pandas-profile로 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)
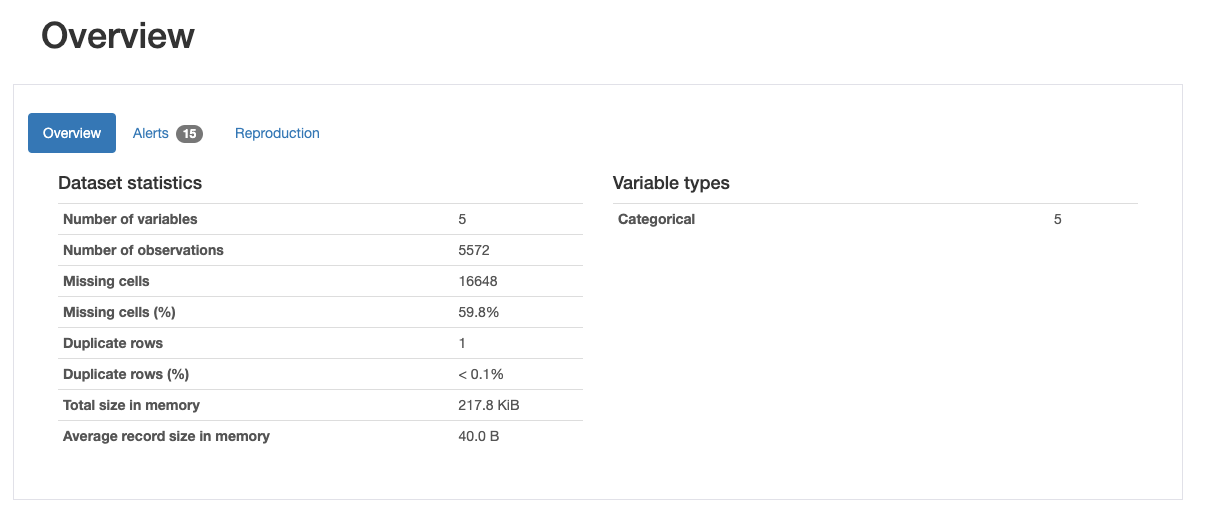
행(데이터 개수): 5572개
열: 5
5572*5개의 cell중에 59.8%가 결측값
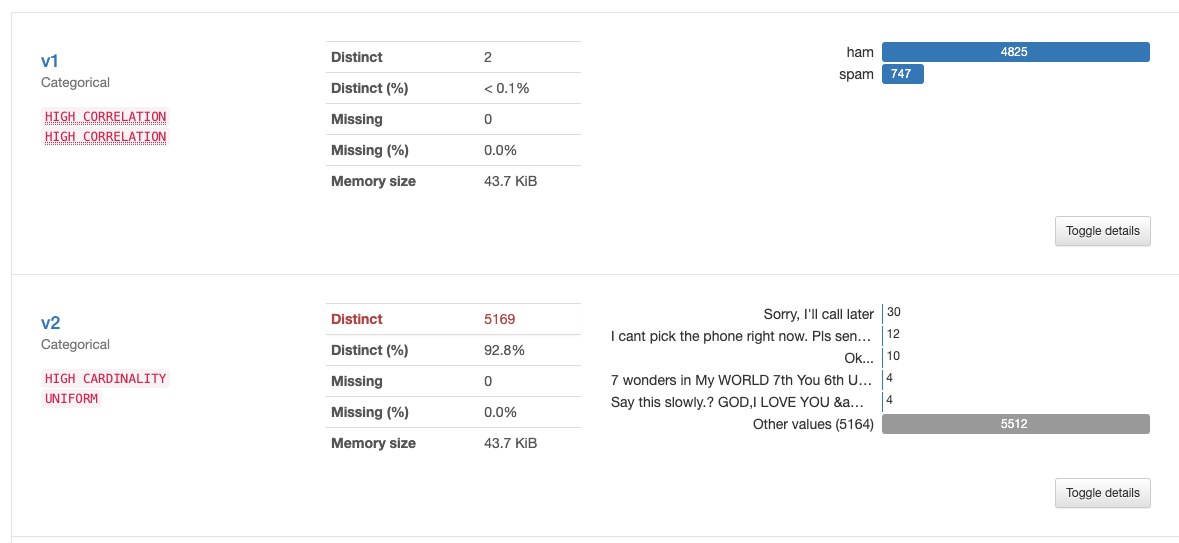
v2는 5169개의 중복되지 않은 값을 가지고 있다
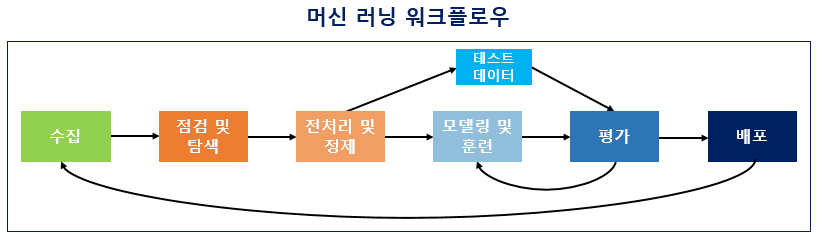
1) 수집(Acquisition)
머신 러닝을 하기 위해서는 기계에 학습시켜야 할 데이터가 필요합니다. 자연어 처리의 경우, 자연어 데이터를 말뭉치 또는 코퍼스(corpus)라고 부르는데 코퍼스의 의미를 풀이하면, 조사나 연구 목적에 의해서 특정 도메인으로부터 수집된 텍스트 집합을 말합니다. 텍스트 데이터의 파일 형식은 txt 파일, csv 파일, xml 파일 등 다양하며 그 출처도 음성 데이터, 웹 수집기를 통해 수집된 데이터, 영화 리뷰 등 다양합니다.
자연어 처리라면 토큰화, 정제, 정규화, 불용어 제거 등의 단계를 포함합니다. 빠르고 정확한 데이터 전처리를 하기 위해서는 사용하고 있는 툴(이 책에서는 파이썬)에 대한 다양한 라이브러리에 대한 지식이 필요합니다. 정말 까다로운 전처리의 경우에는 전처리 과정에서 머신 러닝이 사용되기도 합니다.

여기서 주의해야 할 점은 대부분의 경우에서 모든 데이터를 기계에게 학습시켜서는 안 된다는 점입니다. 뒤의 실습에서 보게되겠지만 데이터 중 일부는 테스트용으로 남겨두고 훈련용 데이터만 훈련에 사용해야 합니다. 