[SQL 코호트 분석] 2. 리텐션 분석 실습 (1)
SQL Data Analysis
1. 리텐션 분석 (retention analysis)
1-1. 개념
대표적인 코호트 분석 방법 중 하나로 무언가 계속 유지되는 현상에 대한 분석 방법이다.
예를 들어, 다음과 같은 경우 리텐션 분석을 적용할 수 있다.
- 기존 고객이 계속 상품을 구매하거나 서비스를 이용하는지
- 새로운 직원 고용은 비용이 들기에 기존 직원이 유지되는지
- 한 번 선출된 의원이 연임을 하는지
1-2. 분석 포인트
- 코호트 크기(구독자 수, 직원 수, 소비 금액)등이 시간이 흐를수록 유지, 감소, 증가하는지 확인해야 한다.
- 증가, 감소한다면 변화 정도와 속도를 확인해야 한다.
- 보통 코호트는 시간이 지날수록 감소한다.
코호트(집단)는 시작 날짜를 기준으로 한 번 정해지면 추가되지 않는다.
- 코호트의 크기가 감소하더라도 코호트의 수익은 증가할 수 있다.
이탈한 고객이 있더라도 고객이 더 많은 소비를 한다면 전체 수익이 증가할 수 있다.
1-3. 분석 방법
-
데이터셋의 시작 날짜부터 구간별로
count함수를 이용해 개체 수를 계산한다. -
sum함수를 이용해 고객이 사용한 금액의 합계, 고객의 행동 수를 계산한다.위 값을 정규화하기 위해 (각 구간의 값/첫 구간의 값) 으로 첫 구간의 리텐션 값이 100%이 되고, 이후 구간은 첫 구간 대비 비율로 나타난다.
-
개체 수 리텐션은 유지 or 감소가 가능하지만 100% 초과는 불가능하다. (코호트는 한 번 정해지면 추가되지 않으므로)
-
수익 리텐션, 행동 수 리텐션은 증가하기도 한다.
1-4. 리텐션 커브 분석 방법
리텐션 분석 결과는 보통 "리텐션 커브 (retention curve)"로 표현한다.
리텐션 커브의 양상은 2가지 관점에서 분석한다.
1) 처음 몇 구간 내 리텐션 커브 양상
: 코호트별로 리텐션 커브에 차이가 있다면 원인을 분석한다.
2) 처음 몇 구간 이후 리텐션 커브 양상
: 평평하게 유지되는지 or 0이 될 때까지 계속해서 감소하는지 분석한다.
이탈했던 개체가 다시 활동하는 경우 리텐션 커브는 떨어졌다가 다시 상승하는 "스마일 커브" 형태를 보일 수 있다.
2. SQL을 활용한 리텐션 계산
- 코호트 멤버: 의원
- 시계열 데이터: 각 의원의 임기
- 집계 연산: 시작 날짜부터 구간별로 재임 중인 의원 수
2-1. 각 의원별 임기 시작 날짜
select id_bioguide, -- 의원 ID
min(term_start) as first_term -- 첫 임기 시작 날짜
from legislators_terms
group by id_bioguide -- 각 의원별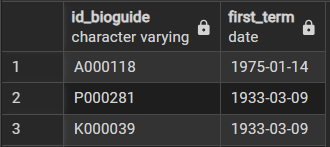
2-2. 구간별로 재임 중인 의원 수
2-1에서의 의원별 임기 시작 날짜를 서브쿼리로 셀프조인을 수행한다.
select date_part('year', age(b.term_start, a.first_term)) as period,
count(distinct a.id_bioguide) as cohort_retained -- 구간별 재임 중인 의원 수
from
( -- 의원별 첫 임기 시작일을 찾는 서브쿼리
select id_bioguide,
min(term_start) as first_term
from legislators_terms
group by id_bioguide
) as a
join legislators_terms as b on a.id_bioguide = b.id_bioguide
group by 1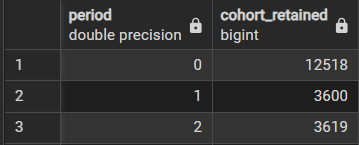
시계열 데이터가 생성되었다.
SQL문을 자세히 설명하면 아래와 같다.
1) date_part('year', age(b.term_start, a.first_term))
- 예시 데이터
의원이 총 3번 임기를 했다고 가정하면, legislators_terms 테이블의 원본 데이터는 다음과 같다.

- id_bioguide: 입법자의 고유 ID.
- term_start: 해당 임기의 시작 날짜.
- 여기서 입법자 A는 2000년, 2002년, 2004년에 임기를 가졌다.
- 첫 임기(a.first_term) 추출
서브쿼리에서 각 의원의 첫 임기를 추출한다.
select id_bioguide,
min(term_start) as first_term
from legislators_terms
group by id_bioguide- min 함수를 이용해 각 의원의 첫 임기를 찾는다.

