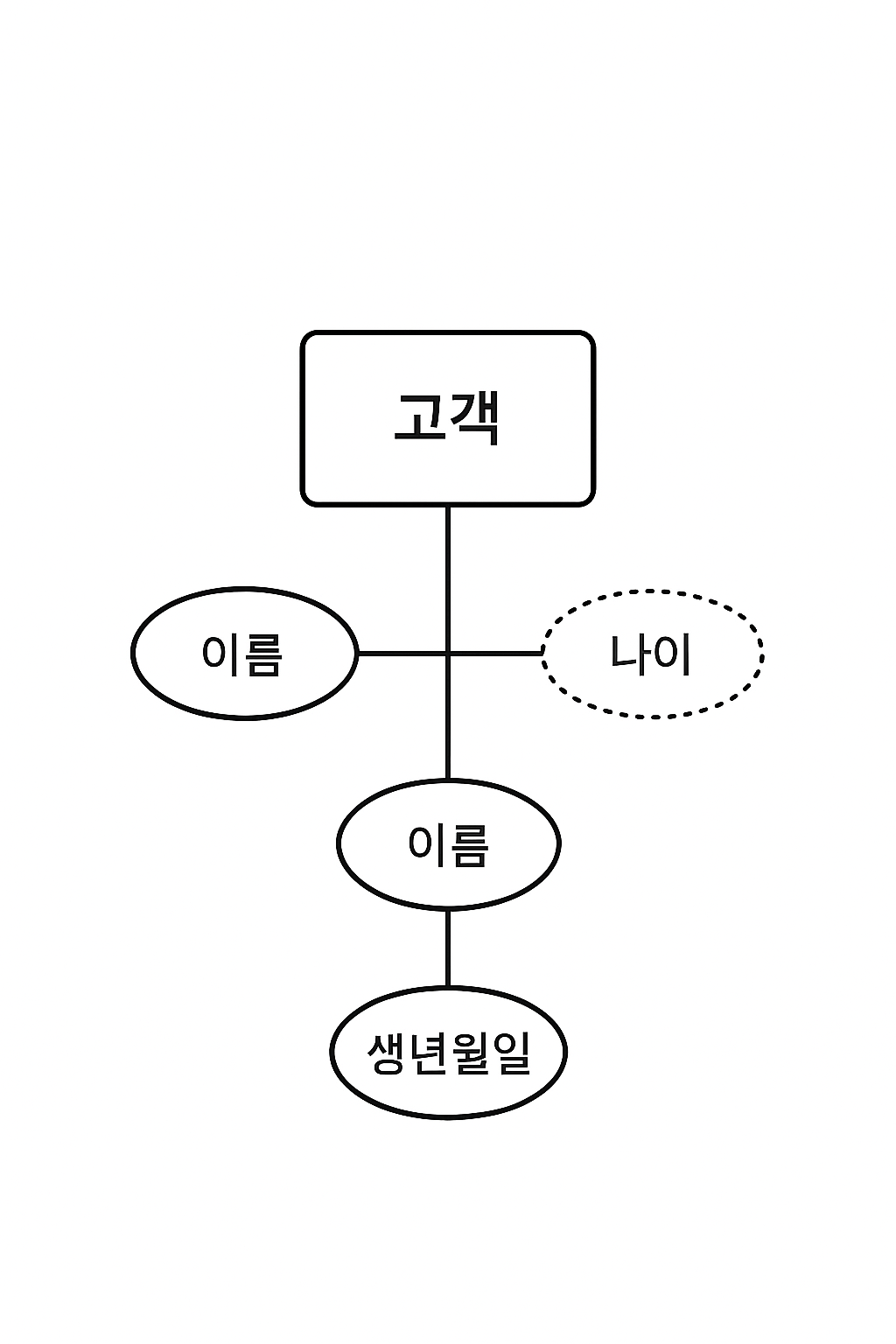
ER 모델(Entity-Relationship Model)에서 \*\*유도 속성(Derived Attribute)\*\*과 \*\*복합 속성(Composite Attribute)\*\*은 속성(Attribute)의 세부 분류에 해당합니다. 개체(Entity)나 관계(R
23.카디널리티(Cardinality)
\*\*카디널리티(Cardinality)\*\*는 상황에 따라 약간 다른 의미로 사용되지만, 공통적으로 "어떤 대상의 개수" 또는 \*\*"몇 번 연결되거나 발생하는가"\*\*를 나타내는 개념입니다.ER(Entity-Relationship) 모델에서 카디널리티는 \*\
24.ER Model Unary, Binary, Ternary 관계
ER 모델에서 \*\*관계(Relationship)\*\*는 개체(Entity)들 간의 연관성을 표현합니다. 이 관계는 참여하는 개체의 수에 따라 단항(Unary), 이항(Binary), 삼항(Ternary) 관계로 나뉩니다. 각 관계 유형은 데이터 모델링에서 구조와
25.기출 ERD 첸표기법