그래야만 기계가 학습을 하고나서, 테스트용 데이터를 통해서 현재 성능이 얼마나 되는지를 측정할 수 있으며 과적합(overfitting) 상황을 막을 수 있습니다. 사실 최선은 훈련용, 테스트용으로 두 가지만 나누는 것보다는 훈련용, 검증용, 테스트용. 데이터를 이렇게 세 가지로 나누고 훈련용 데이터만 훈련에 사용하는 것입니다.
토큰화: corpus에서 토큰이라 불리는 단위로 나누는 작업.
단어 토큰화
토큰의 기준을 단어로 하는 경우.
보통 토큰화 작업은 단순히 구두점이나 특수문자를 전부 제거하는 정제(cleaning) 작업을 수행하는 것만으로 해결되지 않습니다. 구두점이나 특수문자를 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생하기도 합니다. 심지어 띄어쓰기 단위로 자르면 사실상 단어 토큰이 구분되는 영어와 달리, 한국어는 띄어쓰기만으로는 단어 토큰을 구분하기 어렵습니다.
- 정제(cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다.
- 정규화(normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만들어준다.
정제 작업은 토큰화 작업에 방해가 되는 부분들을 배제시키고 토큰화 작업을 수행하기 위해서 토큰화 작업보다 앞서 이루어지기도 하지만, 토큰화 작업 이후에도 여전히 남아있는 노이즈들을 제거하기위해 지속적으로 이루어지기도 합니다. 사실 완벽한 정제 작업은 어려운 편이라서, 대부분의 경우 이 정도면 됐다.라는 일종의 합의점을 찾기도 합니다.
언어모델
- 통계를 이용한 방법 : N-gram
- 인공 신경망을 이용한 방법: GPT,BERT
