[DE kit] 1. 데이터 팀의 역할, Redshift 개요
데이터 엔지니어가 알아야 할 기술
SQL
Python
Airflow
ETL/ELT 관리도구 Airflow
- ETL : 바깥에서 데이터 가져오기 -> 데이터 엔지니어의 역할
- ELT : 내부 데이터를 재조합하기
AWS
프로덕션 데이터베이스는 mysql postgre 등을 사용, 서비스 운영에 필요한 필수적인 데이터 저장 (회원정보, 상품정보)
-> 처리속도 등이 중요, 용량이 작기 때문에 쿼리를 날리면 터지기 쉽다. 사용자:서비스 고객, OLTP(Transaction:물건 구매 등)
데이터 웨어하우스는 데이터 분석만을 위한 별개의 DB, 큰 데이터 처리 가능
-> 사용자:내부 데이터 과학자, 분석가, 마케터 등, 속도보다 큰 데이터 처리가 중요 OLAP(Analytical:분석을 위한 처리)
summary table = data mart
데이터 웨어하우스 중 Redshift
- AWS에서 제공하는 데이터 웨어하우스 솔루션, sql 엔진
- 최대 2 PB 까지 제공
- olap
- columnar storage : 레코드별로 데이터를 저장하는 것이 아닌 컬럼으로 나누어 저장/ 컬럼별 특성을 사용해서 압축이 쉬워지고/새로운 컬럼 추가 삭제가 쉬움, 대부분의 규모가 큰 데이터베이스들은 컬럼널 스토리지를 사용한다.
- bulk update : insert into를 반복하는 대신 레코드가 들어간 파일을 생성하고 파일을 aws 스토리지 s3에 업로드하고 테이블로 벌크 업데이트를 하면 시간이 훨씬 빠르다. 바이너리 포맷을 많이 사용
- 고정비용, 가변비용 옵션도 새로 생김
- primary key 유니크를 보장하지 않는다. 엔지니어, 분석가의 역량
- postgresql 8.x와 호환된다.
- AWS의 다른 서비스와 연동이 쉽다.
서버 사양을 높이는 것을 scale up이라 한다. ex) dc2.large -> dc2.8xlarge
서버 추가 : scale out
고정비용을 쓸 경우 서버에 테이블 분산 시 개발자가 정해줘야 하는 점이 문제, 테이블의 레코드가 한 노드에 몰려서 속도가 느려지는 경우가 발생
snowflake가 가장 좋은 솔루션
log -> s3 -> Athena -> Redshift
Athena는 비구조화된 s3의 데이터를 구조화해서 redshift에 적재 or S3에 다시 적재 등
log -> S3 : ETL
s3 -> redshift : ELT로 보기도 한다.
Redshift Access
- 대시보드 툴 : 태블로, 루커
- JDBC, ODBC 툴 : python의 경우 psycopg2라는 라이브러리 사용

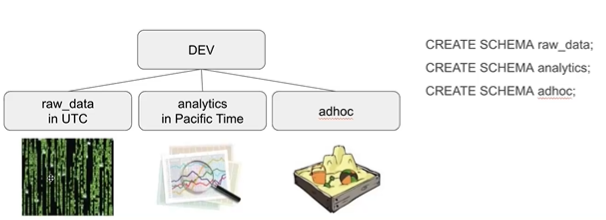
raw데이터로 새로운 테이블 = analytics
adhoc = 테스트용
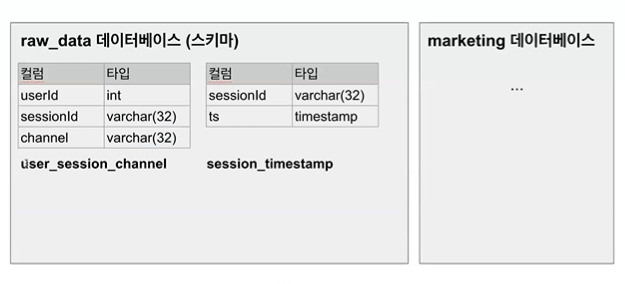
내 아이디 테이블

방문 = 시간으로 나누기 30분간 활동 없으면 세션 닫기 / 자정을 넘어갈 때 무조건 세션 닫고 새로 열기, 계속 쓰더라도 광고나 링크를 보고 외부에서 재방문한 경우 세션 새로 열기 -> GA방법
트래픽 소스 분석을 하기 위해
알고 있는 곳을 찾아가거나 링크를 클릭하거나, 어디에서 우리 사이트를 발견했는지 기록이 되어야 하고 어떤 채널에서 어떤 링크를 타고 왔는지 기록을 해서 기여도 분석을 할 수 있게 된다.
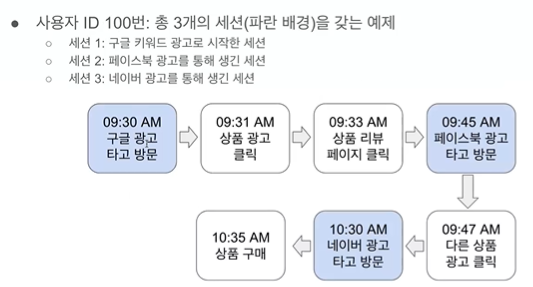
30분이 지나지 않았지만 새 세션이 열린다. 외부에서 링크를 타고 들어와서
각 세션마다 세션을 만들어주게 한 터치 포인트(구글, 페이스북, 네이버)채널을 알 수 있으면 무슨 행동을 하느냐에 따라 채널에 크레딧을 줄 수 있다. 상품 구매를 하게 만든 세션은 3번, 3번을 만든 광고는 네이버 광고, 네이버 광고에 크레딧을 다 주면 last touch
first touch, multi touch, last touch
1주차 sql 실습 ipynb에 mau 계산해서 제출하기