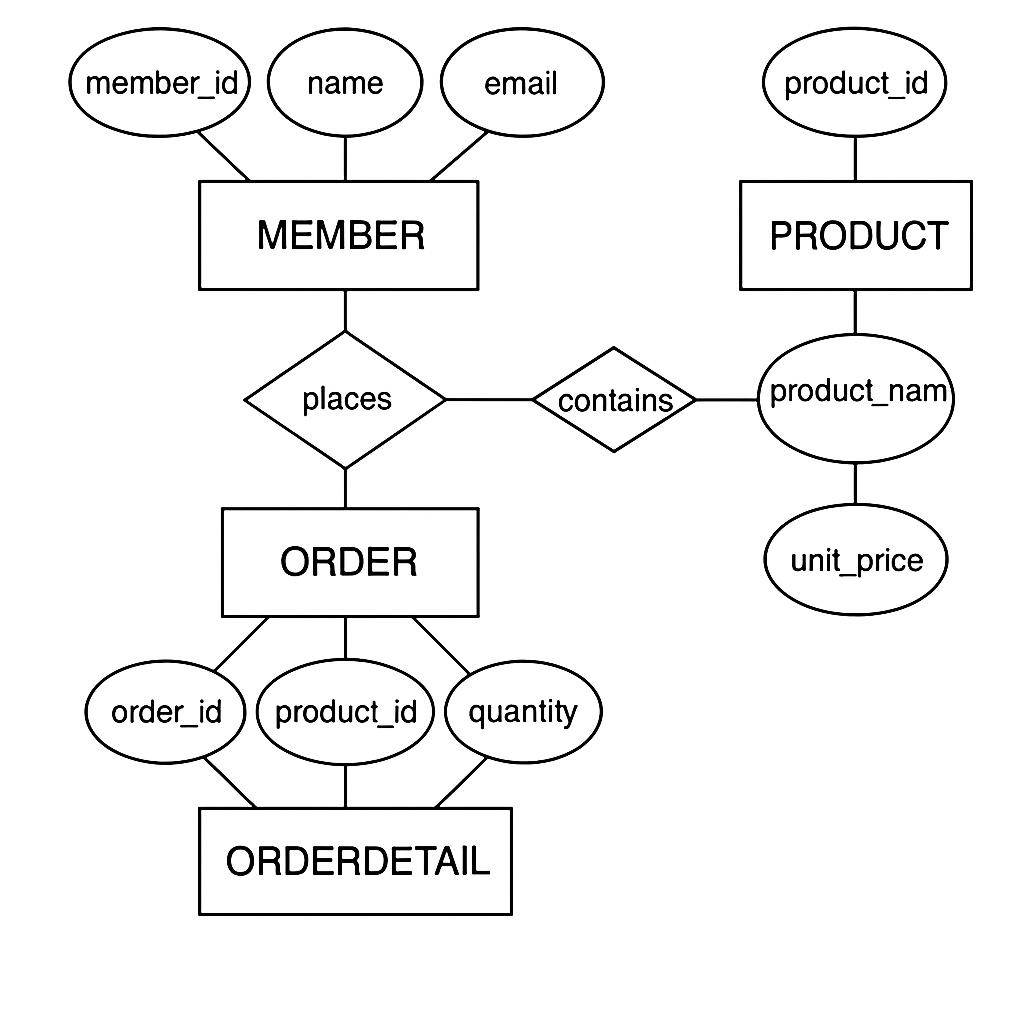
개념적 ERD는 업무 개념 중심의 단순한 구조로, 엔터티 간 관계를 식별하는 수준입니다.회원(Member): 회원ID, 이름, 이메일 등주문(Order): 주문ID, 주문일, 총금액제품(Product): 제품ID, 제품명, 단가회원은 주문을 한다 (1\\:N)→ 한 명
26.기출 반정규화 Denormalization
반정규화(Denormalization)는 정규화된 데이터 모델에서 성능 향상을 목적으로 의도적으로 중복을 허용하거나 정규화 수준을 낮추는 과정입니다. 즉, 정규화로 인해 생긴 성능 저하 문제를 해결하기 위해 데이터 구조를 다시 조정하는 것입니다.반정규화는 데이터 무결성
27.조인 join operation
조인
28.옵티마이저(Optimizer), 실행 계획(Execution Plan)
옵티마이저는 SQL 질의를 가장 빠르고 효율적으로 실행하기 위한 최적의 실행 계획을 선택하는 DBMS의 핵심 컴포넌트입니다.사용자가 작성한 SQL은 논리적 질의일 뿐이며,DBMS는 이를 실제 물리적 연산으로 변환해 실행해야 합니다.이 과정에서 여러 가능한 실행 계획 중