- 첫 임기와 모든 임기 비교
이제 서브쿼리에서 구한 first_term을 원본 데이터와 셀프 조인한다.
join legislators_terms b on a.id_bioguide = b.id_bioguide- 이 조인을 통해 각 의원의 첫 임기와 모든 임기를 비교할 수 있다.

- 특정 임기(b.term_start)와 첫 임기(a.first_term) 비교
age 함수를 이용해 첫 임기와 모든 임기의 연도 차이를 계산한다.
date_part('year', age(b.term_start, a.first_term)) as periods
결과적으로 periods는?
0: 의원의 첫 임기
2: 첫 임기로부터 2년 이후 재 임기
4: 첫 임기로부터 4년 이후 재 임기
※ age 함수 인자 순서
age(date1, date2)의 결과는 date1 - date2로 계산된다.
- 첫 번째 인자 (date1): 기준이 되는 더 최근 날짜.
- 두 번째 인자 (date2): 빼는 대상이 되는 더 과거 날짜.
- 결론
- 각 의원의 모든 임기는 여러 행으로 표현된다.
- 각 의원마다 first_term은 동일하지만, 각 행의 term_start가 다르기 때문에 연도 차이(periods)가 각각 계산된다.
2) count(distinct a.id_bioguide) as cohort_retained
group by 1 즉, group by period를 통해 첫 임기 시작일 이후로 다시 임기를 하는 의원의 수를 카운트하게 된다.
이때, 첫 임기 시작일로부터 2년 이후 임기를 다시 한 의원 수, 4년 이후 임기를 다시 한 의원 수 등 period라는 구간을 기준으로 하게 된다.
2-3. 구간별로 재임 중인 의원의 비율
2-1, 2-2에서 쿼리를 서브쿼리로 하여 구간별 재임 중인 의원의 비율을 구한다.
cohort_retained 값을 cohort_size로 나누어 "첫 구간 대비 구간별 코호트 크기 비율"을 계산한다.
select period,
first_value(cohort_retained) over (order by period) as cohort_size,
cohort_retained,
cohort_retained * 1.0 /
first_value(cohort_retained) over (order by period) as pct_retained
from(
select date_part('year', age(b.term_start, a.first_term)) as period,
count(distinct a.id_bioguide) as cohort_retained
from
(
select id_bioguide,
min(term_start) as first_term
from legislators_terms
group by id_bioguide
) as a
join legislators_terms as b on a.id_bioguide = b.id_bioguide
group by 1
) aa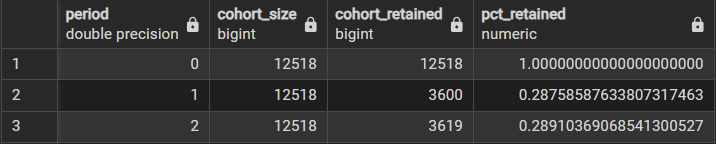
1) first_value(cohort_retained) over (order by period) as cohort_size
윈도우 함수에 대한 기본 개념을 다시 살펴보자.
※ 윈도우 함수
데이터의 특정 범위(윈도우)에 대해 계산을 수행하고, 그 결과를 각 행에 반환하는 함수-- 기본구조 <윈도우 함수>(컬럼) OVER ( [PARTITION BY <그룹 기준>] [ORDER BY <정렬 기준>] )
- 윈도우 함수: 수행할 계산 (ex: SUM, AVG, ROW_NUMBER)
- OVER: 윈도우 함수를 사용할 영역을 정의
- PARTITION BY (선택 사항): 데이터를 그룹화할 기준(옵션)
- ORDER BY (선택 사항): 계산할 데이터의 정렬 기준
ex) 부서별 급여 합계를 계산하는 방식에서 일반 집계 함수와 윈도우 함수의 차이
- 일반 집계 함수: 부서별로 묶여 급여 합계만 나타나고, 개별 행(직원 정보)는 사라진다.
select department, sum(salary) from employees group by department;
- 윈도우 함수: 개별 행(직원 정보)에 소속 부서별 급여 합계가 반복되어 추가로 표시된다.
select department, name, salary, sum(salary) over (partition by department) from employees;


