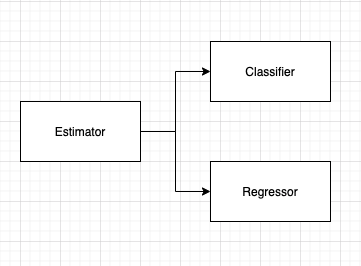
Estimator
- 학습:
fit() - 예측:
predict()
Classifier(분류)
분류 구현 클래스
- DecisionTreeClassifier
- RandomForestClassifier
- GradientBoostingClassifier
- ...
Regressor(회귀)
회귀 구현 클래스
- LinearRegression
- Ridge
- Lasso
- ...
사이킷런 주요 모듈
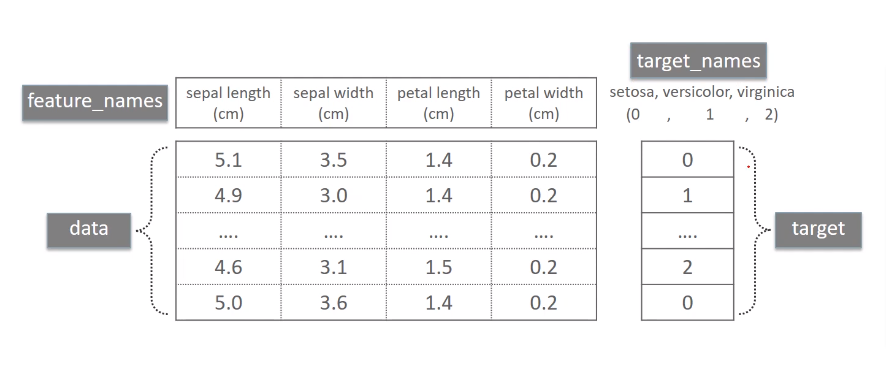
내장 toy dataset

데이터 셋 구성
- feature_names: 피처 이름
- data: 피처값(numpy.ndarray)
- target_names: 타켓의 번호에 해당되는 이름(numpy.ndarray)
- target: 타겟값(numpy.ndarray)
keys = iris_data.keys()
# dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
print(iris_data.feature_names)
print(iris_data.target_names)
print(iris_data.data)
print(iris_data.target)학습 데이터와 테스트 데이터의 분리
train_test_split(
*arrays,
test_size=None, # 전체 데이터중 test_size만큼을 테스트 데이터 셋으로 만들어라(default = 0.25)
train_size=None,
random_state=None, # 호출할 때마다 동일한 데이터 세트를 생성하기 위해 주어지는 난수 값
shuffle=True, # 데이터를 분리하기 전에 미리 섞을지 결정
stratify=None,
)넘파이 ndarray 뿐만 아니라 판다스 DataFrame/Series도 train_test_split( )으로 분할 가능하다
import pandas as pd
iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)
iris_df['target']=iris_data.target
ftr_df = iris_df.iloc[:, :-1]
tgt_df = iris_df.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(ftr_df, tgt_df,
test_size=0.3, random_state=121)