내부 쿼리에서 반환된 데이터는 아래와 같은 형태가 될 것이다.
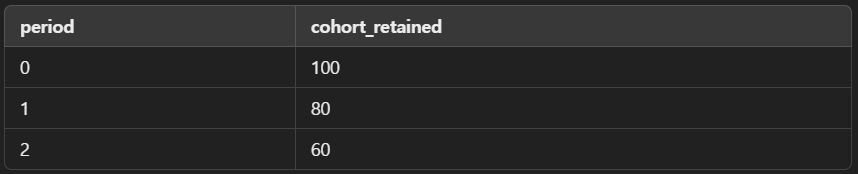
first_value(cohort_retained) over (order by period) as cohort_size윈도우 함수 중 하나인 first_value는
- period를 기준으로 데이터를 정렬한 데이터에서 첫 번째 행의
- cohort_retained 값을 반환하게 된다.

period를 기준으로 데이터를 정렬하면 period=0 이 첫 행이 된다.
따라서, period=0에서의 cohort_retained 값인 100이 모든 행에 새로운 열로 생성된다.
이것을 "첫 period에서 cohort_retained를 고정 참조"했다고 한다.
2) cohort_retained * 1.0 / first_value(cohort_retained) over (order by period) as pct_retained
유지율은 <현재 남아 있는 인원/초기 cohort 크기> 로 계산된다.
유지율을 계산하기 위해서 바로 전 단계에서 cohort_size를 각각 행에 추가해준 것이다.

2-4. 코호트 리텐션 분석 결과 피벗 테이블로 보기
case문과 집계 함수를 이용해 결과 데이터를 피벗한다.
select cohort_size,
max(case when period=0 then pct_retained end) as yr0,
max(case when period=1 then pct_retained end) as yr1,
max(case when period=2 then pct_retained end) as yr2,
max(case when period=3 then pct_retained end) as yr3,
max(case when period=4 then pct_retained end) as yr4
from (
select period,
first_value(cohort_retained) over (order by period) as cohort_size,
cohort_retained,
cohort_retained * 1.0 /
first_value(cohort_retained) over (order by period) as pct_retained
from (
select date_part('year', age(b.term_start, a.first_term)) as period,
count(distinct a.id_bioguide) as cohort_retained
from (
select id_bioguide,
min(term_start) as first_term
from legislators_terms
group by id_bioguide
) as a
join legislators_terms as b on a.id_bioguide = b.id_bioguide
group by 1
) as aa
) as aaa
group by 1
리텐션 분석 결과 비율이 매우 낮을 뿐 아니라 리텐션 비율이 들쑥날쑥하다.
하원의원이 임기는 2년, 상원의원의 임기는 6년이다. 그러나 데이터셋에서 시작 날짜만 이용했으므로, 각 의원이 의원직 수행 경험이 있더라도 임기가 2년이었는지 혹은 6년이었는지 알 수 없다.
➡️ 2년 또는 6년 주기에 맞춰 분석을 수행하거나, 결측 데이터를 보간한다.
1) max(case when period=0 then pct_retained end) as yr0
✅ max 함수를 써야하는 이유?
- 외부쿼리의 마지막에 group by를 사용했다. group by는 같은 cohort_size에 해당하는 여러 행을 하나로 묶는 역할을 하게 된다.
- 그런데 이때 그룹 내에서 어떤 값을 사용할 것인지 정해주어야 한다.
- max, min, avg 등이 "대표 값을 뽑아내는 기준"이 될 수 있다.
✅ max, min, avg 등이 같은 결과를 주는 이유?
- cohort_size별로 그룹화를 하게 되면, period=0, period=1... 등 period별로 하나의 값만 남게 된다.
- case when period=0 then pct_retained end는 period=0일 때만 값을 반환한다. 그리고 그룹별로 period=0인 행은 딱 하나 있다.
- 따라서, min, max, avg 등 함수 종류에 관계없이 하나뿐인 값이 출력된다.
📌 더 쉽게 정리하면 다음과 같다.
1. group by를 쓰고자 한다면, 그룹에서 값을 하나만 뽑아야 한다.
2. max, min, avg 같은 집계 함수를 써서 그룹별로 사용할 하나의 값을 지정한다.
2) from 절에서 a, aa, aaa 별칭을 지정하는 이유
- 서브쿼리는 하나의 임시 테이블로 간주된다.
- 임시 테이블 참조를 위해 별칭을 반드시 지정해야 한다.
이어서, 2년 또는 6년 주기에 맞춘 리텐션 분석 방법을 알아보자.
[SQL 코호트 분석] 1. 기본 개념
⬆️ 이전 글
⬇️ 다음 글
[SQL 코호트 분석] 2. 리텐션 분석 정확도 향상 실습 (2)
💡 질문과 피드백 사항은 댓글에 편하게 남겨주시기 바랍니다.
❤️ 도움이 되셨다면 공감 부탁드립니다.
